Sabitlenmiş Tweet

What’s the best technology that doesn’t exist yet? Most funding is pouring into AGI right now. But there's much more being built that could be truly transformative, and almost no one is paying attention.
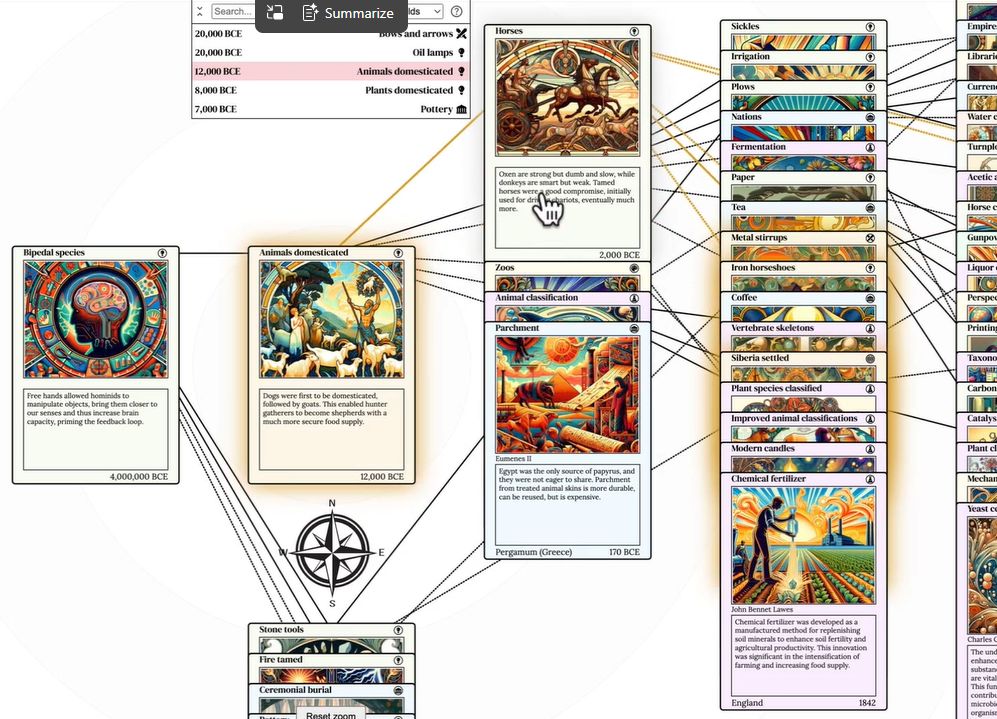
Some technologies can guide funding, coordination, and what feels possible long before they're built. The internet did; so did the Human Genome Project; AGI is doing it now. @michael_nielsen calls these hyper-entities.
We went looking for new ones in 100+ podcasts, worldbuilding scenarios, and essays from Existential Hope, a project that has been mapping positive futures for over 5 years.
From 300+ ideas, here are the 10 we’re most excited about:
• Chemputing – Chemistry made programmable: write code, a robot runs the reaction, same result everywhere.
• Machine-readable science – Scientific publishing made usable to AI, so that it can verify claims and build on findings directly.
• Open science networks – Infrastructure that rewards scientists for sharing data and replicating results, not just publishing first.
• Epistemic stack – A system that lets anyone trace a claim (in science, policy, the news, etc) through chains of evidence.
• Fiduciary AI assistants – An AI assistant that is bound to you and legally required to act in your interest.
• Immune-computer interface – Continuous real-time monitoring of your immune system.
• Conflict de-escalation protocol – AI mediation that finds fair outcomes before disputes escalate.
• Deep fission – Car-sized nuclear reactors built to be highly safe and to run autonomously for decades, installed underground.
• Digital twins – Living simulations of cities, ecosystems, supply chains, and other complex systems to test decisions before committing.
• Interspecies communication – Decoding what other species communicate to each other.
More info in the reply ↓

English