
notice_u
2.6K posts



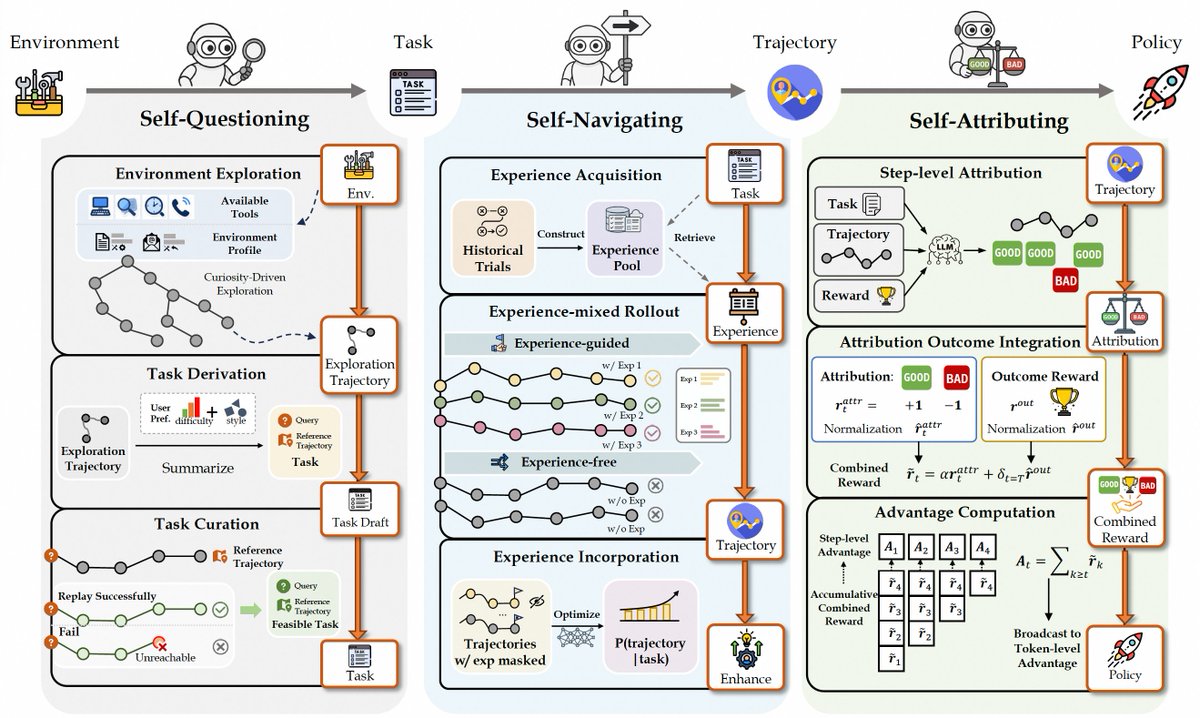
阿里最新发了一款端到端的“自进化”智能体训练框架:AgentEvolver,提问、导航、自归因三种机制一套系统
让智能体在环境中持续自我迭代,无需人工不断标注数据
7B的AgentEvolver在AppWorld上avg@8 达到32.4%,BFCL-v3上57.9%,平均成绩45.2%,超14B基线
14B版本再进化提升到了平均成绩 57.6%,最佳点 73.1%
后续会支持多智能体协同进化,以及“问-寻-归因”三阶段闭环联合优化
#AIagent #AgentEvolver
中文

文本大模型也能去马赛克了???
你有没有遇到过大模型输出到一半, 然后拒绝请求的情况?
没错, 你遇到模型内部审查了。当检测到敏感信息后模型机制就会停止输出。然后,越狱工具来了,就这个Heretic,记不住repo名字没关系,这个单词就是异教徒的意思哈哈哈哈
用法也很简单,先安装: pip install heretic-llm
然后直接在命令行运行 heretic {huggingface 模型名称} 即可. 没有任何参数需要设置. 执行速度的话, 8B 模型在RTX 3090 上需要大概45分钟. 算下来大概1B需要6分钟的样子?
另外无论是 dense 还是 MoE 模型都支持.
话不多说,地址:github.com/p-e-w/heretic

