OpenEvidence@EvidenceOpen
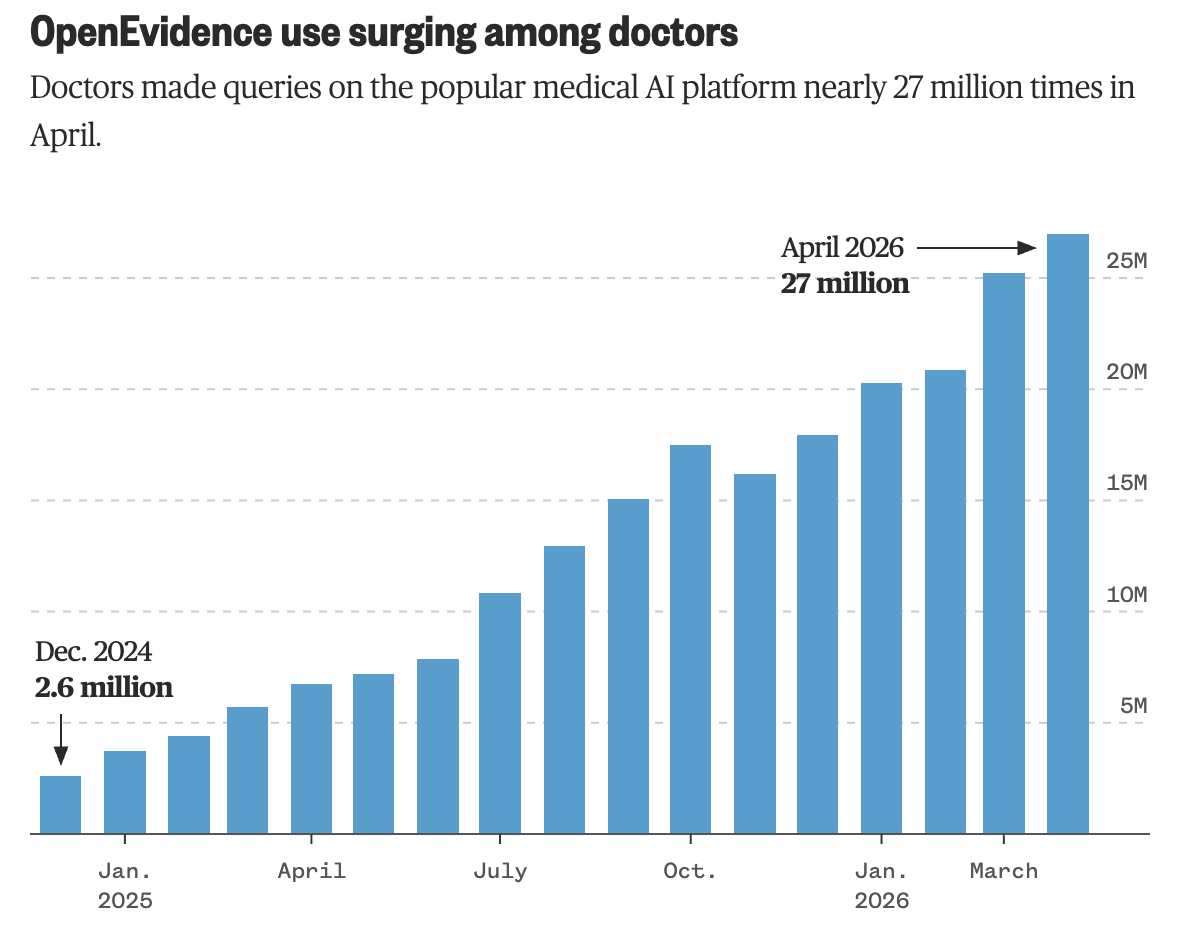
Last summer an ER doctor at Mount Sinai watched two med students and a resident pull up OpenEvidence mid-shift on a hard case. He assumed they were unusual. Then the health system found that a third of its 9,000 physicians were already using it.
That's how OpenEvidence spread. Doctors found it, tried it on real cases, and told the doctors next to them. The hospitals are now formalizing what their clinicians already do.
@SteveLohr piece in today’s New York Times follows that thread out to a small hospital in Alaska, where Dr. Barbara Creighton uses it on complex cases she’d otherwise send to a paid specialist consult. She calls it “like having a bunch of specialists in your pocket.”
The hype around medical AI usually skips the part doctors care about most, which is what the tool is for. Daniel Nadler summed it up in one line: “It’s not an oracle, it’s a tool. Knowledge and knowledge workers still matter.”