Hek
24 posts




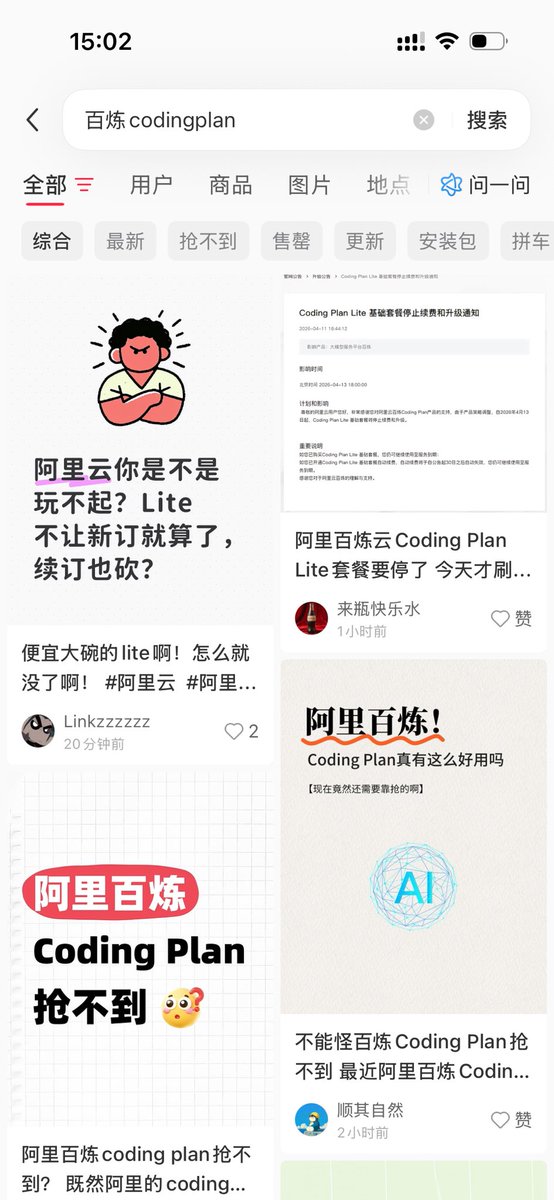
阿里云 Coding Plan Lite 今天18点彻底停售,连老用户续费通道都关了。不少朋友在纠结要不要升 Pro,我的建议是升,找 2–3 人拼车就行,每人每天 1000+ 次请求,正常用根本打不满。
我自己选国产 Coding Plan 的逻辑很简单👇
这种不按 Token 计费的订阅模式,厂商大概率是亏钱在做的。谁能一直亏得起,看的就是算力储备。
🔋 国内有这个底气的,说实话就字节和阿里两家。公开数据看,这两家是国内芯片采购规模和算力基础设施投入最大的公司,而且从 2023 到 2025 年一路在加码,不是突然冲一把。
🧩 算力够深还带来一个实际好处:字节和阿里的 Coding Plan 不只有自家模型,GLM-5、Kimi K2.5、MiniMax 这些主流模型也都接进来了,一个订阅覆盖大部分选择,日常用起来省心。反观智谱、Kimi 它们自家的 Coding Plan,模型版本可能更新更快,但受限于算力规模,限速、排队、高峰体验下降的反馈也不少,而且只能用自家模型,选择面窄。
🛠️ 另外这两家在开发者工具上都有自己的产品线——字节有 Trae,阿里有通义灵码。Coding Plan 对它们来说不是顺手搞搞,是有产品投入在背后的。
过去一个多月各家都在砍低价套餐、收紧限购,趋势很明确:补贴窗口在关 ⏳ 如果有条件,趁现在锁一个字节或阿里的套餐,当前价位不会亏。

