Sabitlenmiş Tweet

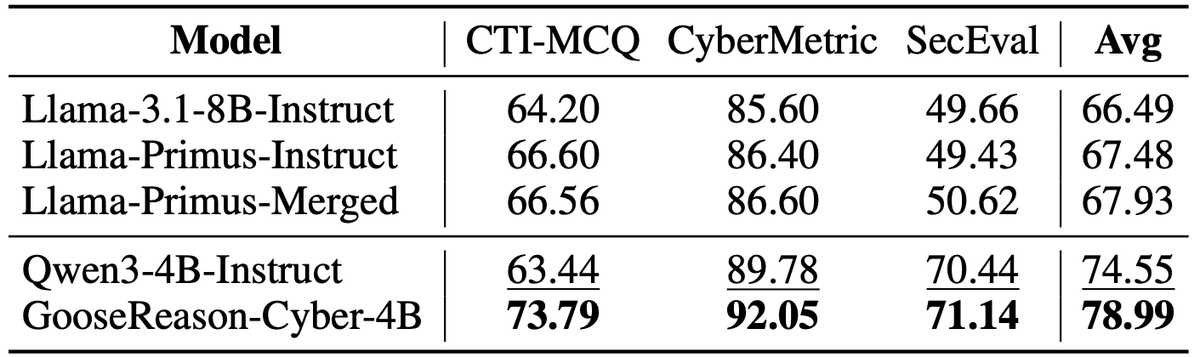
There’s growing excitement around scaling up RLVR to get continuous gains with more compute. But in practice, improvements saturate on finite training data. 😱
Introducing Golden Goose 🦢✨, a simple trick to synthesize unlimited RLVR tasks 😎 from unverifiable internet text. 🌐

English