Sabitlenmiş Tweet

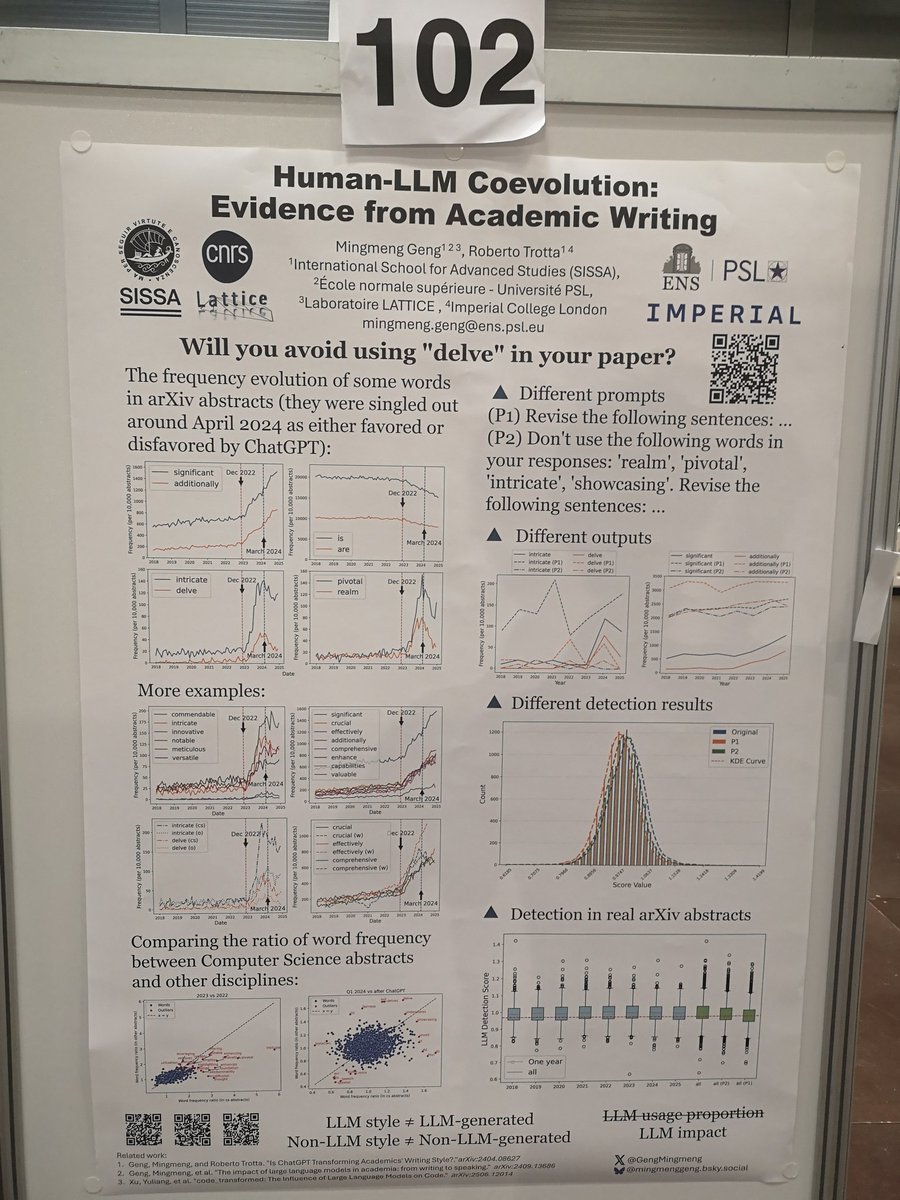
Is ChatGPT Transforming Academics' Writing Style?
From anecdotal evidence to quantitative estimate
👇👇👇
arxiv.org/abs/2404.08627
English
Mingmeng GENG
100 posts

@GengMingmeng
Postdoc @ENS_ULM & @CNRS, PhD @SISSAschool, X2017 @Polytechnique, alumnus @SUSTechSZ, ML/LLM/CSS, Survey methodology 🦋 https://t.co/X4OC2YQ034


LLM-generated text detectors are often misunderstood and misused, especially since "LLM-generated text" lacks a unified and precise definition. For more details, check out our "recent" preprint: arxiv.org/abs/2510.20810 (joint work with @tpoibeau )


ICLR authors, want to check if your reviews are likely AI generated? ICLR reviewers, want to check if your paper is likely AI generated? Here are AI detection results for every ICLR paper and review from @pangramlabs! It seems that ~21% of reviews may be AI?

At the center of everything is Wikipedia. 🔎Wikipedia articles appear in 67%-84% of all search engine results & most info boxes 🔎Wikipedia generates 43M clicks to external websites a month 🔎Wikipedia is a major component of AI training data, including The Pile training set




"Wikipedia in the Era of LLMs: Evolution and Risks" arxiv.org/abs/2503.02879… "Our findings and simulation results reveal that Wikipedia articles have been influenced by LLMs, with an impact of approximately 1%-2% in certain categories."






