Sabitlenmiş Tweet

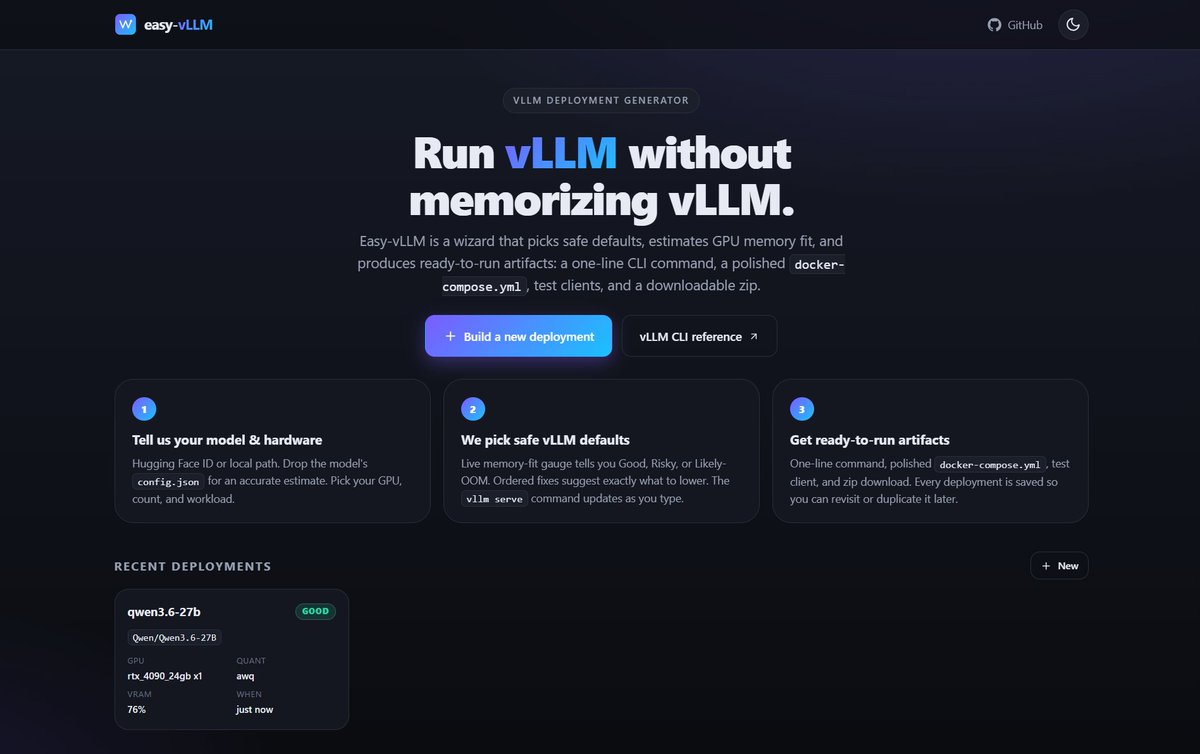
Ship LLMs without losing your mind 🤯
Easy-vLLM turns 100+ confusing flags into a simple 3-step wizard
→ Pick model + GPU
→ See if it fits (live VRAM check)
→ Get ready-to-run Docker + API
No guesswork. No broken deployments. Just copy → run 🚀
github.com/inboxpraveen/E…
English