Lotfi Slim retweetledi
Lotfi Slim
250 posts

Lotfi Slim
@EpiSlim
AI Developer Technology Engineer @Nvidia
London, England Katılım Şubat 2017
1.2K Takip Edilen181 Takipçiler

Lotfi Slim retweetledi

Oh, you're writing CUDA kernels? Everyone's on Triton now. Just kidding, we're all on Mojo. We're using cuTile. We're using ROCm. We have an in-house DSL compiler targeting the NVGPU MLIR dialect but wait, Tile IR just dropped so we're going to target that instead. Our PM is on TileLang. The team lead was on CuTe but now she's back to handwriting PTX. If you're not on Pallas, you're ngmi. Our intern is building on TT-Metalium for our Wormholes. Our CFO approved an order for some big chungus wafer-scale chips so now we're porting our kernels to CSL. Our CTO is working on a kernel-less graph compiler so we won't need to write kernels anymore. Our CEO thinks we're talking about the Linux kernel. We're building Claude for dogs.
English
Lotfi Slim retweetledi

lots of fun quick tpu/performance engineering interview questions in here :D jax-ml.github.io/scaling-book/
English
Lotfi Slim retweetledi
🔥🚨 CUTLASS Blackwell is here 🚨🔥
3.8 release is loaded with support for new features of Blackwell, even an attention kernel 👀
Go check it out here: github.com/nvidia/cutlass
Can't wait to see what y'all end up cooking with this over the next few moths and years 💚

English
Lotfi Slim retweetledi

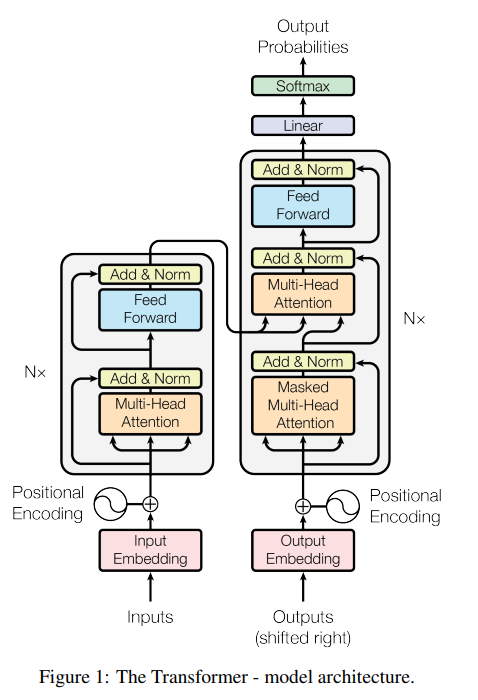
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Literature to the Attention Is All You Need authors.
Their work has made thousands cry, laugh, or rich and made GPUs go brrr

English
Lotfi Slim retweetledi

50% increase in transformer throughput via the use of @nvidia cutlass to implement fused quantised layers #nanoporeconf
Marcus Stoiber@Stoibs11
Faster SUP models in Dorado through a number of approaches. #NanoporeConf
English
Lotfi Slim retweetledi
Come learn today at 2pm ET why we use @NVIDIAAI CUTLASS for high-throughput inference kernels in vLLM!
If you are interested in peak quantized GEMM performance on GPUs, this is the talk to attend and ask questions
Red Hat AI@RedHat_AI
🚨 vLLM Office Hours continue on Thursday, September 5th, at 2PM ET / 11AM PT! Tyler Smith (@tms_jr), vLLM Committer & Technical Director at Neural Magic, will dive deep into using NVIDIA CUTLASS for high-performance INT8 & FP8 vLLM inference. Sign up: neuralmagic.com/community-offi…
English
Lotfi Slim retweetledi