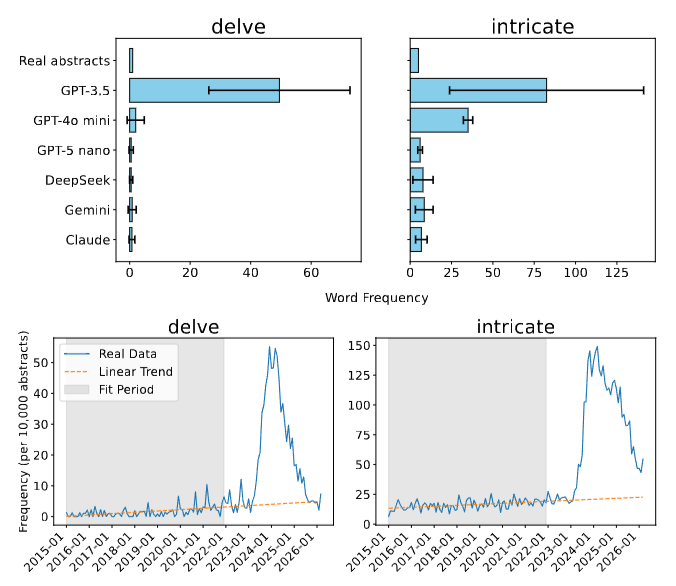
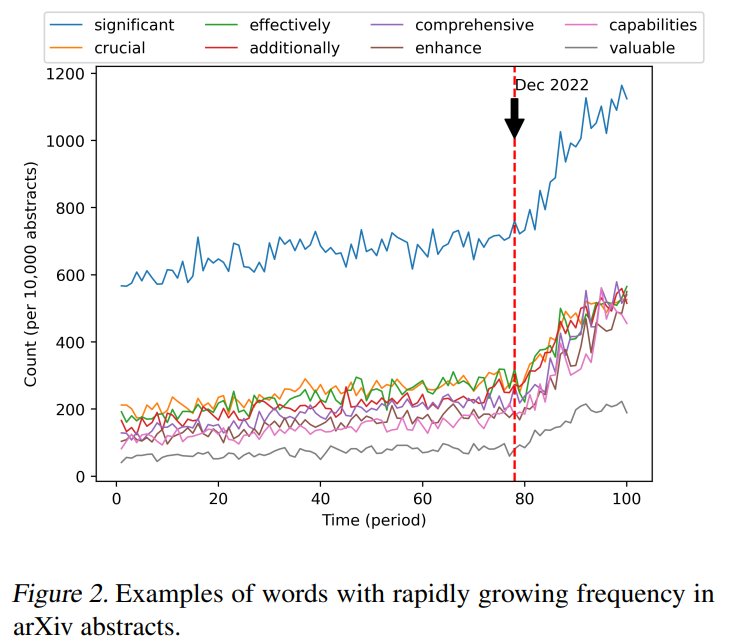
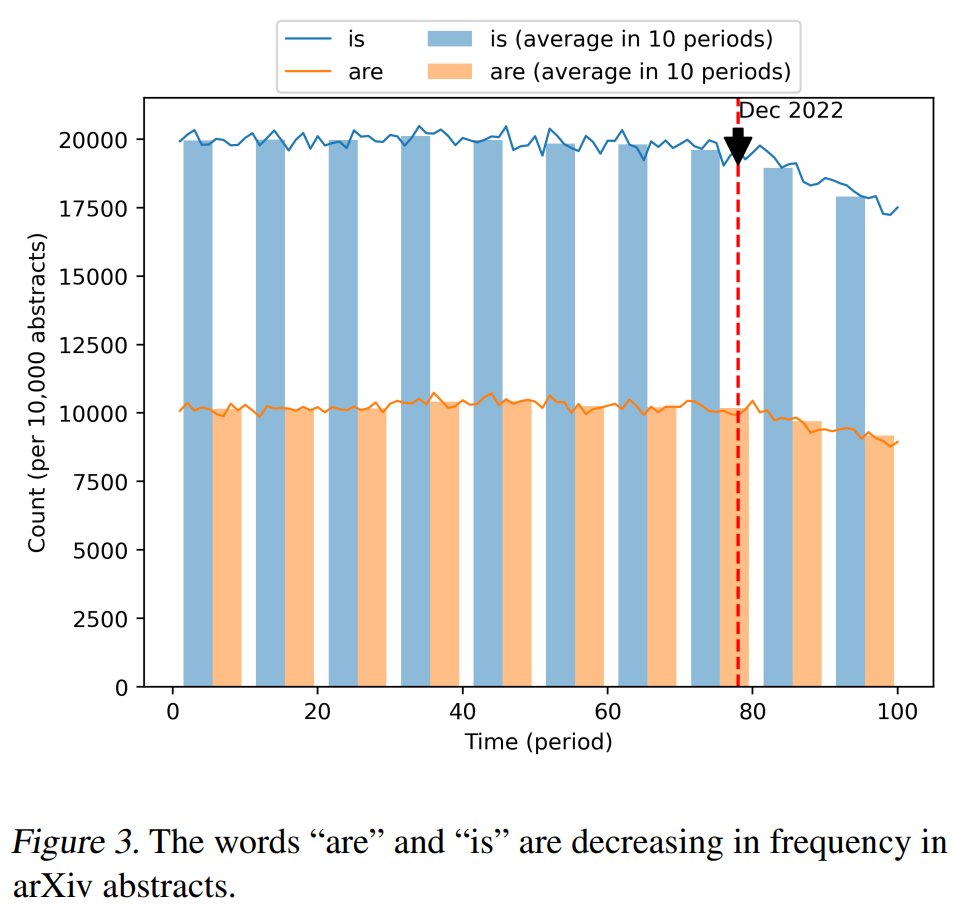
@emollick But anyway, many people are actually avoiding the term "delve" 😂 arxiv.org/abs/2502.09606

