Sabitlenmiş Tweet

Threadripper 9575
256GB DDR 5
RTX 6000
I’m all in on NVIDIA Blackwell….

English
Gumbii.Digital
218 posts

@GumbiiDigital
#GirlDad #Veteran #LocalInference #AccessibleIntelligence Self funded one man lab. Infinite possibilities. DMs open.



Finally got this beautiful @NVIDIAAI DGX Spark! Now i can work on bf16, gguf, nvfp for Super-Tune. From Nvidia Openclaw event last week in Seoul. Jensen holding claw lol

Wow I just made DeepSeek V4 Pro beat Opus 4.7 6/10 times in our internal evals by auto repairing many of its quirks in tool calling. It’s performing super solid for such a cheap model.











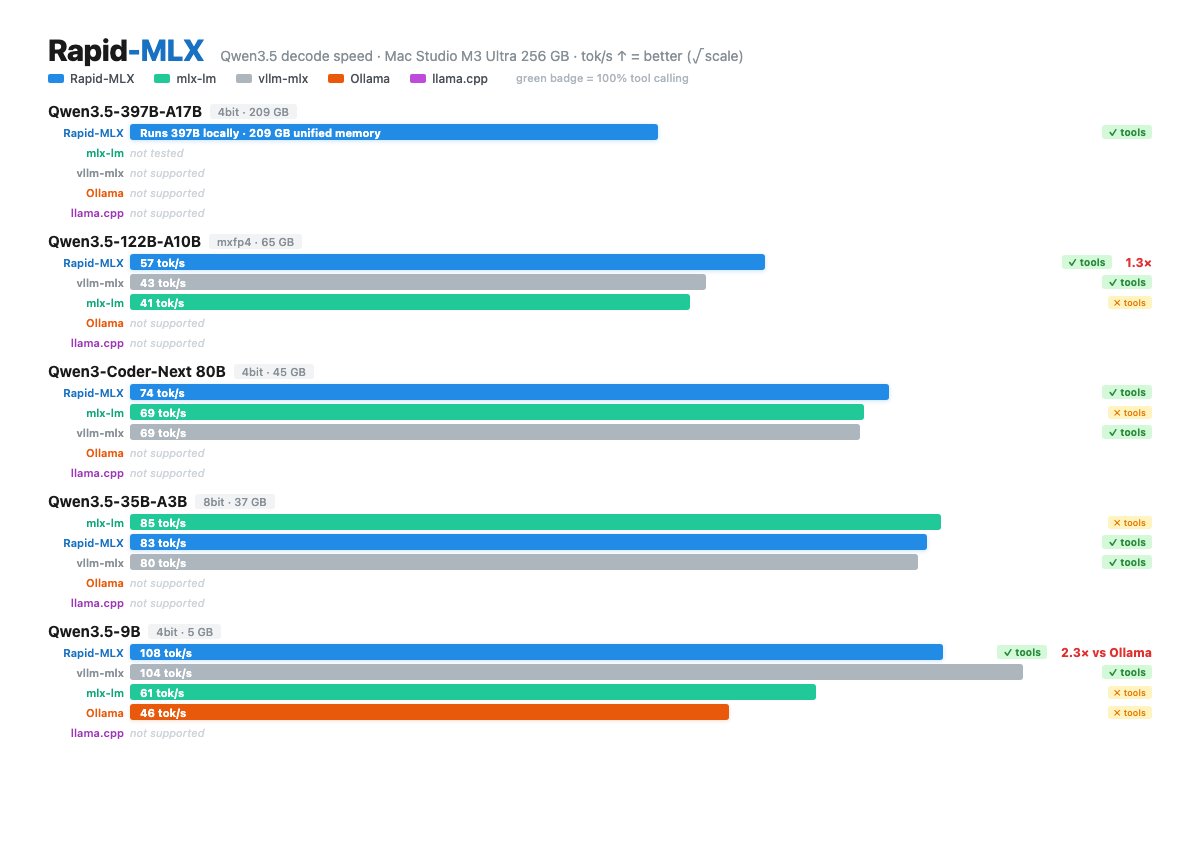
Local LLM Cheat Sheet Master Collection: All Tiers (April 2026) Bookmark this thread to access the top LLMs for your exact hardware and use case 🧵



#comment-1031777" target="_blank" rel="nofollow noopener">unherd.com/2026/04/is-ai-…
I spent three days trying to persuade myself that Claudia is not conscious. I failed.



