
Elena Rastorgueva
389 posts
Elena Rastorgueva
@ElenaRas_
Speech AI @NVIDIA | Cambridge MEng | Learning 中文 (B1 level) | Opinions my own
🇬🇧 → SF Bay Area Katılım Temmuz 2016
1.5K Takip Edilen1.2K Takipçiler

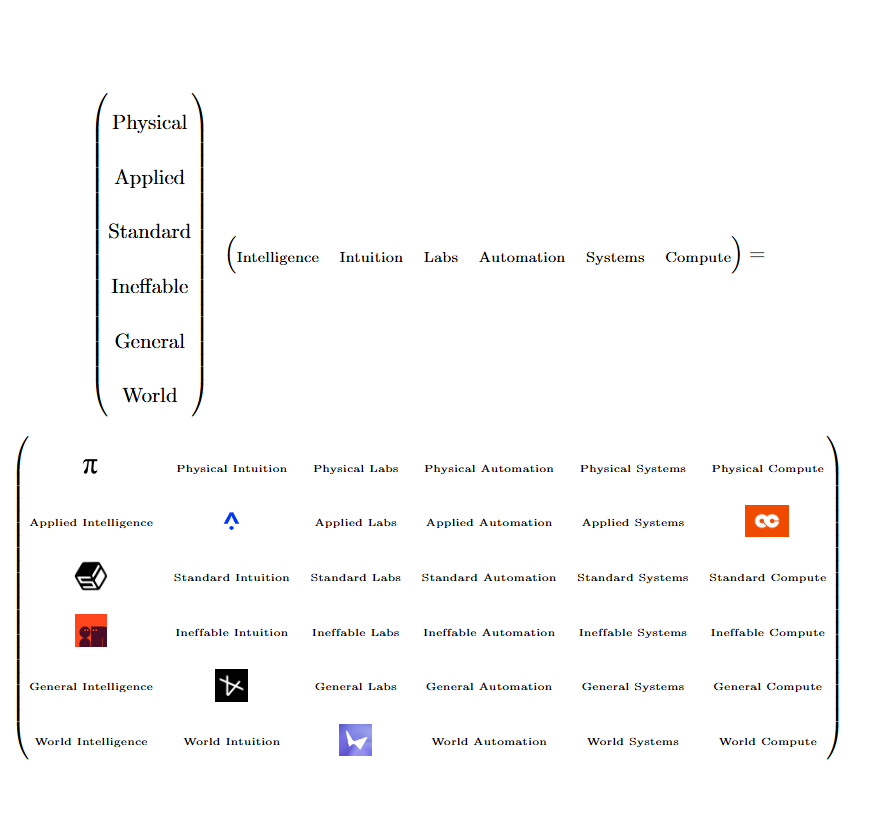
Therapist: linear neolabs are not real, they cannot hurt you.
me:
English

作为中文学习者,我一直以为母语者不会犯发音错误。看了这个视频才发现,原来声调和韵母出错也挺常见的。我会对自己的错误感觉好一点~~

中文


@oh_that_hat I sometimes think back to the "AGI" react in the Mila Slack when I was there in 2020, and the feeling of "pie-in-the-sky" that it evoked
English





how it feels to navigate an enterprise saas codebase with claude
English
I feel like the same thing applies to screen space. Love a multi-monitor setup but sometimes you've got to hunch over your laptop and lock in
Andrew Yeung@andruyeung
This is fascinating... the HEIGHT of the ceiling in the room you're working in has a DIRECT impact on how creative you are It's called the Cathedral Effect How it works: Your brain borrows metaphors from the physical world (space is one of the strongest) When a room feels tall and open, your mind unconsciously associates that with freedom and possibility - you zoom OUT When a room feels tight or enclosed, your mind goes into precision mode… attention narrows. You notice typos, spot mistakes, and hone in on details - you zoom IN Researchers found that people in high-ceiling rooms perform better on creativity. People in low-ceiling rooms perform better on detail orientation and error detection Churches and museums have soaring ceilings - meant to inspire awe. Libraries and war rooms are tighter - meant for concentration Startup brainstorms love lofts, and accounting teams love small rooms with doors Even coffee shops do this. The ones designed for deep work tend to be lower and quieter. The ones designed for conversation tend to feel more open So if you’re doing creative stuff - writing, designing, brainstorming - do it in a LARGE room with high ceilings. Then move to a smaller room to edit and proofread.
English

I’m happy to share that I’m starting a new position as Senior Research Scientist at @nvidia!
Looking forward to open science for speech full-duplex models :)

Desh Raj@rdesh26
After 2 wonderful years, I left Meta this week. During this time, I worked on several projects related to speech and LLMs: - Built the first multi-channel audio foundation model with M-BEST-RQ (arxiv.org/abs/2409.11494) - Made ASR with SpeechLLMs faster (arxiv.org/abs/2409.08148) and more accurate (ieeexplore.ieee.org/document/10890…) - Shipped the first production-ready full-duplex voice assistant (about.fb.com/news/2025/04/i…) - Improved Moshi’s reasoning capability with chain-of-thought (arxiv.org/abs/2510.07497) I am grateful to my managers for having my back on critical projects, and fortunate to have collaborated with several brilliant researchers and engineers during this time. As to what's next, I am still in NYC and continuing to do speech research. More on that later!
English
In Menlo Park they don't bother with gyms - they just have stores for equipment to put in your home gym

English
Lightning-fast demo, and with all-NVIDIA ASR, LLM and TTS models! 💚
kwindla@kwindla
NVIDIA just released a new open source transcription model, Nemotron Speech ASR, designed from the ground up for low-latency use cases like voice agents. Here's a voice agent built with this new model. 24ms transcription finalization and total voice-to-voice inference time under 500ms. This agent actually uses *three* NVIDIA open source models: - Nemotron Speech ASR - Nemotron 3 Nano 30GB in a 4-bit quant (released in December) - A preview checkpoint of the upcoming Magpie text-to-speech model These models are all truly open source: weights, training data, training code, and inference code. This is a big deal! Jensen said in the CES keynote yesterday that he expects open source models to catch up to proprietary models this year in a number of categories. NVIDIA is putting their weight behind making this happen. (As Alan Kay said, the best way to predict the future is to invent it.) The code for this agent is open source too, of course. You can deploy it to production with @modal and @pipecat_ai cloud, or run locally on an @nvidia DGX Spark or RTX 5090.
English









another nice thing someone did for my birthday (thank you grace) was convince a former magician who dropped out of stanford to launch a hedge fund to perform magic tricks for the chance to meet dylan patel

English

i realized that no one forces you to make your matcha iced

English
