
@pmddomingos Exactly! Human brain and the whole human civilizations recorded by language
English
Fu-Ming Guo
169 posts
@FumingGuo
Chief Architect AI/ML @ Visa. Opinions are my own.



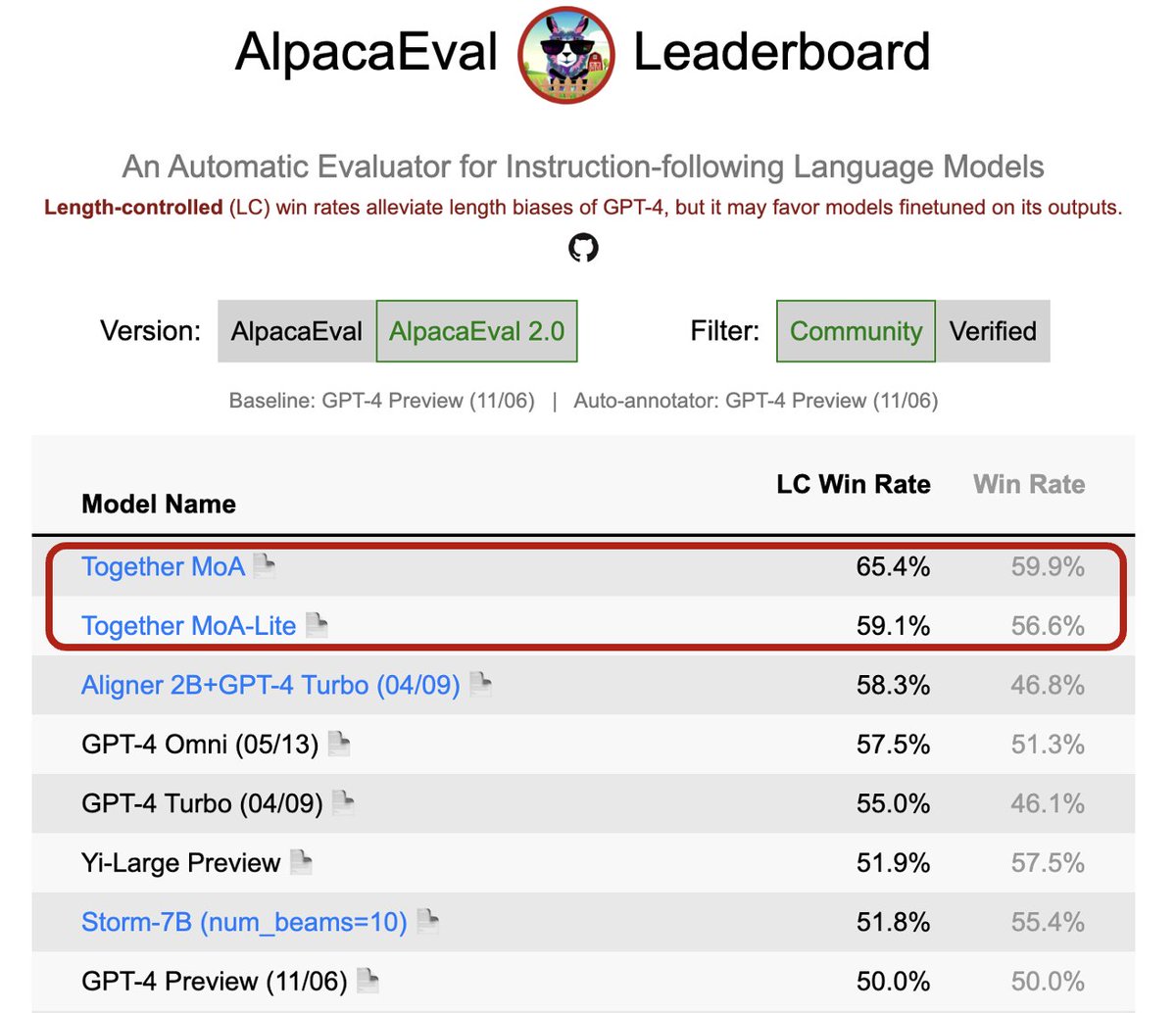
Phase 1 of Physics of Language Models code release ✅our Part 3.1 + 4.1 = all you need to pretrain strong 8B base model in 42k GPU-hours ✅Canon layers = strong, scalable gains ✅Real open-source (data/train/weights) ✅Apache 2.0 license (commercial ok!) 🔗github.com/facebookresear…
Test of Time Winner Adam: A Method for Stochastic Optimization Diederik P. Kingma, Jimmy Ba Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks.
@iclr_conf many many many thanks to @kchonyc and @Yoshua_Bengio for enabling the wildest ever start of my research career 2014 was a very special time to do deep learning, a commit that changes 50 lines of code could give you a ToT award 10 years later 😲


@OpenAI o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too.


Introduce HumanPlus - Autonomous Skills part Humanoids are born for using human data. Imitating humans, our humanoid learns: - fold sweatshirts - unload objects from warehouse racks - diverse locomotion skills (squatting, jumping, standing) - greet another robot Open-sourced!







Meet Reka Core, our best and most capable multimodal language model yet. 🔮 It’s been a busy few months training this model and we are glad to finally ship it! 💪 Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body trailer.👇

Congrats 🎉 to the newly titled Dr. Lu @lupantech on defending his thesis about mathematical reasoning with language models"! 🧮 Pan has published a series of works on quantifying and improving math and scientific reasoning ability in LLMs. Some highlights:

A compelling intuition is that deep learning does approximate Solomonoff induction, finding a mixture of the programs that explain the data, weighted by complexity. Finding a more precise version of this claim that's actually true would help us understand why deep learning works so well. There are a couple recent papers studying how NNs solve algorithmic tasks, which seem like exciting progress in this direction. - arxiv.org/abs/2309.02390 - develops a theory around when NN training learns a "memorizing" vs "generalizing" solution, which depends on each solution's "efficiency" -- how much param norm is needed to get correct & confident outputs. This theory predicts grokking phenomena - arxiv.org/abs/2310.16028 - transformers can't represent turing machines, but they can can represent a smaller class of computations, described by RASP programs. This paper finds that indeed, if data is generated by a RASP-L program, the transformer will learn exactly the right function.
