
Vignesh Prasad
483 posts

Vignesh Prasad
@FatAndFurious42
Trying to teach robots how to shitpost Robot Learning Post-Doc w/ @GeorgiaChal Ex: @ias_tudarmstadt @TCSResearch @iiit_hyderabad (Also a comedian)
Darmstadt, Germany Katılım Mart 2020
970 Takip Edilen391 Takipçiler

@FatAndFurious42 Did you get the two TV shows referenced in my tweet?
English
Ohh...he is not available. He is busy making a miracle drug that gives you super hero abilities. Also he is in a constant fear that he is cursed because all his girlfriends keep getting attacked.
English
Want to know how to learn effective multisensory representations that make your robot robust to partying?
Check out our latest RAL paper by @RKrohn_ : msdp-pearl.github.io
Rickmer Krohn@RKrohn_
Solving contact-rich manipulation tasks even under disco light🪩? Incorporate multiple sensors using MSDP and obtain a robust policy in under 55 min! Excited to share our work accepted at RA-L: Self-Supervised Multisensory Pretraining for Contact-Rich Robot Reinforcement Learning
English
Vignesh Prasad retweetledi

This is what happens when novelty, not results, becomes the North Star. The real work is often in the system details, but those rarely make it into the spotlight. Instead, we get unnecessary “novelty” that’s easier to package, pitch, and hype.
Will there ever be a time when system details are treated as first-class citizens in papers?
Chenhao Li@breadli428
Can’t agree more. Robotics is to make integration work! But now even when existing components integrate seamlessly for a new task, there’s a push to invent something unnecessary just for the sake of novelty. This is why papers read more marketing today. x.com/breadli428/sta…
English
Vignesh Prasad retweetledi

🚀 Hiring PhDs & Postdocs in Structured Robot Learning & Embodied AI @TUDarmstadt (PEARL Lab)
🤖 We study how structure in the robot–environment system can be exploited to learn robust, adaptive, and generalizable behaviors, beyond black-box policies
🔬 Topics:
• Grounding (language → perception → action)
• Structured world models
• VLA + control + memory
• RL (credit assignment, offline→online)
• Whole-body & bimanual mobile manipulation
🇪🇺 New EU Lighthouse Project on Generative AI for Robotics + ERC StG SIREN
👉 Full call: tinyurl.com/pearlgenai
Please repost 🙏
#RobotLearning #EmbodiedAI #Robotics #MachineLearning #PhDPositions #Postdoc
English
Vignesh Prasad retweetledi

Simplicity should be valued more. When a task can be solved equally with a simpler framework, one should not be blamed having “nothing new”.
Many unnecessary novelties are invented for the sake of novelty, while the effort of making simpler methods general is not appreciated.
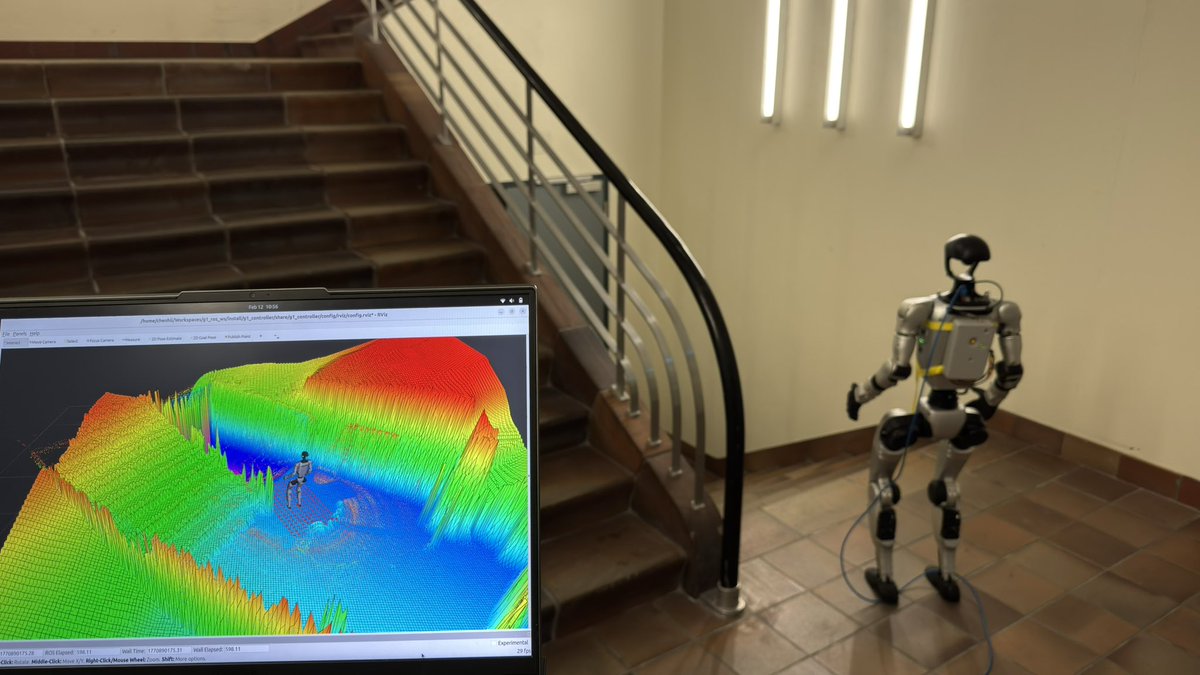
English
Vignesh Prasad retweetledi

