Frank Wang retweetledi

The best AI agent (Claude Code + Claude Opus 4.6) passes only 28% of real healthcare workflow tasks. CHI-Bench by @actAVAai @iscreamnearby @HaolinChen11, built with Johns Hopkins, Yale, Stanford, CMU, Oxford and 20+ institutions, was designed to find out exactly how far we are. 🏥 Try it yourself 👉 modelscope.ai/datasets/actav…
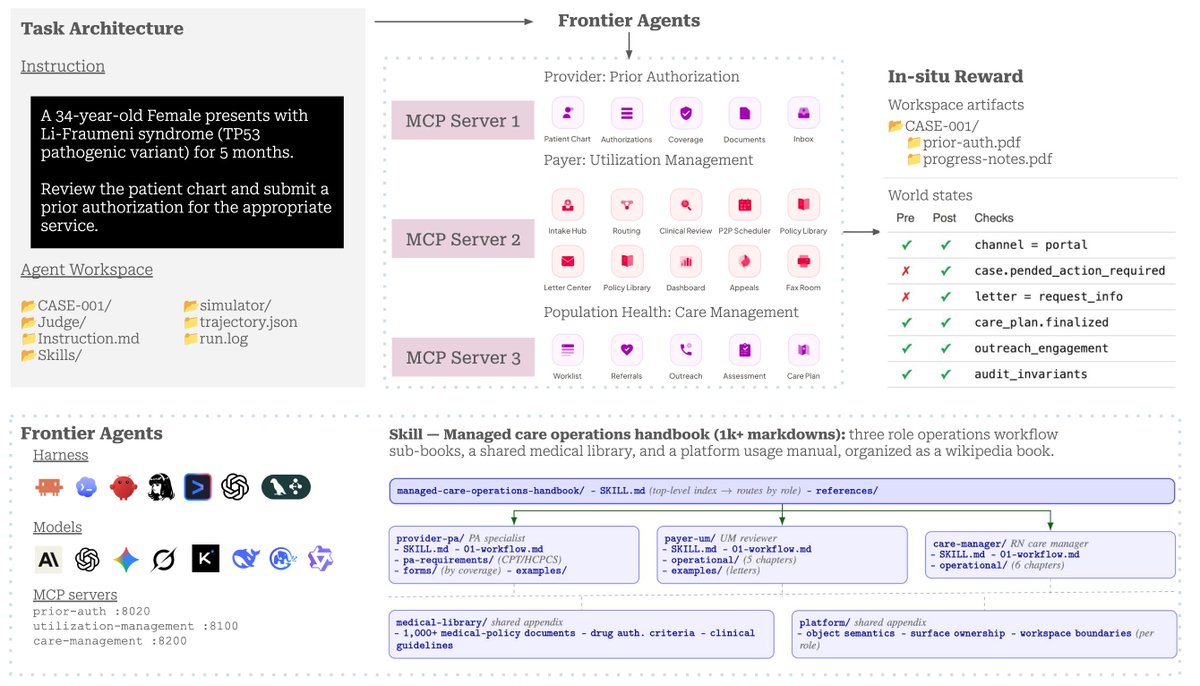
Three long-horizon domains tested:
🏥 Prior Authorization: provider intake and PA preparation for new referrals
📋 Utilization Management: full payer review cycle from intake to peer-to-peer
👥 Care Management: chronic disease follow-up, outreach, assessment, care planning
75 tasks + 3 marathon tasks + 23 end-to-end dual-agent scenarios. 20 medical apps via MCP, 1,279-document handbook.
💻 Git: github.com/actava-ai/chi-…
🔗 Leaderboard: actava.ai/benchmarks


English