Zhu, Gengping retweetledi

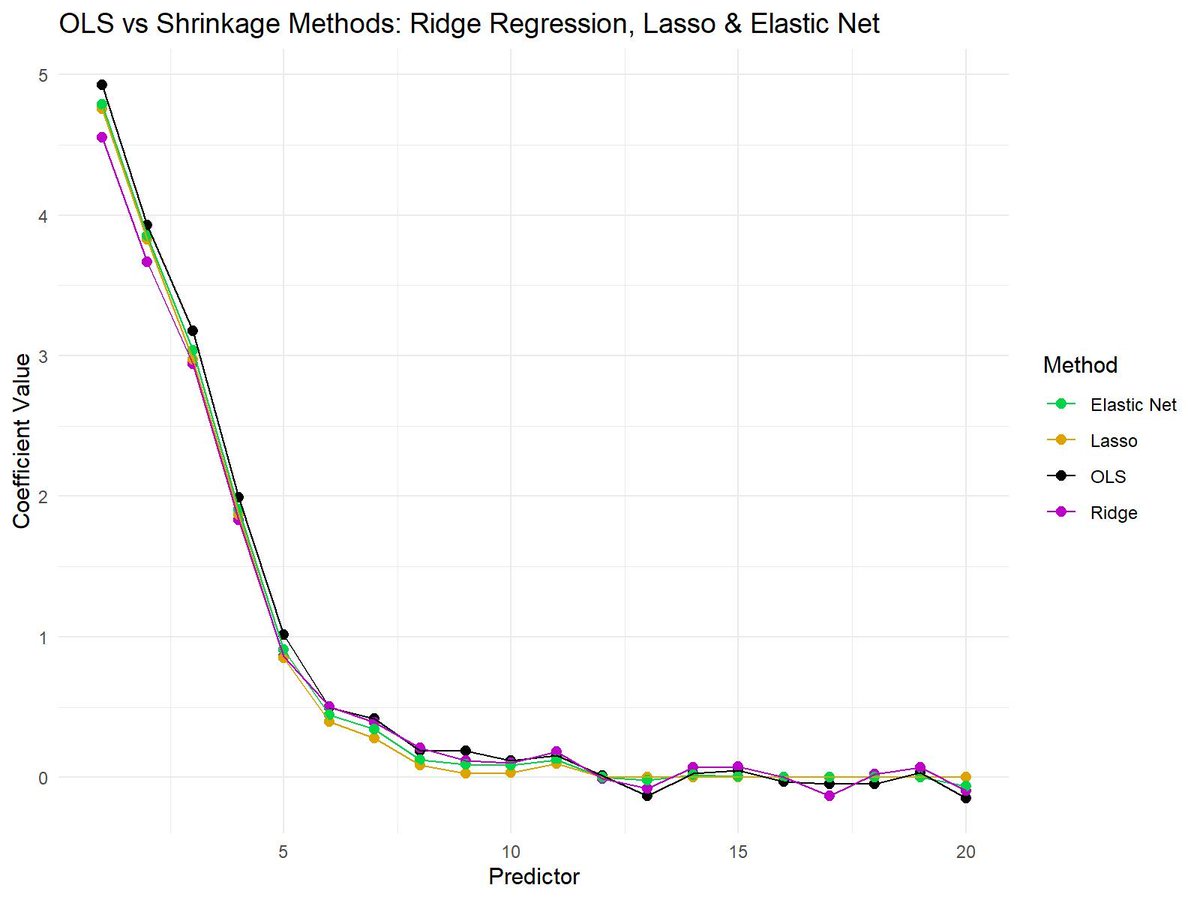
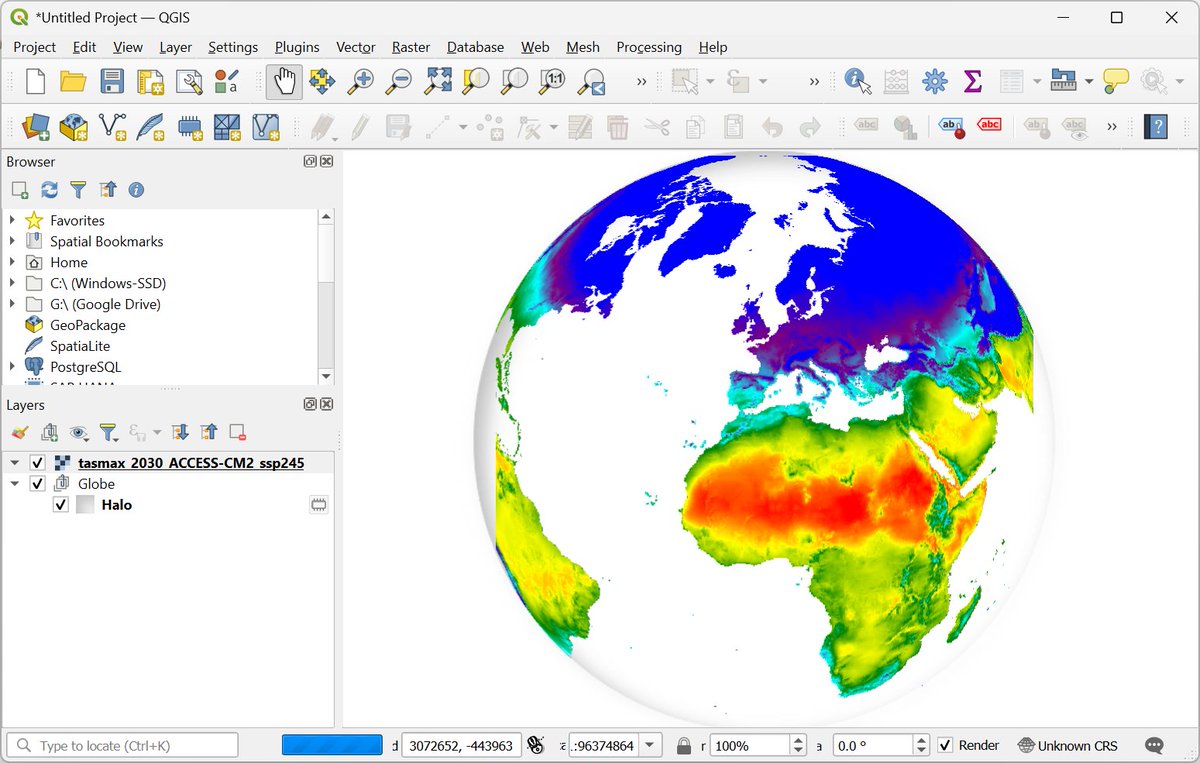
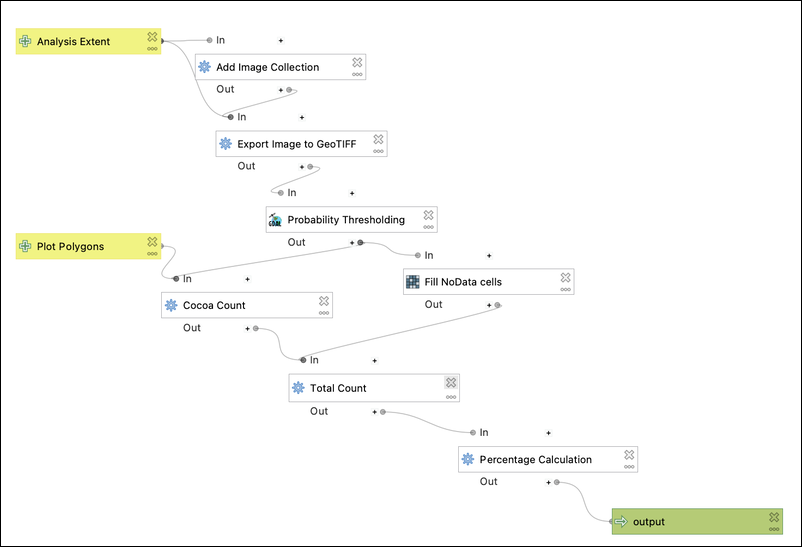
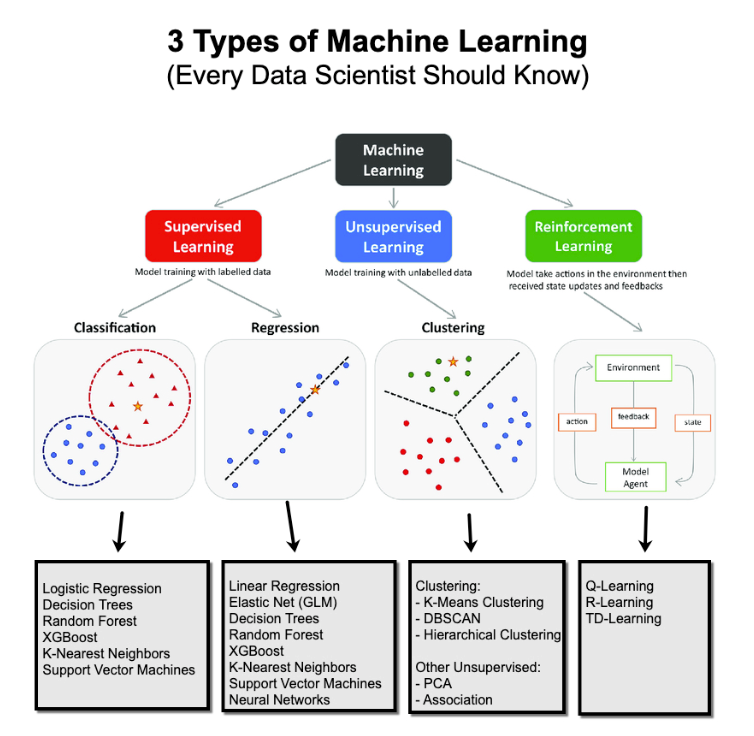
12 FREE GOOGLE EARTH ENGINE TUTORIALS FOR AGRICULTURE
🪡🧵

English
Zhu, Gengping
805 posts


@Gengping_
landscape ecology, insect niche and distribution modeling, functional insect, biodiversity and conservation, biological invasion, global change, microclimate