
LF
918 posts



(and I myself am of course a rebel and played some role in the first ChatGPT plus rebellion that ultimately lead to the downfall of the insane GPT-5 limits)
English
I like to think that he sent an X-Wing, because the rebels used it to blow up the death star
Lisan al Gaib@scaling01
Sam actually sent me an X-Wing and some extra goodies :) thank you a thousand times
English
@scaling01 This would mean that the dream to have an on device model on your MacBook Air as your CTO is not gonna happen soon and might not even happen ever. I don’t know how I feel about that, I guess we’re not close to reduce our dependency to main AI labs
English
I'm sure you can squeeze small models a lot more, but there's a depth and knowledge gap.
My guess is that a 120B can find the same exploits mythos did, but only if it has a lot more test time compute + heavily overtrained on cyber and it has to be distilled from an even stronger model than mythos.
my timeline for such a 120B model is 2028-2030
English
the positions are based on vibes right now, and also capture more the coding domain rather than all domains
which is why the lag for frontier chinese models is ~6 months right now / GPT-5.2 or Opus 4.5 level
English
what do you think about this idea to chart current AI capabilities and factor in the acceleration/velocity of labs?
don't read too much into the actual numbers, right now it's more a vibe of what model capabilities are right now and could be in 12 months
today:
Anthropic > OpenAI >> Google >> Meta > xAI >= DeepSeek, Moonshot, Alibaba, Zhipu, ByteDance > MiniMax
In 12 months I think it's pretty much the same except that all the labs that aren't on the frontier will fall behind by a couple of months depending on how much compute they have
I would also really like to add error bars to that, because for some labs the outcome distribution is just much wider.

English
@scaling01 @scaling01 is this « the one » ? github.com/voice-from-the…
Or the « Mahdi » I should say to not offend you and your fight to defend Dune vs LOTR :D
English
@scaling01 Hey, you have somewhere details on how your benchmark works?
Like a GitHub repo and one example, to better get the idea?
English
LisanBench results for GPT-5.5 - it's good.
GPT-5.5 is now the strongest model without Thinking on both metrics!
GPT-5.5-medium uses on average ~45.6% less tokens than GPT-5.4-medium while scoring 1.77x higher!
(1.14x higher score on the difficulty weighted metric)
Running LisanBench for GPT-5.5-medium cost basically the same as for GPT-5.4-medium despite being 2x more expensive.
GPT-5.5-medium has the highest validity ratio (% of legal and correct moves) out of all tested models.
In the overall GPT-5.5-medium is:
- Rank #4 by average path length: 9327
- Rank #3 by difficulty-weighted score: 2539
on the difficulty weighted metric:
- Opus 4.7-xhigh used +134.9% more tokens and scored +55.9% higher
- Opus 4.6-16k used +11.1% more tokens and scored 9.2% higher
- Sonnet 4.6-16k used +3.1% more tokens and scored -9.1% lower
Current Validity ratio leaderboard:
1. GPT 5.5 (medium): 99.44%
2. Opus 4.7 (xhigh): 99.35%
3. Sonnet 4.6 (16k): 99.28%
4. Opus 4.6 (16k): 98.74%
5. Gemini 3.1 Pro Preview (low): 97.77%
The "non-thinking" version of GPT-5.5 uses 3.3x more tokens than GPT-5.4 (non thinking), but gets a 3.1x higher avg score and 2.96x higher weighted score.

English
@iruletheworldmo Thank you for this post, I’m not the worried about AI kind of guy, but this is still worrisome. I think the problem is not how to handle misalignment (I’m sure researchers will find ways), but the fact that it’s a race and some players would rather be 1st and take risks than wait
English

