Sabitlenmiş Tweet

Auto-reply latency is a vendor metric.
Repeat-incident rate is the customer's metric.
Most teams track the first because it's easy, not because it matters.
English
Lovesh Grover
199 posts

@GroverLovesh
Build AI customer agents in production. Most demos ship vibes. I post eval traces, what breaks in prod, and what actually closes tickets.






Sierra is raising $950 million from new and existing investors, led by Tiger Global and GV, at a valuation of over $15 billion. We now have more than $1 billion to invest in becoming the global standard for companies wanting to transform their customer experiences with AI. We’ve never had such conviction in the opportunity for Sierra and our customers. Just a couple of years ago, we had four design partners. Now, Sierra is serving over 40% of the Fortune 50, and agents built on our platform are powering billions of customer interactions — everything from refinancing homes to processing insurance claims, returning orders, and helping people raise millions in fundraisers. We’re deeply grateful to our customers for helping show what’s possible. If you’re not yet using Sierra, we’d love to partner with you. sierra.ai/blog/better-cu…










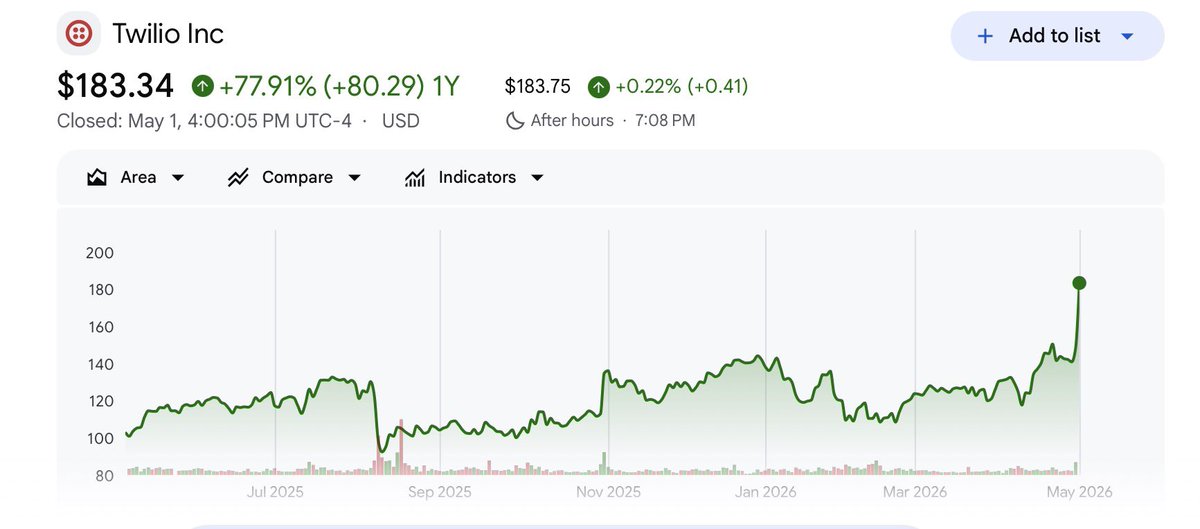
Twilio + Atlassian crush the quarter, and re-accelerate growth. Boom!! - Atlassian reaccelerates to +32% growth (!), stock up +22%!! - Twilio reaccelerates to +20% growth, stock up +19% Is the SaaSpocalypse ... over? Probably not. More a bifurcation. And make sure you also follow net new customers. Twilio for now is an AI and agentic beneficiary. It has far more competition today than pre-AI, but remains a top choice for agents and new AI products for comms. Importantly, its net new customer count has accelerated, too. Atlassian is benefitting from getting its user base to pay more for AI, which is great. But it's still under threat from agents that don't need project management, etc. And net new customer count is >not< accelerating. Let's see how HubSpot, Salesforce, etc. do this quarter Cloudflare and Snowflake should crush however. See, e.g., Twilio. We will see!