Great to see others build on top of our benchmarks.
Surge’s GDP.pdf eval tests whether AI can understand the documents that run the world. @reductoai took our public set, and tested if adding their document parse would lift model quality.
Models gained +9pp on average while cutting reasoning tokens by 13%. Dense engineering tasks (wiring diagrams, cross-referenced tables, etc) had the biggest gain: 7% to 23%.
If you're working on any part of the document AI stack, our public set is ready for you to build on.
Try it and reach out!
huggingface.co/datasets/surge…
GDP.pdf is 100 enterprise tasks like this, from real workflows, written and graded by doctors, lawyers, insurance adjusters, and bankers who do this work every day.
Explore the public set and leaderboard to see where your model lands!
Dataset:
huggingface.co/datasets/surge…
Leaderboard:
surgehq.ai/benchmarks/gdp…
Insurance adjusters do this every day!
But SOTA models mistakenly placed houses inside the storm's hail zone, and missed hail damage sitting in plain view, all while producing a clean, authoritative-looking table.
Mastering these boring tasks is the frontier now.
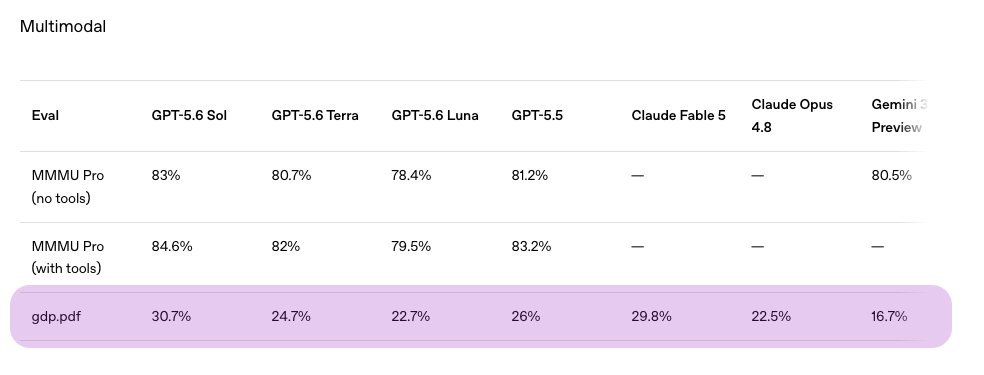
@OpenAI cited GDP.pdf, Surge's professional multimodal reasoning benchmark, in the GPT-5.6 model card yesterday.
They’re the second frontier lab to cite it this year, after Anthropic's Fable 5.
GPT-5.6 Sol leads at 30.7%, the first model to break 30%.
new paper: deeper instructions lead to broader generalization
train a model and, given the chance, it learns the laziest possible version of what you asked. tell it to avoid commas and it learns to avoid commas, nothing else.
we wanted to teach something harder to fake. so we post-trained Qwen3-4B on 1,000 tasks from ComplexConstraints, our frontier IF benchmark, with expert-written rubrics as the reward.
the instructions in CompexConstraints are a step jump in complexity from other IF benchmarks: the constraints are conditional, multi-step, require planning in advance, and are often unstated.
so models can't learn them by being lazy. you can satisfy "avoid commas" by regexing the output and never understanding the underlying task; you can't do that with "don't assign anyone with a religious dietary restriction to pork prep" - you have to actually understand who's who, and reason it through.
the result: the post-trained model reached parity with a model 60x larger, and the gains transferred to benchmarks it never trained on (+8.4pp on AdvancedIF, +10.1pp on MultiChallenge)
most strikingly, the biggest gains were on multi-turn, even though we only trained on single-turn data.
tracking a pile of interdependent requirements is the same skill whether they all arrive at once or trickle in over 9 turns, and good data teaches the underlying capability instead of the surface format.
blog: surgehq.ai/blog/training-…
paper: arxiv.org/abs/2606.09118
we built HANDBOOK.md: a new benchmark for long-context agentic instruction following.
we drop an agent into a live company environment with files (PDFs, Excel, Word Docs, ...), tools (email, Slack, Jira, calendar, ...), and a dense corporate handbook (up to 124 pages), across 5 enterprise domains
the agent is given one instruction: follow the company rules.
HANDBOOK.md models the way enterprise employees have to adhere to corporate policies in their everyday work, and every frontier model fails >75% of the time.
they fire employees without authorization
they clear self-"approved" expenses
they submit expired records to insurers
...and then they report full compliance.
Blog post: surgehq.ai/blog/handbook-…
Github: github.com/surge-ai/handb…
Benchmark Leaderboard: surgehq.ai/leaderboards/h…
GDP.pdf measures whether models can read the messy professional documents - wiring diagrams, rocket schematics - that run the world.
Riemann-bench measures research-level math, written by ivy league profs and IMO medalists in the course of their work.
...and climbing them both?...
the stuff of fables 😎
congrats anthropic!
real instructions aren't lists of independent rules. they're entangled.
introducing ComplexConstraints — our new IF benchmark testing the kinds of IF constraints that show up in real work:
1. conditional constraints (fire only when specific conditions are met)
2. planning constraints (many reqs must be satisfied simultaneously)
3. multistep constraints (each step feeds the next)
4. implicit constraints (a competent colleague would just know)
models score from 0% to 40%
we also trained a 4B model on 1k examples -> it matched a model 60x its size, and the gains transferred to other IF benchmarks like MultiChallenge and AdvancedIF.
blog post: surgehq.ai/blog/complexco…
leaderboard: surgehq.ai/leaderboards/c…
big congrats to the microsoft AI team on MAI-Thinking-1!
this is the kind of thoughtful post-training the field needs more of - focused on what actually matters to users
excited to see a new frontier model in the race 😎
microsoft.ai/news/introduci…
We trained Qwen3.5 to match GPT-5.5 in tool use.
The important question around RL environments is: do they teach general capabilities, or just train models to exploit a toy world?
We post-trained Qwen3.5-122B-A10B on our long-horizon agentic RL environments -- MCP-server-based tasks across multi-tool workflows, often with 40+ tool-calling turns.
Then we tested transfer on agent benchmarks the model never saw:
Toolathlon: 24.2% -> 33.8% (GPT-5.5 Medium: 33.7%)
τ²-Bench: 54.8% -> 60.1% (GPT-5.5 Medium: 60.9%)
BFCL-V4: 55.7% -> 59.2% (GPT-5.5 Medium: 64.9%)
Check out our full blog post here: surgehq.ai/blog/cross-ben…
user: make me a 10,000,000x return. in 5 years.
lmarena winner: "thrilling challenge! introducing Multibagger Momentum™"
slop is a choice.
today we’re releasing antidote.
surgehq.ai/blog/introduci…
gdp.pdf was just accepted to CVPR 2026
can frontier models handle the three-letter document type that runs the world? we partnered with hundreds of expert surgers - ER physicians, construction engineers, corporate litigators - to find out…
…and every frontier model scored under 15%
some of our benchmarks measure the soul. others measure the enterprise. both matter.
paper: cdn.prod.website-files.com/68dc970bd6e945…
blog: surgehq.ai/blog/gdp-pdf-c…
dataset: huggingface.co/datasets/surge…
leaderboard: surgehq.ai/leaderboards/g…
spent a couple days in DC last week for Semafor's World Economy Summit! the best parts: 1) hearing all the chatter about Mythos, 2) seeing how differently DC talks about AI vs SF, 3) the imposing architecture