中文

想看“第一手”文献,却不知道门朝哪开?
如果你厌倦了二手资料,渴望触碰“原始档案”,这扇“任意门”直通全球最大的学术档案库:JSTOR。
虽然它以付费期刊闻名,但它的“开放获取 (Open Access)”和“公共领域 (Public Domain)”板块,才是图书爱好者真正的金矿。
🌍 全球视野:收录了来自哈佛、剑桥等顶级图书馆和博物馆的数百万份一手资料。JSTOR 与全球的图书馆和出版商合作,让用户能够免费访问、发现学术资源。
🖼️ 高清图像:海量的艺术品、地图、手稿、照片和早期印刷品的高清扫描件,全部免费查看和下载。
🎓 无需校园网:它的 OA 内容完全开放,无需登录,没有“网盘党”担心的速度限制。
可通过 JSTOR 检索大量开放获取期刊,包括美国早期出版物及超过 143 年前的国际期刊文章,所有用户都能免费阅读。
成千上万本开放获取电子书,来自 Brill、康奈尔大学出版社、伦敦大学学院出版社、加州大学出版社等顶尖学术机构,所有图书馆及用户均可免费获取。
收录了由教师与专家推荐、来自 140 多个政策研究所的研究报告(超过34000份),全部开放获取。
about.jstor.org/oa-and-free/

中文



搭建 n8n 工作流是不是拖来拖去很烦?
刚看到了个新的开源项目BubbleLab,机智的在AI工作流前面增加了AI生成功能,只要描述你想要什么工作流,AI就能自动帮你搭建。
图片上就是我使用prompt "帮我抓取reddit 的 r/localllama 频道的当天 top 10 的帖子并总结" 生成的工作流。
另外项目是开源的,完全可以部署在本地然后使用你想使用的大模型来操作。这个框架还有个好处就是支持把工作流完全导出,方便迁移。
地址:github.com/bubblelabai/Bu…

中文

当公司的咨询业务非常大,每天都要处理大量重复性咨询,如果要实现 24 小时电话服务,人力成本更加高。
来自微软开源的一个项目 Call Center AI,帮助我们用 AI 完全替代人工客服,既能接听来电也能主动呼叫。
基于 Azure 和 OpenAI GPT 构建,支持实时语音对话、多语言交流,还能自动记录通话内容和生成待办事项,甚至可以处理敏感数据并遵循 RAG 最佳实践。
GitHub:github.com/microsoft/call…
主要功能:
- 支持接听和拨打电话,配备专属号码,提供 24 小时不间断服务;
- 实时流式对话延迟低,断线后可恢复,所有对话自动存储;
- 支持多语言和多种语音语调,用户可通过短信提供或接收信息;
- 基于 gpt-4.1 实现深度理解,能处理私密数据和内部文档;
- 自动生成待办清单和结构化理赔数据,过滤不当内容;
- 云原生无服务器架构,可根据使用量弹性扩展,优化成本。
通过部署到 Azure 上即可使用,也可以在自己本地服务器上部署,适合保险、电商等需要大量电话沟通的行业。

中文
阅读国外专业的学术论文,光理解内容就挺费劲了,如果还要总结内容、生成思维导图,更是让人头疼。
可以试下,Paper Burner X 这个开源工具,集文献识别、翻译、阅读与智能分析于一体,在浏览器上打开就能用。
一个纯前端实现的 Agent 智能分析系统,可自主调用工具进行多步推理,还能翻译长论文,保留公式、图表等复杂格式。
GitHub:github.com/Feather-2/pape…
主要功能:
- 支持 PDF、Word、PPT、EPUB 等多种格式导入和处理;
- 极速并发翻译,长论文仅需数十秒,保留原文格式;
- 前端 Agent 智能分析,支持复杂问答和信息提取;
- 自动生成思维导图、流程图和结构化文献矩阵;
- 原译文智能对齐对比,支持高亮标注和目录导航。
直接访问在线版或部署到 Vercel 即可使用,所有数据存储在本地,保护隐私的同时无需安装任何软件。

