Sabitlenmiş Tweet

Doing lesson 15 of the @fastdotai course; deducing how to rearrange convolutions as a matrix product

English
Salman // 萨尔曼
1.4K posts

@ForBo7_
「Open to Projects」 • Dabbler • Learner • Explorer • Logger • https://t.co/jTudwv3AAp student • Dabbling in Embodied AI • 自学中文 // Self-learning Chinese



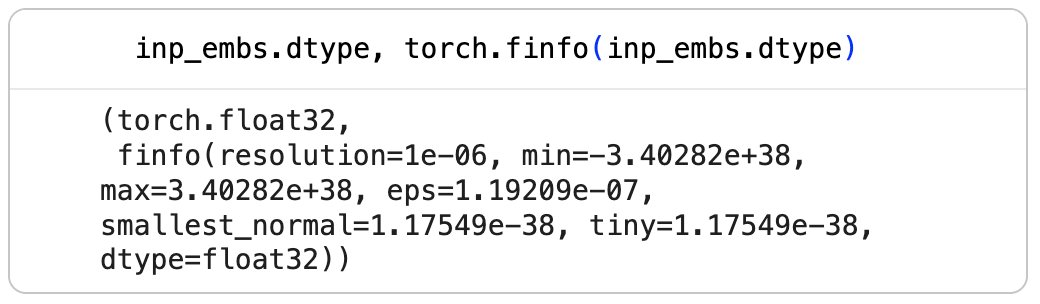
CLIP has 2 embeddings: - token emb - position emb the token emb is like a lookup table: given a token having id X, fetch it's emb the positional emb stores the position of a token in a sequence; otherwise, "man bites dog" and "dog bites man" would have the same repr




Follow-up on non-English token-inefficiency with more model-language pairs: - Chinese is cheaper than English on major Chinese models - Gemini and Qwen provide least non-English tax - Anthropic has the highest tax by far; Kimi is next - Hindi is the worst-covered language here, despite its massive speaker base





