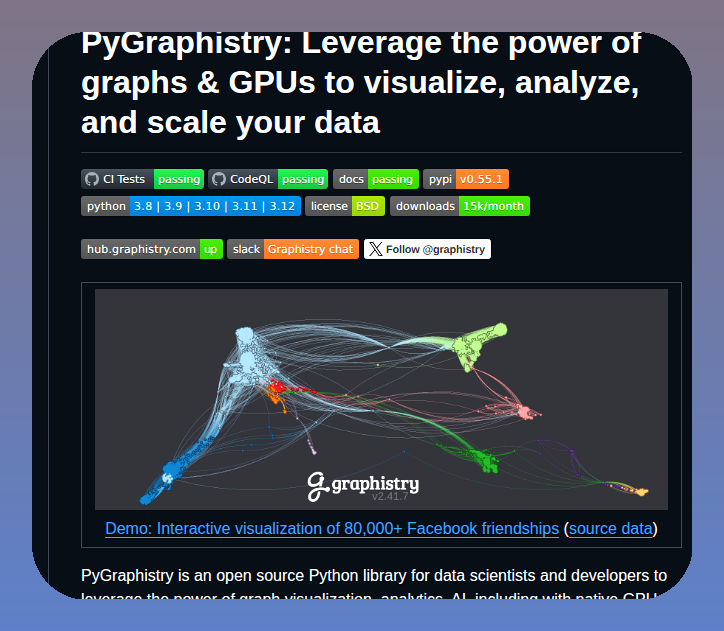
It's free to try, drop in a csv or throw a coding agent at it to get a different perspective on your data and see how it helps with trickier relationship & correlation questions
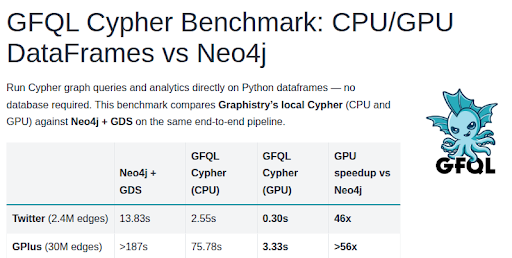
We've run the backend at 1B+ edges / second (the new open source GFQL engine), and recommend starting frontend flows at 100K edges and working up to 5M edges. Both modes are actively improving, and we're happy to work with folks who need more.
English