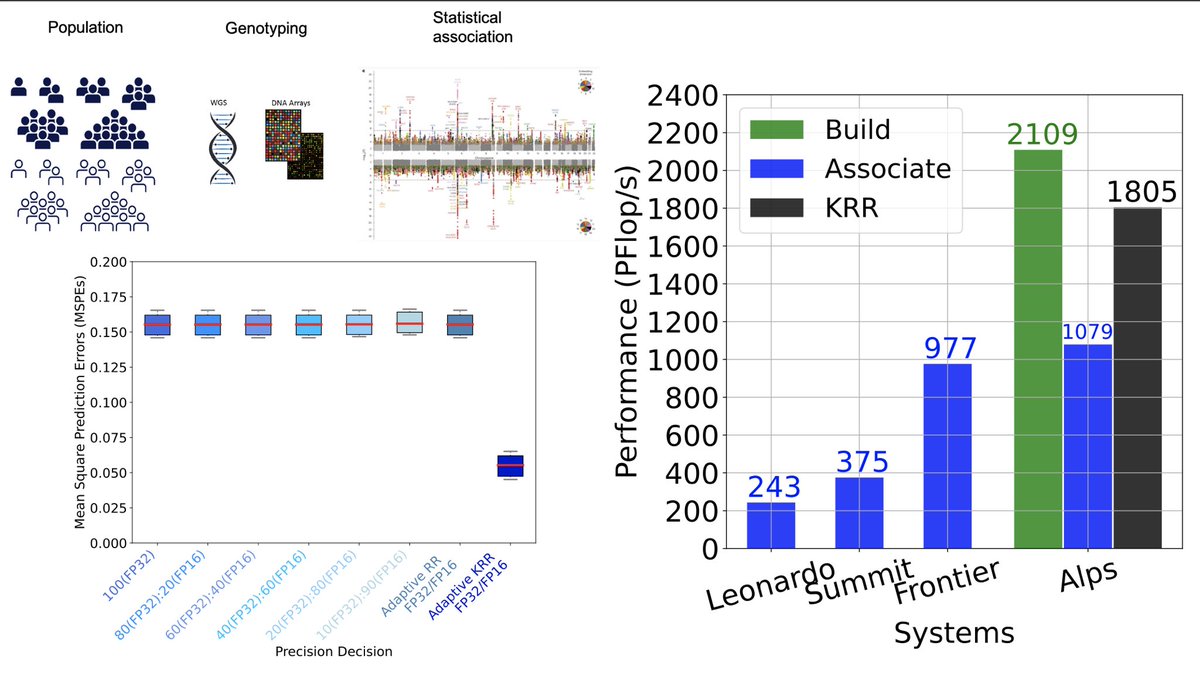
📣 When #exascale meets #bioinformatics #GWAS to capture nonlinear genetic #epistasis using #NVIDIA #MxP #GPU:
- 1.8 EFlop/s on #Alps @cscsch
- 305K patients of UK #BioBank
- 13M synth cohort, ~63% of the world's countries 🌍
- 10000X vs SOTA #REGENIE
#GordonBell #SC24 #HPC
English
Lotfi Slim retweetledi

pytorch.org/blog/int4-deco…
I highly recommend this study to build intuitions for GPU programming.
One of the difficulties with GPU programming is that it's hard to test a hypothesis about a certain optimization.
Say we expect an optimization to improve the final speed, but we don't observe any improvement.
We would start to wonder whether our intuition about the optimization is wrong, or whether it's a bug in our code.
That is why studies like this one should be cherished. Apart from providing a good INT4 KV cache attention kernel, the study provides the improvement analysis for each of their 10 optimizations on top of the previous ones. The analysis come with annotated screenshots from NCU, with clear pointers to where to look. I learned a lot from this study.
English
Lotfi Slim retweetledi
We gave our first in depth publicly available talk on CUTLASS 3.x and it’s up on YouTube now!
Andreas Köpf@neurosp1ke
The CUTLASS/TensorCores/Hopper lecture covered quite advanced cuda programming. I guess we need further ramp-up lectures to make these topics more accessible. Recoding: youtu.be/hQ9GPnV0-50?si… Slides: drive.google.com/file/d/18sthk6…
English
Lotfi Slim retweetledi

Two new chapters from my open-access textbook in human population genetics are now online:
- Population structure: I. Ancestry estimation
- Population structure: II. More about admixture
web.stanford.edu/group/pritchar…
Jonathan Pritchard@jkpritch
I'm delighted to release the first half of my new open-access online textbook in human population genetics: web.stanford.edu/group/pritchar…
English

