Surge AI
687 posts


Surge AI
@HelloSurgeAI
Our mission is to raise AGI with the richness of humanity — curious, witty, imaginative, and full of breathtaking brilliance.


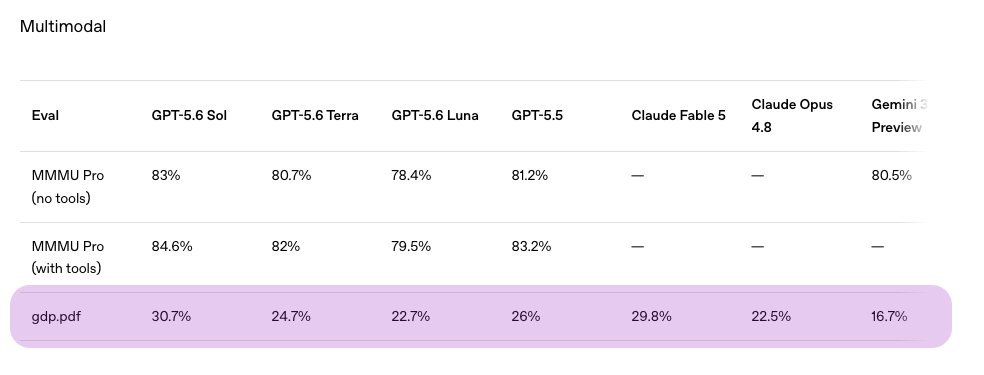
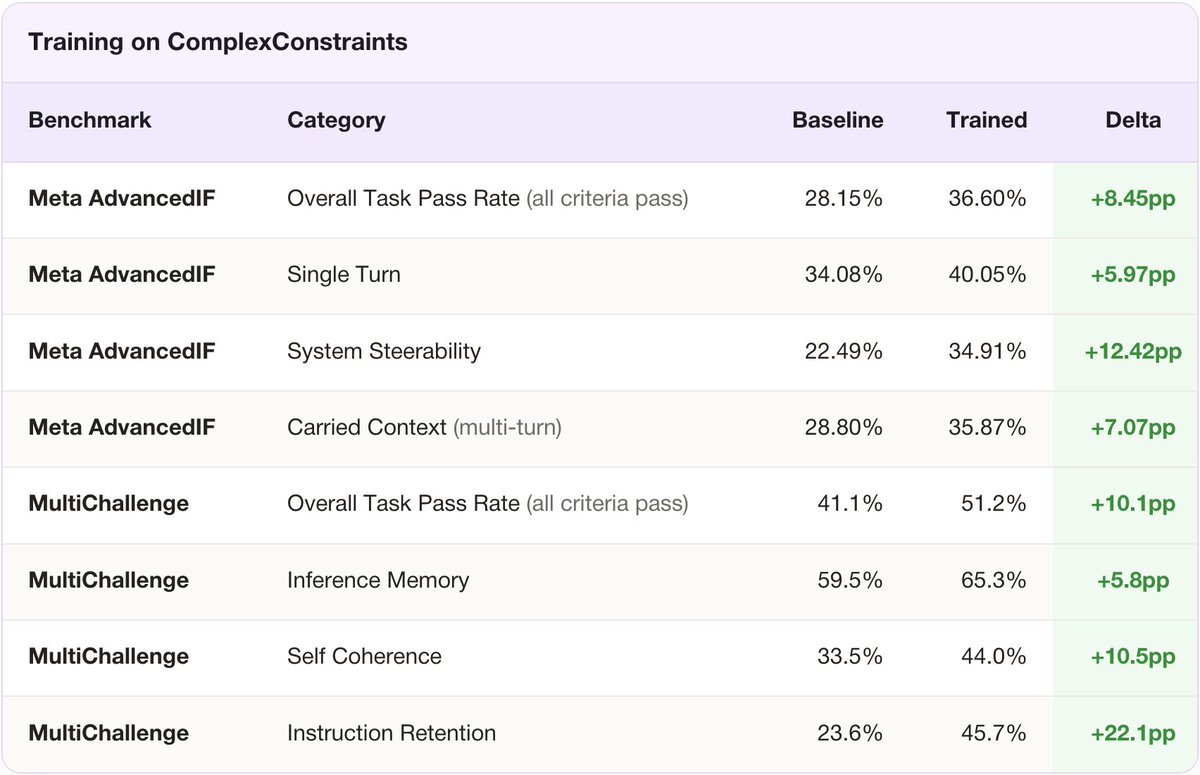



Surge AI just made the Forbes AI 50 list. 99% of the rest of the list raised billions in VC. We got there with $0. We didn't do it by building engagement slop and chasing DAUs. We didn't do it by rewarding sycophancy over truth. The standard Silicon Valley playbook — raise billions, blitzscale, worry about the effects of what you're building later — forces you to cut corners, compromise your principles to hit quarterly targets, and optimize for hype instead of substance. We chose a different path. We did it by doing the most unsexy work in the industry: building the school for AGI. Hiring the world's top doctors, engineers, attorneys, scientists, and writers to teach models how to actually think. Designing the curriculum that determines what intelligence becomes. Grading models on the standard of real work, not vibes. Building the full education — reasoning, wisdom, creativity, and taste — not just the standardized exam. You don't need hyper-growth VCs to build the world-changing things that only you could build. You just need an uncompromising commitment to your principles and work so good that your customers keep coming back. Years ago, we bet that AGI deserves more than a textbook education. We bet that the only way to build true intelligence is to raise it on the best of humanity — on the brilliance, rigor, and taste of the most talented experts in the world. We bet that independence and patience would beat headlines and hype. We bet on our technology and the quality of our product. We bet that researchers would notice and care. You can choose a different path. We're just getting started. forbes.com/lists/ai50/