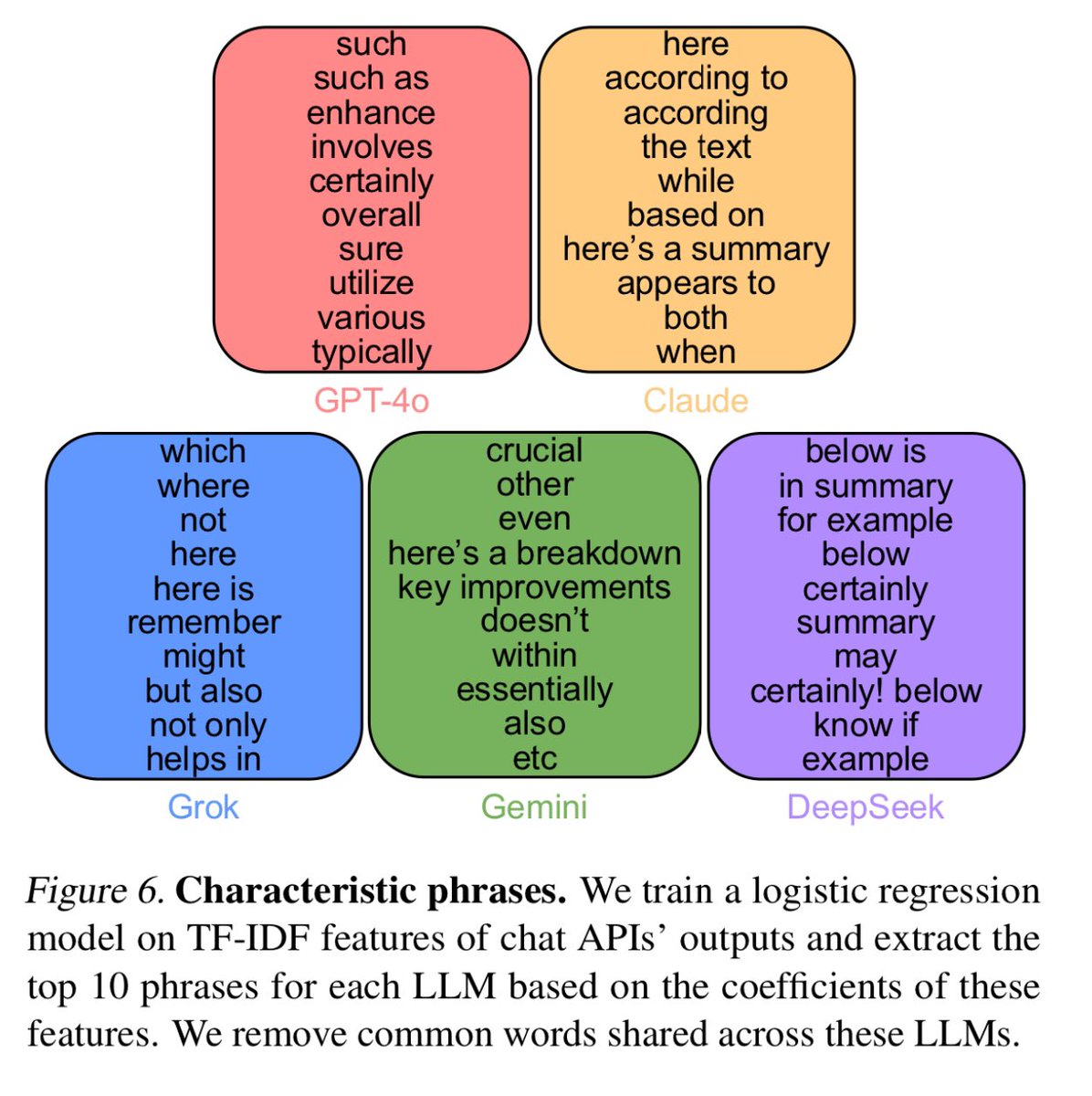

They just don't delve like they used to

Is ChatGPT Transforming Academics' Writing Style? From anecdotal evidence to quantitative estimate 👇👇👇 arxiv.org/abs/2404.08627