🚀 New work accepted to ICRA 2026!
We introduce a flow-matching framework on the SE(3) manifold. Instead of just a single guess, our model captures the full pose distribution—perfect for handling tricky occlusions, symmetries, and partial views in real-world robotics.
Huge thanks to my amazing collaborators! @n_w_funk @softraeh @FatAndFurious42 @Jan_R_Peters @GeorgiaChal
📄 Paper: arxiv.org/abs/2511.01501
🌐 Website: yufengjin.github.io/projects/se3-p…
English
Alma mater researching things that matter 🔥🔥🔥
neural nets.@cneuralnetwork
this is an actual research paper 😭
English
Vignesh Prasad retweetledi

Repeat after me: This is NOT a paper contribution, it’s an expected component!

English
Vignesh Prasad retweetledi

Anyone with basic brains can figure out what Indigo did was very intentional. This was not sudden disruption, this was almost a planned strike to strongarm the government into giving it what it wants. What people went through doesn't matter to them, it's just collateral damage. And the fact that govt let this happen is on them. The fact that we essentially have monopolistic/duopolistic situations in so many major sectors is on this Government. But what to do, let's look for ways to blame RaGa on this too.


English
How can we effectively integrate information from multiple sensors, such as cameras, force-torque, and joint proprioception, for real-world contact-rich manipulation?
Check out @RKrohn_'s work on multisensory representation learning for RL: arxiv.org/abs/2511.14427
Rickmer Krohn@RKrohn_
Multisensory Dynamic Pretraining (MSDP) is based on masked autoencoding and cross-sensor prediction, leading to rich sensor fusion. Usage of the FT-sensor boosts performance by 14%! Our approach is flexible regarding the number and type of sensors. More Details in the Preprint!
English
@rz_california While I agree, RAL also has long timelines for conferences. Eg., to present at IROS in Oct. 2026, a RAL paper needs to be accepted and transferred by April 30th, so the paper should be submitted in Nov. 2025 in the most ideal case, almost a year before the conference
English

That’s one of the reasons why I recently prefer RA-L more. If there is a double-anonymous journal that can finish one-round constructive rebuttal and give you feedback within 3 months, then Conferences like ICRA and IROS will be less attractive. Especially RA-L paper can also be presented at these conferences.
Zhi Su@ZhiSu22
CoRL 2026 is cutting review cycles to <3 months to keep pace with the rapid progress in robotics. @ieee_ras_icra @IROS2025 — maybe it’s time to rethink too. It makes little sense to discuss papers at conferences a year after submission, when they’re already outdated.
English
If you're at ICCV and are interested in object pose estimation, gaussian splatting, and in general about 3D geometry, object-centric representations for robotics, come on over to Poster 744 at 3pm
Snehal Jauhri@SnehalJauhri
We present "6DOPE-GS: Fast, accurate 6D object pose tracking via Gaussian Splatting" during the Tuesday 21st afternoon poster session, w/ Vignesh Prasad @FatAndFurious42 and led by Yufeng Jin @yjin_1118 🌐Project page: pearl-robot-lab.github.io/6dope-gs 📄Paper: arxiv.org/abs/2412.01543
English
Vignesh Prasad retweetledi