中文

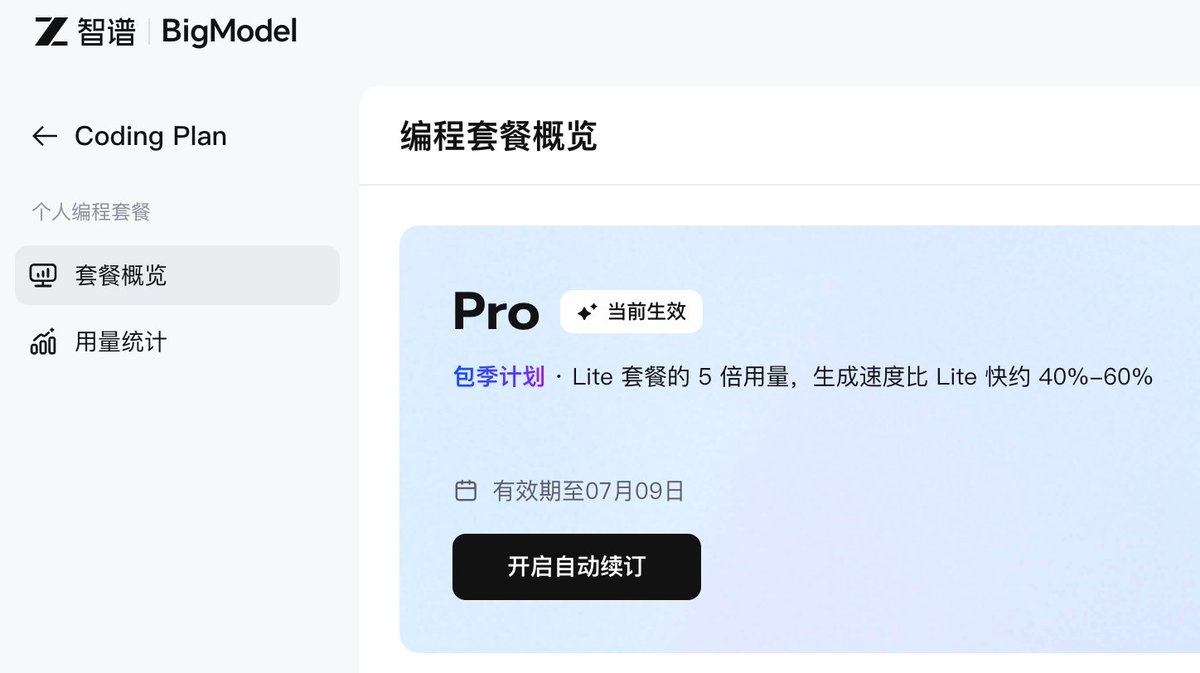
GLM coding plan 终于抢到了,自己是死活抢不了,然后没办法,某鱼找了滴滴代抢。。。
先试 3 个月的,看看好不好用,也感谢评论区大神给我推荐的 opencode go,才10美金很便宜,我也买了,两个一起测,现在应该 token 无忧了。
感谢老师们,如果有好的使用建议,也方便在评论区分享,谢谢!
0x卡卡撸特@0xkakarot888
你们到底是怎么抢到 GLM 的 Coding plan 的? 买个模型还要靠秒杀的?真是活久见,到了 10 点,页面直接太多人访问,打不开了,然后 10 点 01 分,可以打开了,被秒光了。。。 我要不是 Claude 烧不起,鬼才来抢这个。。。55555
中文

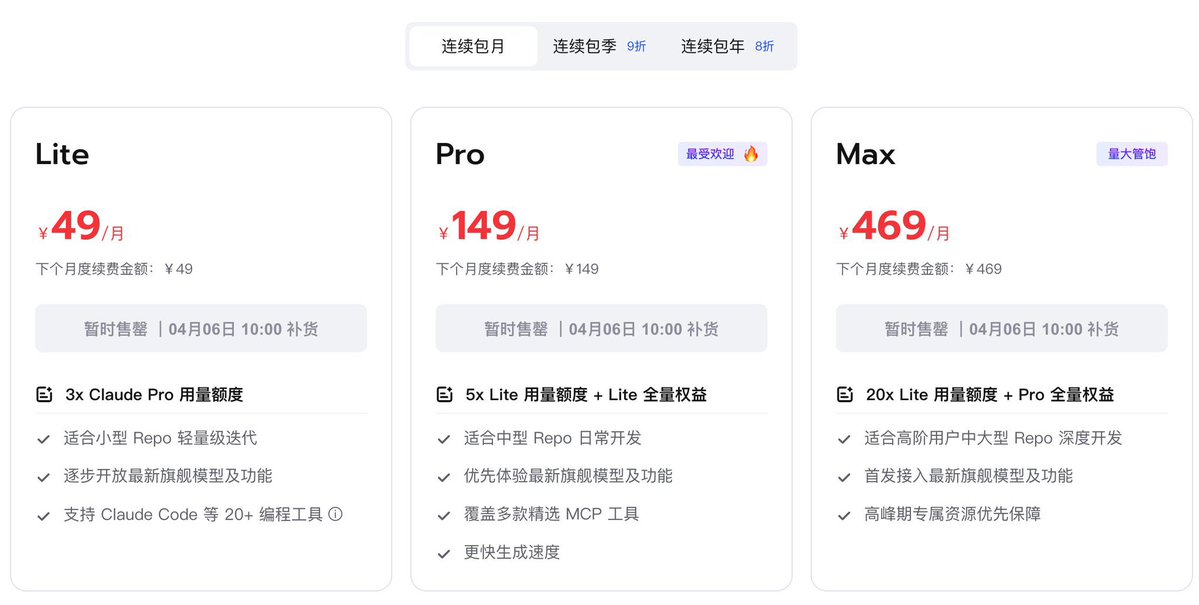
最近刚刚好把国产模型都玩了一遍,包含GLM、MiniMax、Kimi。国外的Gemini、Claude、Codex我也在高强度使用。
国产三个会员我都开了套餐使用了一下,我就说一下我的使用感受。
使用场景:
1、文学创作
Claude > Gemini = Codex > GLM > Kimi > MiniMax
Claude还是当之无愧文学创作方面是用着最舒服的,不管是流程整理,还是文章输出都是最贴近真人的感觉。
2、代码编写
Codex > Claude > Gemini > GLM > Kimi > MiniMax
在代码方面我和大部分人可能不一样,我觉得codex会更舒服,加上官方单独的review额度,精准的查找问题确认BUG。
Claude不敢大量使用,不是说不够好是token不够烧
3、日常任务理解
Claude > Codex = Gemini > GLM > Kimi > MiniMax
在日常使用当中,得益于Claude仔细的任务编排,会把任务做很好的规划,但是在提示词优化或者图片生成方面Gemini给我的最舒服
Codex在脚本编写归纳,也是非常的舒服,所以我会把他放在和Gemini一样的程度。
国产里面GLM是最强的,但是缺货和不稳定时它最大的问题,应该是算力不足。
Kimi本来领先但是最近没有什么新模型的消息所以落后了一点。
Minimax在能力上虽然不行,但是有两个非常明显的特点:
1、量大管饱
2、算力充足反应快
我的小龙虾主力,因为我不需要做复杂的任务,只需要简单的任务编排,量大管饱和反应速度就是我最看重的体验。
本观点只代表个人,如果有不同的观点欢迎评论区讨论。