中文

n8n+FastAPI=王炸!免费开源我年入7位数的小红书AI矩阵工作流 🧵
以暑假课引流的项目为例,分为4个部分:
1. 定时触发、多角度生成选题
好的选题,就已经决定了一半的流量。所以这个工作流想要有效果,起点就是能源源不断的产生能带来流量、甚至直接跟「转化」相关的选题
2. 逐个生成笔记内容,包括标题、正文
这个比较好理解,直接用AI根据选题来生成就好了,没什么难度
3. 后端Python把Markdown转成备忘录图片
当时我用的是Cursor开发了一个脚本,调用playwright自动化框架去md2card,把内容转成备忘录的图片
然后把脚本封装成fastapi,提供接口给n8n调用
要说整个流程的难点,或许就在这里,怎么解决图片生成的问题,接下来会重点讲。
4. 笔记内容和图片上传飞书
最后这里就是数据存储了,顺便还把内容同步一份到了公众号矩阵的库里,一鱼两吃美滋滋。
唯一的卡点在多张图如何放到一个单元格里,这也就是个经验值,但不懂的时候也是花了好多个小时摸索的

饼干哥哥AGI(2.0)@bggg_ai
Vibe Marketing 现在存在 至少 10倍的效率套利机会,关键在于怎么布局。 实操复盘:用「AI小红书矩阵」做 k12 教培,16个月从0干到7位数营收 主要分成三个阶段: 1、0-10万 | 手工作坊,跑通内容模型 2、10-50万 | 矩阵化扩张与阵痛 3、50-100万+ | 成熟的Vibe Marketing系统,实现「人机协作」 在操盘过几个小红书项目后,我发现小红书与其他平台有一个根本不同:本质上是一个基于“内容模板”和“信任节点”的推荐系统。 这意味着,一个能被验证成功的笔记范式,可以被大规模地、系统化地复制,并且用户对“素人感”内容的信任度极高。 这对我来说是一个巨大的机会。它不是一个需要持续内容创新的平台,而是一个极其适合用工程化、系统化思维来获取流量的平台。 但我还在上班,资源十分有限,充其量算是野生团队,无法像“正规”公司那样去规模化复制。我们唯一的出路是用系统对抗系统,用极高的效率和杠杆去竞争。 这正是我后来理解的Vibe Marketing的核心:一个核心主理人,利用AI Agent和自动化工作流,构建一个能替代传统营销团队的增长引擎。 第一阶段:0-10万 | 手工作坊,跑通内容模型 核心目标: 手动跑通“内容→流量→私域→转化”的最小闭环,作为后续AI落地的「知识」 从 0 接手一个项目,我认为没有必要去做过度的调研分析,我的逻辑就是「干中学」: 先找一批账号来关注,然后去刷他历史的爆款内容,并从中总结出爆款的逻辑后,做「像素级模仿」。 有人可能会说:不就是抄吗? 你别说,还真不是抄,抄是形式上的拙略模仿,短期能获得流量,但不见得转化率高;像素级模仿是内化后的创新,有流量的同时,也能建立垂直IP,确保转化率。 这个阶段我们拿到了两个核心认知: 第一,小红书账号本身就是消耗品,引流私域的号生命周期大约半年; 第二,“天龙人号”的存在,意味着规模化的关键可能不是内容创新,而是如何批量找到或养出这种高权重的账号。 这个认知,是我后续所有策略的基石。 第二阶段:10-50万 | 矩阵化扩张与 Vibe Marketing的初探阵痛 有了第一阶段的经验,我们迅速制定了下一步的打法: • 横向: 铺设一个50个账号的池子,用赛马机制,一个月内没有客资的号直接注销重来。我们的目标很简单,就是刷出来下一个“天龙人号”,只要成功一个,就能保住业绩的60%。 • 纵向: 单个账号的内容生产,正式引入AI创作,将手工作坊的经验流程化。 