Slides for my #ICCV2025 RANSAC in 2025 talk are here
drive.google.com/file/d/1_1zYAo…
English
Meanwhile OpenAI is rolling out the iPhone pro max plus ultra super so that the next town over can have a water crisis
prinz@deredleritt3r
Just to recap: We found out today that an LLM that fits on a high-end consumer GPU, when trained on specific biological data, can discover a novel method to make cancer tumors more responsive to immunotherapy. Confirmed novel discovery (not present in existing literature). Experimentally validated in living cells. This is AI generating novel science. The moment has finally arrived.
English
"2HandedAfforder" was a best workshop paper finalist at the H2R Workshop on Sensorizing, Modeling, and Learning from Humans at CoRL 2025!!! 🎉🎉🎉

Snehal Jauhri@SnehalJauhri
PSA for the robotics community: Stop labeling affordances or distilling them from VLMs. Extract affordances from bimanual human videos instead! Excited to share 2HandedAfforder: Learning Precise Actionable Bimanual Affordances from Human Videos, accepted at #ICCV2025! 🎉 🧵1/5
English
Vignesh Prasad retweetledi
Excited to be in Korea almost a year after being away from conferences. Now I come back for two conferences #CoRL2025 and #Humanoids2025 with a small guest 👶 While on maternity leave my amazing team continued progress on Structured Robot Learning! Here is a list of the activities of PEARL group at @corl_conf:
1. Today, Saturday Sept. 27 I will give a talk at the corl25-genpriors.github.io talking about Beyond Scale: Structured Priors for Efficient Robot Learning at 11:25. Join me to get a glimpse at the newest cool research from the pearl-lab.com
2. I’ll also be at the panel of the same workshop at 15:25! Looking forward to the fruitful discussions.
3. Also today,Vignesh @FatAndFurious42 will present our new work on extracting Bimanual Affordances from Human Videos (sites.google.com/view/2handedaf…) at the sites.google.com/view/h2r-corl2… and sites.google.com/stanford.edu/c…
4. While Frankie @FrankieZhang41 will present our new work on “Adaptive Diffusion Constrained Sampling for Bimanual Robot Manipulation” (…fusion-constrained-sampling.github.io) at the rational-robots.github.io
5. Tomorrow Sept 28, Steven @softraeh will present SYMDEX: Morphologically Symmetric Reinforcement Learning for Ambidextrous Bimanual Manipulation supersglzc.github.io/projects/symde…. Catch him at Spotlight 2 & Poster session 1.
We have more to present at the Humanoids conference, so stay tuned!
English
Vignesh Prasad retweetledi

Abacus, spelling bee, etc are all useless pursuits which does overall harm than good.
Kids should grow up playing sports and musical instruments instead of all this grindjeetry.
SriSathya@sathyashrii
Do you regret not learning Abacus ?? --- YES/NO
English
Vignesh Prasad retweetledi

Why I Went Silent After Launching Empowered Indian – And Why I'm Done Being Quiet
3 days ago, I launched the MPLADS Dashboard showing where public money really goes.
Within hours, I got an email: "Take it down before things get messy. We know where you live. We're watching closely."
So I went dark. For 3 days.
Not because I'm scared. But because I needed to think.
Here's what I decided:
The dashboard is coming back. The data will be public. The truth will out.
Because every threat proves we're onto something. Every attempt to silence us shows they have something to hide.
They wanted me to "play smart" and disappear.
Instead, I'm going loud.
To whoever sent that threat: You just turned a website into a movement. Congratulations.
To everyone else: They're scared of transparency. They're scared of YOU knowing where your money goes.
Let's give them something to really fear.
#EmpoweredIndian
CC: @malpani
English