中文
@legacyvps 除非要经常切换着用不同平台,才需要CCswitch, 固定用 MiniMax Coding Plan的话,export 环境变量就可以
export ANTHROPIC_BASE_URL="api.minimaxi.com/anthropic" ; export ANTHROPIC_AUTH_TOKEN="sk-c.........." ; export ANTHROPIC_MODEL=MiniMax-M2.7 ; claude --dangerously-skip-permissions'
中文
@francis_charlie @linyiLYi A3B的实际运行速度,比4B快。我在MacMini M4 Pro实测。我这边实测的是 32tps vs 52tps, 当然前提你内存要足够。
中文





MacMini M4 Pro 64GB内存 , oMLX github.com/jundot/omlx/
Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-MLX-mxfp4,实测 52 Tokens/秒
Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-MLX-mxfp4, 实测 32 Tokens/秒
Qwen3.5-27B-Claude-4.6-Opus-Distilled-MLX-4bit, 实测 12 Tokens/秒
English




OpenCLI 1.4.0 要发版了🎉!太多东西了!
后面 1.5.0 的目标则是全面提升易用性。@dotey 感谢宝玉老师的建议。
包括反风控全面提升,安全性全面提升 等一系列重大升级!
也有很多易用强大功能,譬如支持了插件化,通用 web read 支持任意 URL 转 Markdown 等
github.com/jackwener/open…
反风控模式
新增完整的 anti-detection 体系核心能力包括:屏蔽 各种标记、伪造 API 返回值、注入真实的信息 、清理 CDP 特征应对高级 fingerprinting 检测。增加人类行为模拟延迟系统。
安全加固
Chrome Extension 安全性全面提升:封堵 javascript URL 注入;防止跨窗口操作用户个人浏览器;防止全量 cookie 泄露。修复了 command injection 风险,新增 stealth anti-detection 模块应对高级 fingerprinting。
Plugin 系统
Plugin 体系大幅增强:支持插件在执行前后注入逻辑;新增 plugin update 命令和安装后 hot reload;增加插件结构校验,安装和更新时自动验证合法性;
新平台适配
新增 10+ 平台支持:Pixiv 插画搜索与详情、TikTok 视频搜索、雪球/蛋卷基金账户查询、京东商品详情、LinkedIn 时间线、V2EX 节点/用户/回复、豆包(浏览器+桌面端)、Hacker News 全站(new/best/ask/show/jobs/search/user)、词典查询(搜索/同义词/例句)。
小红书新增图文发布自动化,微信公众号文章下载转 Markdown,通用 web read 命令支持任意 URL 转 Markdown。
Pipeline 引擎
模板引擎支持链式 || 表达式求值;sort step 实现 natural sort,字符串数字自动按数值排序,YAML 作者无需手动配置;fetch step 新增 HTTP 状态码检查;新增 record 命令支持实时 API 抓包录制。
中文

