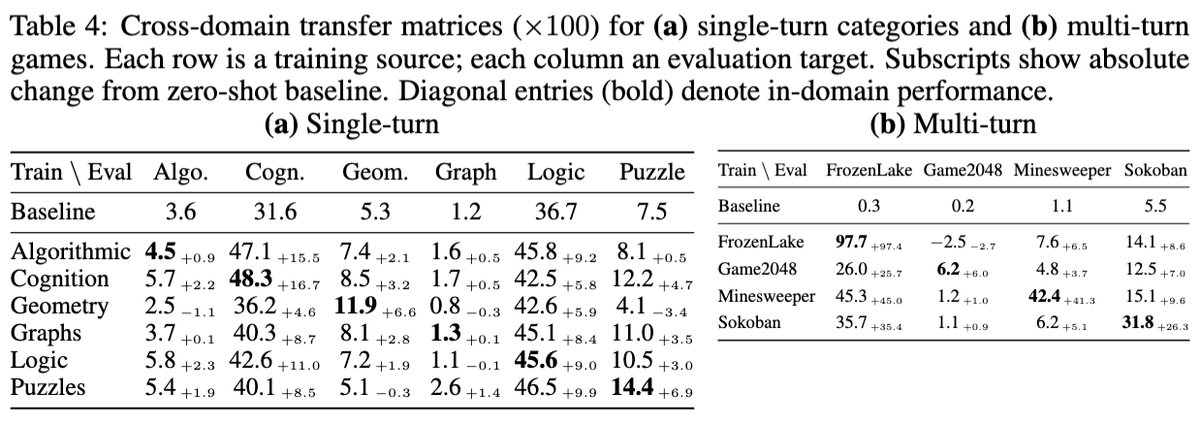
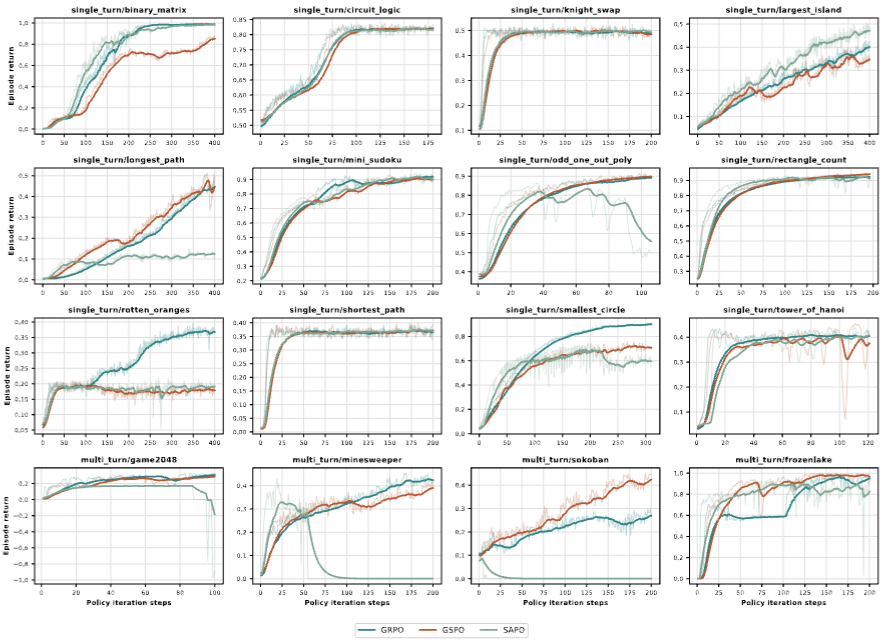
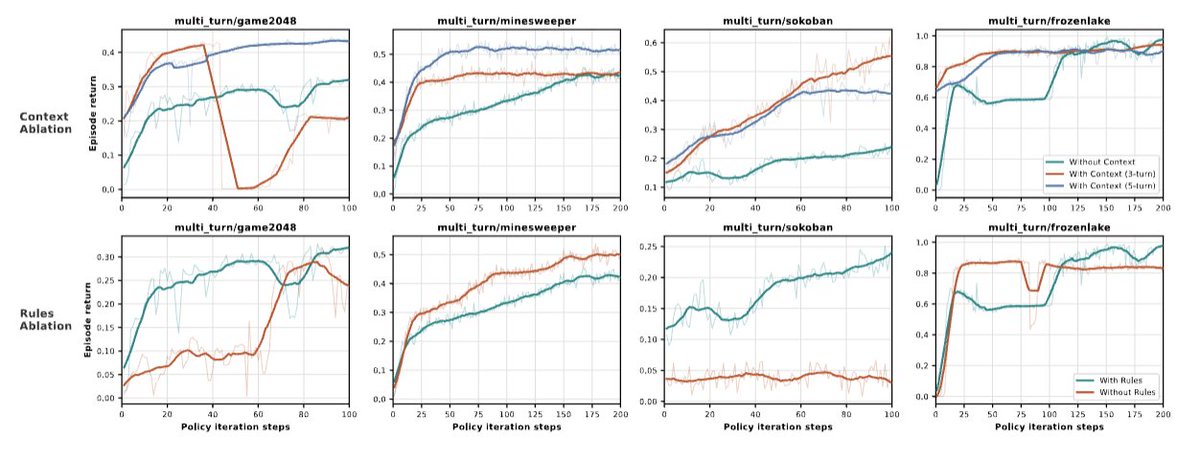
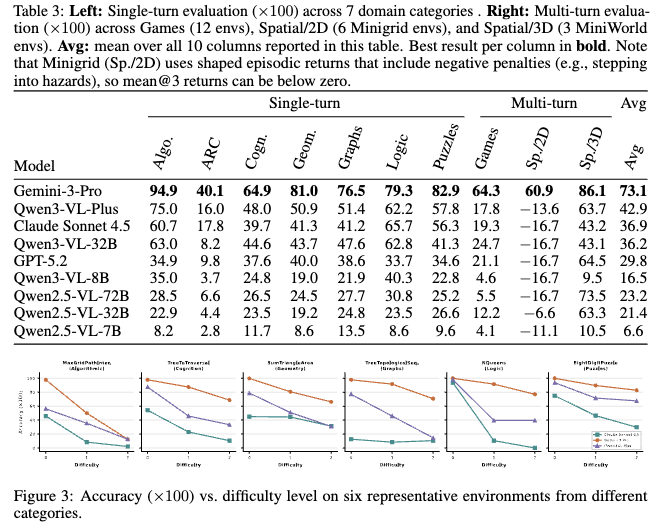
Sabitlenmiş Tweet