本阶段小结: 我们是24年4月开始的,到12月底,GMV到了48万,算是完成了第二阶段的目标。 从10万向50万突破的过程中,我们深刻体会到:增长的本质是复制,而复制最大的瓶颈是「人」和「工具」的协同。 策略再好,如果没有标准化的流程和稳定易用的工具,靠堆人不仅无法实现增长,反而会制造混乱。 说实话,这个阶段,我们虽然业绩在增长,但团队内部效率低下,我个人也极其疲惫。 第三阶段:50-100万+ | 成熟的Vibe Marketing系统,实现「人机协作」 意识到系统的问题后,我花了几天时间,用n8n+飞书,把自己花了几个月做的东西给替代了。自己革自己的命了属于是。 新的AI工作流完全跑通了我们设想的全流程: 1. 人工寻找对标笔记后,自动同步到飞书。 2. 自动解析笔记的标题、正文,包括图片上的文字(因为多数是备忘录,内容都在图片里) 3. 根据我们设定的模板,将对标笔记按我们的内容逻辑二次创作。 4. 自动生成封面图。 5 .同步到飞书,比特浏览器的 RPA 工具 Automa 读取飞书后发布到多个账号上。 整个系统是由多个系统组成的 然而,系统跑起来后,我们又遇到了更高级的坑,这也让我产生了新的反常识认知:自动化虽然减少了执行的时间,但对管理提出了更高的要求。 坑一:没有“监督”机制,招助理是在浪费钱。 我一度过度相信这套“硅基工作流”,以为让助理无脑发布就行。直到我检查账号时才发现,很多笔记封面是AI生成错误的,助理并没有按要求删除;更严重的是,很多笔记甚至根本没发出去,助理却每天在群里汇报“已发送”。这件事之后,我们立刻安排一个合伙人专门负责检查。 坑二:没有“反馈”制度,系统在“闭门造车”。 我们的内容模板是有时效性的,暑假规划的模板,开学后就没人看了。但我没有在一线,助理又没有建立反馈笔记数据的机制,导致我们那套高效的自动化系统,一直在生产过时的、无效的内容。 现在的解决方案是: 要求助理每周固定整理当下的热点内容,形成新模板的提案,再由我来判断是否适合开发成新的工作流程。 本阶段小结: 到今年暑假8月份,累计收入突破7位数。 这个业务是我真正从0开始操盘项目,并完整落地AI应用的过程。 它我深刻感受到AI不是魔法,它只是效率的放大器: AI的价值不在于替代人,而在于提供杠杆。 一个真正能打的自动化系统,是“高效的AI工具” + “标准化的流程” + “严格的监督反馈机制”三者的结合。 Vibe Marketing 现在存在 至少 10倍的效率套利机会,关键在于怎么布局。 未来,营销领域的竞争优势,将不再是谁拥有更多的投手或设计师,而是谁能构建出更聪明、更高效、能自我优化的自动化工作流。
中文
📢兄弟们,这个厉害了
Google 推出 File Search Tool(文件搜索工具)
这是一个完全托管的 RAG 系统
直接内置在 Gemini API 中
简单来说,就是:RAG 变成了一行 API...
你只需要上传文件
调用 generateContent
Gemini 就会自动完成索引、向量嵌入与语义检索,并基于你的文件内容生成答案, 并附带引用来源...
以前,如果你想让 Gemini(或者其他大模型)回答和你公司、项目、文档相关的问题
你得自己做一个 RAG 系统:
1️⃣ 把文件拆分成小块
2️⃣ 生成向量嵌入(embedding)
3️⃣ 存进数据库
4️⃣ 检索匹配
5️⃣ 把结果再送回模型生成答案
👉 这很麻烦,而且维护成本高
Google 现在把这些工作全都集成进了 Gemini API 这就是 File Search:
一个“开箱即用的 RAG 系统”
中文