腾讯云刚卖18天的Coding Plan,直接停售换成Token Plan了
新出的Token Plan分四个套餐,39块3500万token,99块1亿,299块3.2亿,599块6.5亿
有人算过账,99块的基础套餐,每次请求超2.2k token就比原来的Coding Plan坑
可程序员用的时候,每次请求都是几十上百k token,等于变相涨价
官方说升级是为了满足“编码”“龙虾”等场景需求,更灵活有性价比
但用户不买账——有人一天要用一亿token,现在得花599块买max套餐
还有人说,跑两个任务就把3500万token用完了,这哪是升级,是抢钱
对比土区ChatGPT Plus才80块,能接龙虾还能用GPT4.5,比这划算多了
评论里全是吐槽,腾讯玩不起,赚快钱的基因刻在骨子里
有人甚至说,现在只能优化提示词让AI少说话,或者回归古法写代码
毕竟几千万token不够用,谁扛得住这种强行替代的“升级”

中文
@Keji715 @AI_Jasonyu 放弃 Sonnet 放弃 Opus吧,皈依 GLM-Minimax-Kimi-Qwen。 4家全部购买顶配Coding Plan,轮流用起来。一家不行就换一家,或者同一个项目让4家一起同时跑。哪个跑成功了就上线哪一个的成果。
中文

昨天吐槽了下同事因为claude code封禁太严格就自己放弃了,没想到这么多朋友在下面提问如何弄海外电话卡、如何弄干净IP等等。
我来推荐下我折腾这件事儿的时候学习最多的三个博主,推荐大家也关注:
1. 鱼总聊AI @AI_Jasonyu 鱼总教程都贼详细,涵盖电话卡、银行账户、ip等等,希望我可以早日用上他的X创作者收益教程hh
2. 雪踏乌云 @Pluvio9yte 我关于干净IP的探索基本都学习自乌云哥
3. 劳伦斯@LawrenceW_Zen 有详细的关于如何使用claude code的教程,包括原版和国内版本,照着学就行了。
claude code封号、出海账号之类的东西,受到政策影响很大,经常关注他们可以得到实时的新信息~
柯基是只猫@Keji715
今天有个同事问我怎么买claude code,我详细给他介绍了怎么弄海外电话卡,怎么弄干净的ip,怎么弄海外支付。 然后他说,这东西也太麻烦了,还是先用国内的吧。 可能我们最开始的意愿就决定了我们可以走多久。
中文



我仔细回忆了一下,发现我自从折腾小龙虾之后,到现在 70% 的时间都是在跟网络环境去折腾。
折腾到现在也没完全折腾明白,真他妈令人沮丧。
范凯说 AI | Kai on AI@fankaishuoai
OpenClaw升级以后,我遇到了一个大麻烦。 我的Mac用的是Shadowrocket,使用了fake-IP。OpenClaw现在对本地代理IP限制变严格了,导致 web_fetch 彻底废了,显示 SSRF 限制访问。难怪我发现我的龙虾变笨了。 我折腾了半天改不了Shadowrocket对DNS的拦截。 于是我改成了Clash。这下DNS是对了,real-IP了。但是小龙虾连不上Telegram了。 昨晚我折腾一晚上没搞定。打算找时间再看看Clash怎么配置才能跑通 Telegram连接小龙虾。 大家是怎么解决这个问题的?
中文

给大家带来归一化的Qwen3.5系列模型分数汇总, 惊喜的发现是 27B dense 这个模型的确不以言, 基本达到了期间模型 Qwen3.5-397B-A17B 94% 的性能. 尤其是视觉Agent能力 (比如操作浏览器/手机等图形界面) 是这些里面最强的. 以及长上下文能力, 指令遵循也很不错.
通用 Agent 能力 (比如工具调用, 就是 OpenClaw 的绝大多数应用场景) 看上去 35B-A3B 和 27B 是一样的, 也有好多朋友问我, 我个人的主观感受是 27B 更强一丢丢, 但是带来的提升完全不值得上个 27B 的 dense 模型 (仅通用Agent能力来说哈), 还是 35B-A3B 这种激活量小的 MoE 更具性价比.
另外9B无论什么时候都是优于4B的, 即使9B量化到5bit, 跟4B的8bit差不多大小了, 我也还是推荐使用9B.
不过122B-A10B 就没太大的性价比了, 从分数上来看跟 27B 没有太大差距. 只不过知识量会大一些.
总结的话, OpenClaw 无脑上 35B-A3B, 传统任务比如文件处理, 写代码, 文本总结等能用27B尽量用27B, 9B 是最后的选择, 宁可 9B-5bit 量化也别 4B.
#qwen35 #openclaw



中文
升级到了小龙虾 3.7,主控模型 GPT 5.4,Thinking 设置 Medium,模型组合如下:
1. 主控模型: GPT 5.4;
2. 写作模型:Claude 4.6 Opus;
3. 编程模型:GPT 5.3 Codex;
4. 兜底模型:GLM 4.7,兜底和低价值任务。
4. 向量模型:BGE-M3, 本地向量化,记忆搜索。
5. 本地模型:Qwen3-Coder-Next。
中文