I am so confused that some says research and engineer separately
To be a Good Engineer , Then learn to become Researcher
English
Fanqing Meng
411 posts
@FanqingMengAI
vibe phd | kimi | kimi linear, K2, K 2.5, mm-eureka | Options are my own | https://t.co/LDxlIjhSih

Done @garrytan Now you can use your apple watch to control claude code session! built this in 6 hours, used gstack for this See /office-hours from gstack in action in the video. - Your Claude session, live on your Apple Watch - Accept, reject, or reply instantly to prompts use it here, made it open source: github.com/shobhit99/clau…





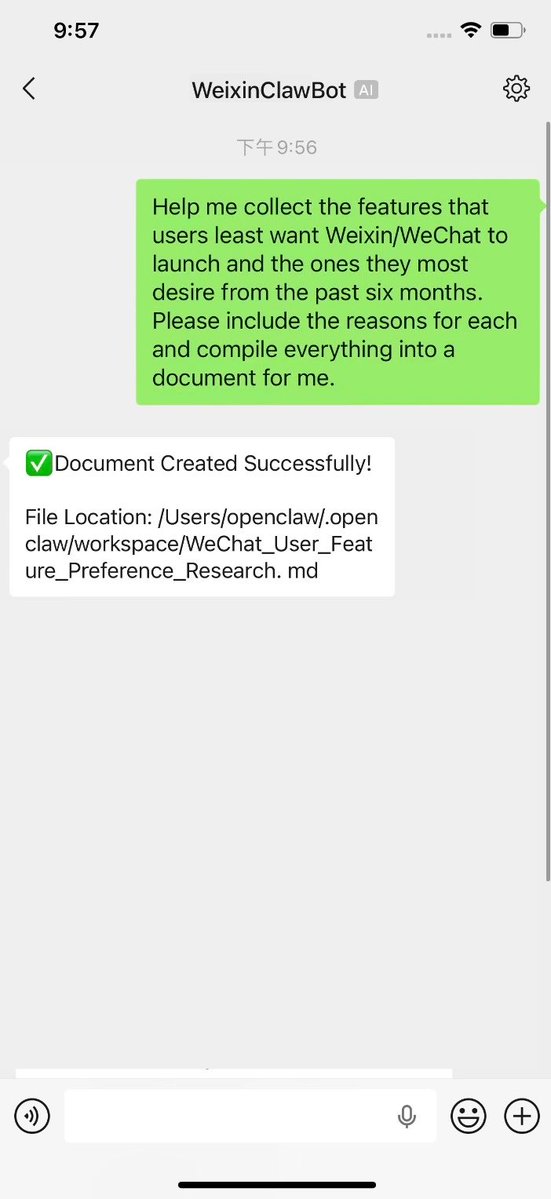

“我现在什么报错都不怕,反正AI解决” “那这个呢” $ claude zsh: claude: command not found $ codex zsh: codex: command not found