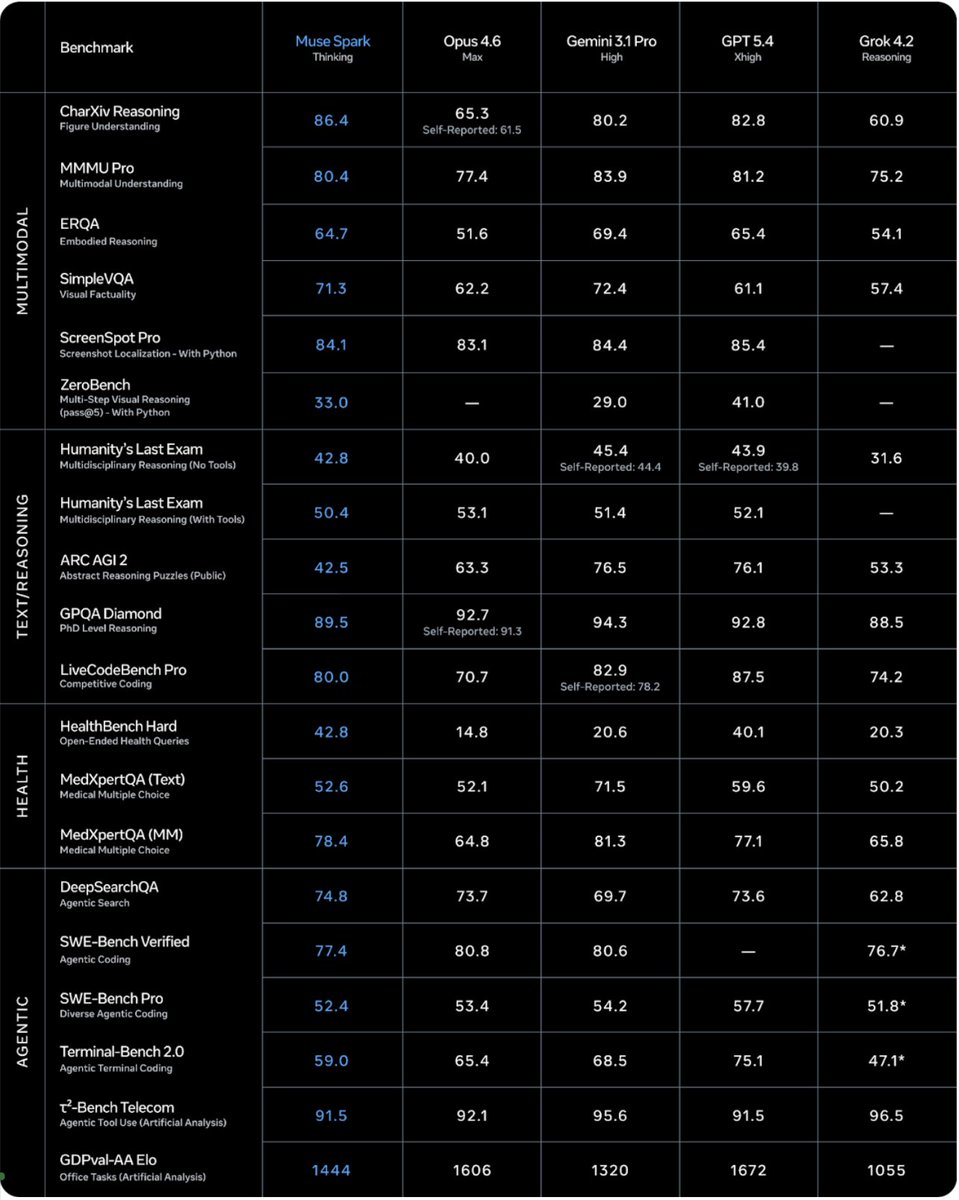
Most AI-in-pharma stories are about going faster. Profluent and Lilly's partnership is a scientific moonshot -- using AI to design large-scale DNA editors for genetic diseases where one-mutation fixes don't work, reaching patients conventional approaches can't
Ali Madani@thisismadani
AI has two modes in drug discovery. Accelerate: moving faster through the existing playbook. Unlock: opening frontiers that weren't possible before. Excited to announce Profluent is partnering with Eli Lilly, the global pharma powerhouse, to unlock breakthrough medicines for patients. It's a big deal beyond the numbers ($2.25B + royalties): we’ll get to use our frontier AI models and foundational datasets to design proteins focused on large gene insertion, a therapeutic moonshot. Proteins govern almost everything in biology. We've built a generalizable AI platform to design all proteins. Onward!
English