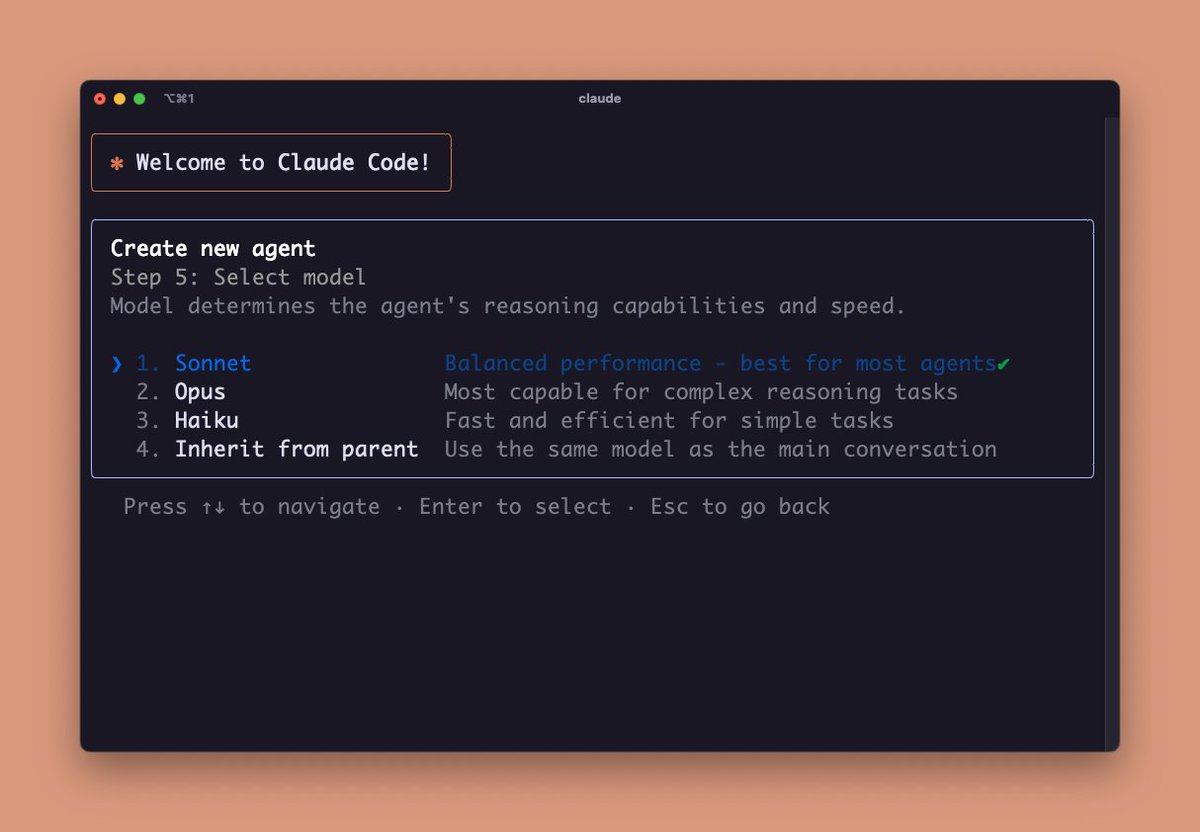
@_catwu Hi, we really need a way to get the result of a subagent work easily (like cmd+R). I have subagents code analyzer/security checker and I would like to only get their output/final review, it's currently hard to get them when we stack multiple agents one after the other
English