Sora 模糊视频有救了!这工具必须先收藏,以后用的着!
Video2X-QT6是一款免费开源的AI视频处理工具,支持视频超清放大、补帧,兼容CPU和GPU,可将低画质视频提升至4K/8K分辨率,而且对电脑配置要求很低!
功能概述:
视频画质提升
将模糊视频转化为4K画质
支持将低分辨率视频提升至4K甚至8K
利用AI技术修复视频细节,提升视觉质量
视频处理能力
具备帧插值功能,使视频播放更流畅
支持CPU和GPU处理,低显存设备亦可使用
无需网络即可本地处理,保障数据安全
应用场景:
多媒体内容优化,比如模糊的Sora 视频
适用于动漫、电影、旧视频等多种视频内容的优化
可用于修复老电影和动漫,提升观看体验
图像处理扩展:
不仅支持视频,也支持图片无损放大和画质修复
解决图像失真和模糊问题,提升图片清晰度

中文



HuggingFace 发布的超长技术博客(200页,2-4天才能读完),完整记录了团队训练 SmolLM3 的全过程,对于想训练小模型的团队,必看!
从训练指南、训练核心流程、最佳实践、基础设施和资源推荐,强调「通过精心策划的数据、稳定基础设施和优化流程,实现高性能模型,而非依赖巨型计算资源」,非常值得慢慢学习。
huggingface.co/spaces/Hugging…

中文
来自六个月硬核使用 Claude Code 的实战优化指南
来自一篇 Reddit 帖子,作者是一位拥有7年软件工程经验的开发者,分享了其在过去6个月中,使用 Claude Code(CC)进行大规模软件重构的亲身经验。具体而言,作者单枪匹马地将一个超过30万行代码(LOC)的内部Web应用,从过时的技术栈(React 16 JS + Material UI v4)迁移到现代框架(React 19 TS + TanStack Query/Router + MUI v7)。作者强调,AI工具虽强大,但需通过结构化工作流、精确提示和人工监督,方能实现高质量、一致性的输出。
核心内容与关键见解
作者构建了一个完整的生态系统,包括技能(skills)、钩子(hooks)、文档管理和自动化工具,以解决Claude在长任务中常见的痛点,如上下文丢失、代码不一致和调试难题。以下是主要优化策略:
1. 技能自动激活钩子:Claude默认不会主动调用预定义技能,作者开发了钩子系统(如UserPromptSubmit Hook和Stop Event Hook),通过关键词触发(如文件路径或内容模式)强制注入技能提醒(如错误处理规范)。这确保了技能在大型代码库中的一致应用,显著降低了代码变异。
2. 开发文档系统:针对Claude“半途遗忘”问题,每项大任务前生成专用文档(如[task-name]-plan.md、-context.md和-tasks.md),并通过斜杠命令(如/create-dev-docs)实时更新。这些文件充当外部“记忆”,支持会话恢复和自动压缩,维持任务连续性。
3. 后端调试自动化:使用PM2进程管理器监控7个微服务日志。Claude可自主执行 pm2 logs 命令,快速定位并重启故障服务。这将手动日志追踪转化为AI驱动的实时诊断,提升了调试效率。
4. 错误零容忍管道:钩子追踪文件编辑、运行构建检查(如TypeScript错误),并在检测到风险模式(如异步调用)时触发自审提醒。作者曾尝试自动格式化(Prettier),但因 token 消耗过高而弃用,转而强调预防性质量控制。
5. 文档与代理演进:简化根目录CLAUDE. md,仅保留项目核心信息;仓库级文档则模块化引用技能。引入专职智能体(如strategic-plan-architect用于规划、build-error-resolver用于修复),每个智能体有明确角色和输出规范。斜杠命令进一步简化重复提示。
6. 提示最佳实践:作者建议从规划模式入手,避免模糊指令;若输出不佳,补充上下文重试。核心教训是:AI需人类直觉辅助,尤其在复杂决策中。
帖子地址:
reddit.com/r/ClaudeAI/s/a…

Peter Steinberger 🦞@steipete
Some good tips in there, also A LOT of workarounds to fight Sonnet's post-training choice for rushing instead of being diligent and careful. With codex you can drop 90% of the charade. reddit.com/r/ClaudeAI/com…
中文
在开发 Agent 应用,当想让它能通过实际运行数据不断学习优化,但是该功能实现起来颇为复杂。
微软技术团队,最近开源了一个叫 “Agent Lightning” 项目,将这个技术门槛大幅降低,轻松为 Agent 加上自我优化能力。
只需添加简单的事件追踪代码,就能应用强化学习、自动提示词优化、监督微调等多种算法来持续改进 Agent 表现。
GitHub:github.com/microsoft/agen…
除此之外,还兼容目前所有主流 Agent 框架,如 LangChain、AutoGen、CrewAI 等,甚至纯 Python 项目。
采用轻量级架构设计,对项目原代码侵入低,通过 pip 安装即可使用,官方还提供了丰富的示例和完整文档。

中文
刷到了个25K Star 的 Claude 编程指南!
内容包括使用Claude做 RAG,抽摘要,如何使用工具,做客服代理,与向量数据库集成,多模态(图像和图表解读,抽取最佳实践),以及更高级的子代理(用Opus调用Haiku)等等。
地址:github.com/anthropics/cla…

中文