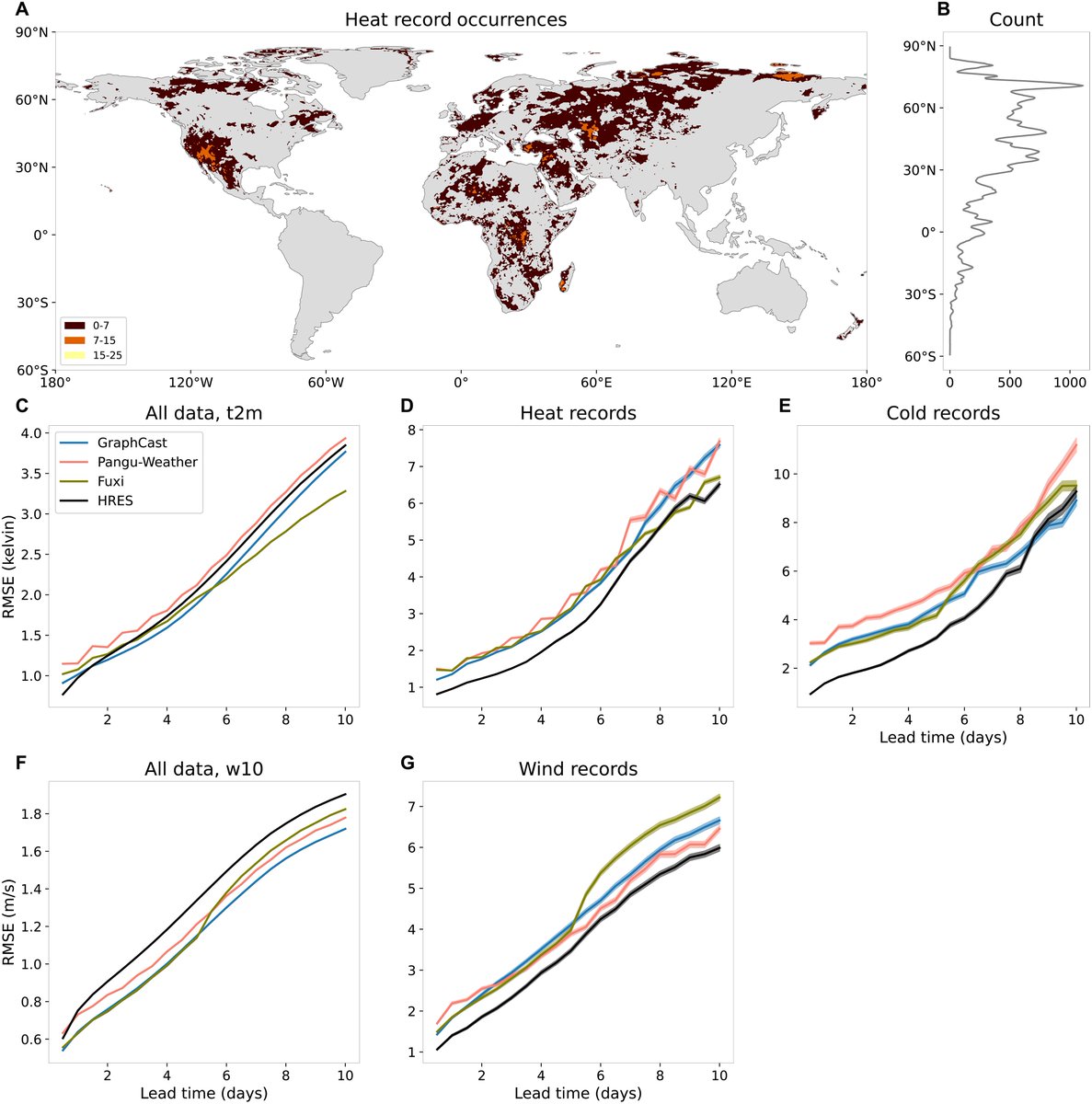
Sabitlenmiş Tweet

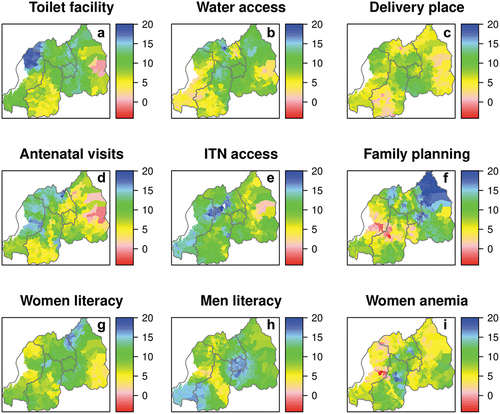
Our study in northern Province of Rwanda applies machine learning and spatial methods to uncover the granular heterogeneity of childhood stunting and their non-linear risk factor associations.
agupubs.onlinelibrary.wiley.com/doi/full/10.10…
@Uni_Rwanda @RwandaHealth @AguGeohealth #NST2 @URSwedenProgram
English