Sabitlenmiş Tweet

Furong Huang
2.4K posts

@furongh
Assoc. prof. of CS at University of Maryland. Researcher in #PhysicalAI, #TrustworthyML, #EthicalAI, AI #Alignment, #AI for ALL.
If recent events with Kimi K3 have finally convinced you that you need to try and understand how the Chinese labs approach AI - and how it differs than the SF center of power - you should read this post:



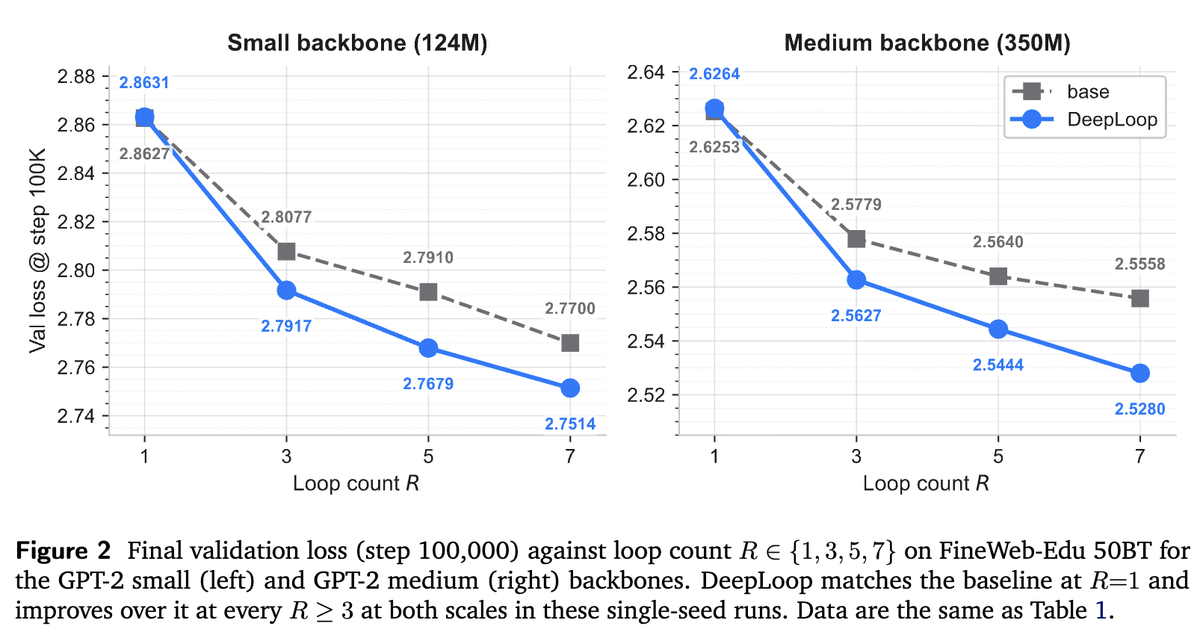
🚀New paper on Looped Transformers! Latent reasoning is fast, but struggles to match CoT-level accuracy at scale. Can looped Transformers give us both? We find: yes! A looped padded backbone turns out to be a surprisingly simple recipe that works -- It gives latent thoughts a parallel workspace that can be supervised similarly to explicit CoT. 🧵