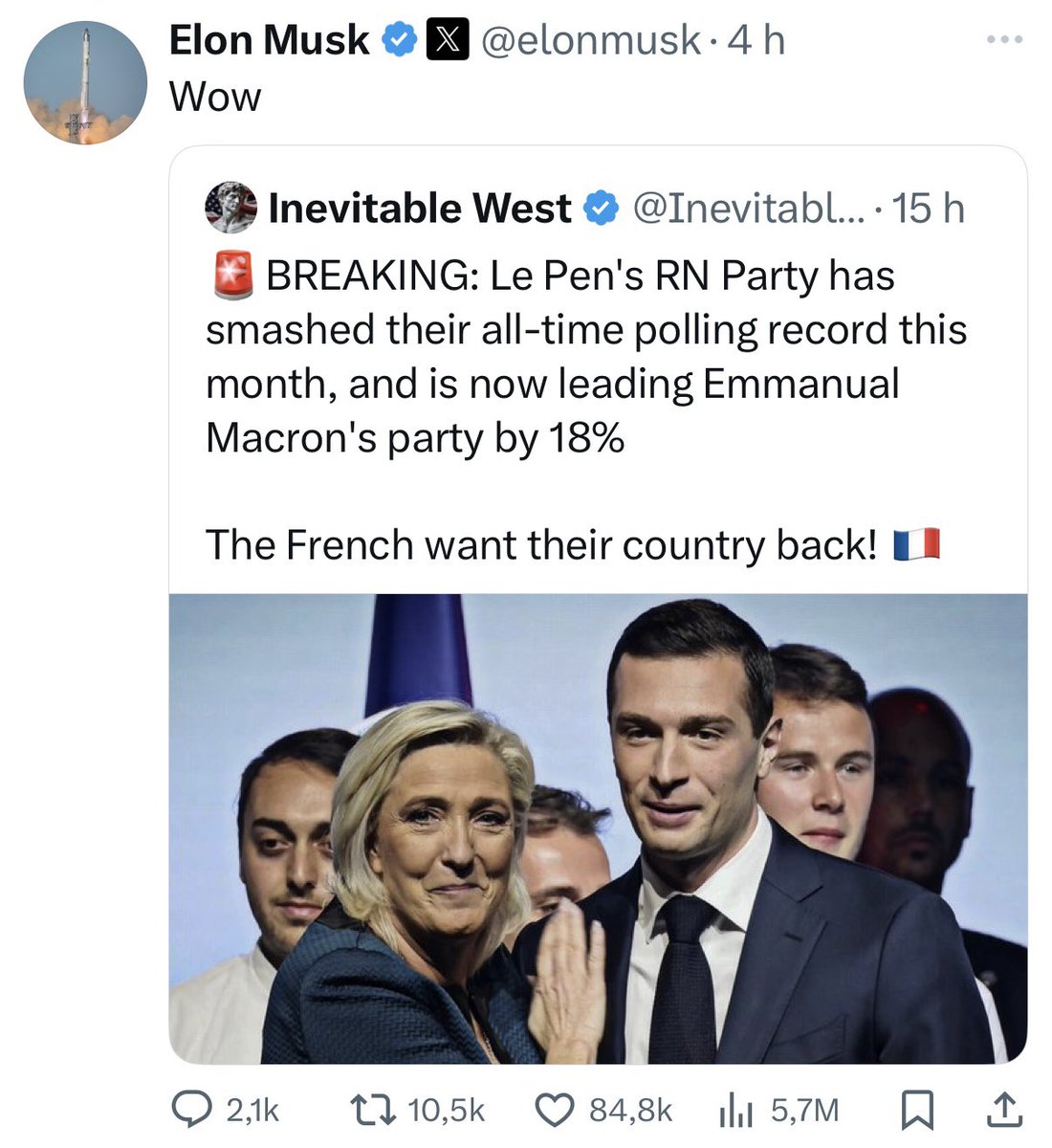
Elon Musk va-t-il mettre son réseau social au service du RN?
Français

Going to do a chill stream tomorrow at 6pm PT, trying to take one of my favorite AI demos and make it agentic—AI Town

Thariq@trq212
unironically spent all last night talking to @sawyerhood about how we could rebuild every one of our old LLM projects with an agentic harness and it would be way better
English
@SiempreMickael @pierre_jacquel2 Bonjour, je ne suis pas d’accord, lisez cet article qui prouve l’inverse par l’exemple : bfmtv.com/economie/entre…
Français

Fun fact. : L’iPhone est le tel le plus éthique et le plus durable (Fairphone exclu).
Le fait que les droitards répètent ce truc en boucle montre à quel point ils sont pas des lumières. 😭
Français

Something small but I made a markdown to phone-optimized png as a public Claude Artifact if anyone needs that. I share rendered AI-generated markdown as an image to people on a regular basis due to certain compatibility/rendering benefits on some platforms claude.ai/public/artifac…
English