Lotfi Slim retweetledi

I've done a deep dive into distributed training and efficient fine-tuning of LLMs. I get into the messy internals of DeepSpeed ZeRO and FSDP, summarize practical guidelines and highlight gotchas with multi-GPU training.
sumanthrh.com/post/distribut…
Do read, should be fun!
English
@koalalesque Nonetheless, for all its merits, I won't start learning CSS anytime soon 😆
English
Completely blown away by template programming in C++ being Turing complete.
English
A must-read blogpost about sequence alignment and the differentiable CTC loss distill.pub/2017/ctc/
English
Lotfi Slim retweetledi

We’re proud to have helped set a new standard for Generative AI by building a cluster with 3,584 @NVIDIA H100 GPUs in the debut MLPerf benchmark.
Our system completed the massive GPT-3-based training benchmark in under eleven minutes. 🚀
Read more: blogs.nvidia.com/blog/2023/06/2…
English
Lotfi Slim retweetledi

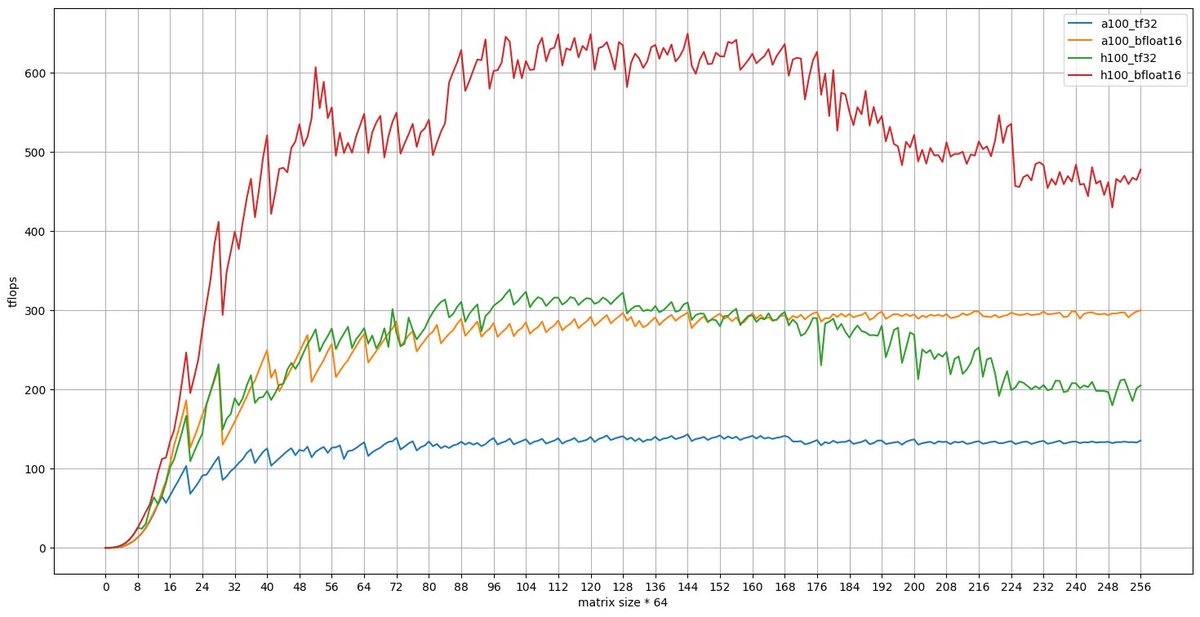
H100 GPUs are very fast!
For those unfamiliar with GPU matrix multiplies, the jaggies in the graph relate to packing occupancy, and are not noise. You can’t just divide theoretical teraflops by your problem size and get accurate times.
English
Lotfi Slim retweetledi

A worthy competitor to the TPU pods has (finally) arrived:
developer.nvidia.com/blog/announcin…
English
Great work from @qsirelkhatim and @sacdallago as always!
InstaDeep@instadeepai
1/ We are happy to announce the open-source release of the inference code and weights of our four genomics #LLM, the nucleotide transformers, ranging from 500M to 2.5B parameters, trained in collaboration with @nvidia and @TU_Munchen 🧬 bit.ly/3YRSUz1
English