Sabitlenmiş Tweet

‘Civilized inference’ is about respect.
Respect for compute.
Respect for shared GPUs.
Respect for developers’ time.
Respect for cost transparency.
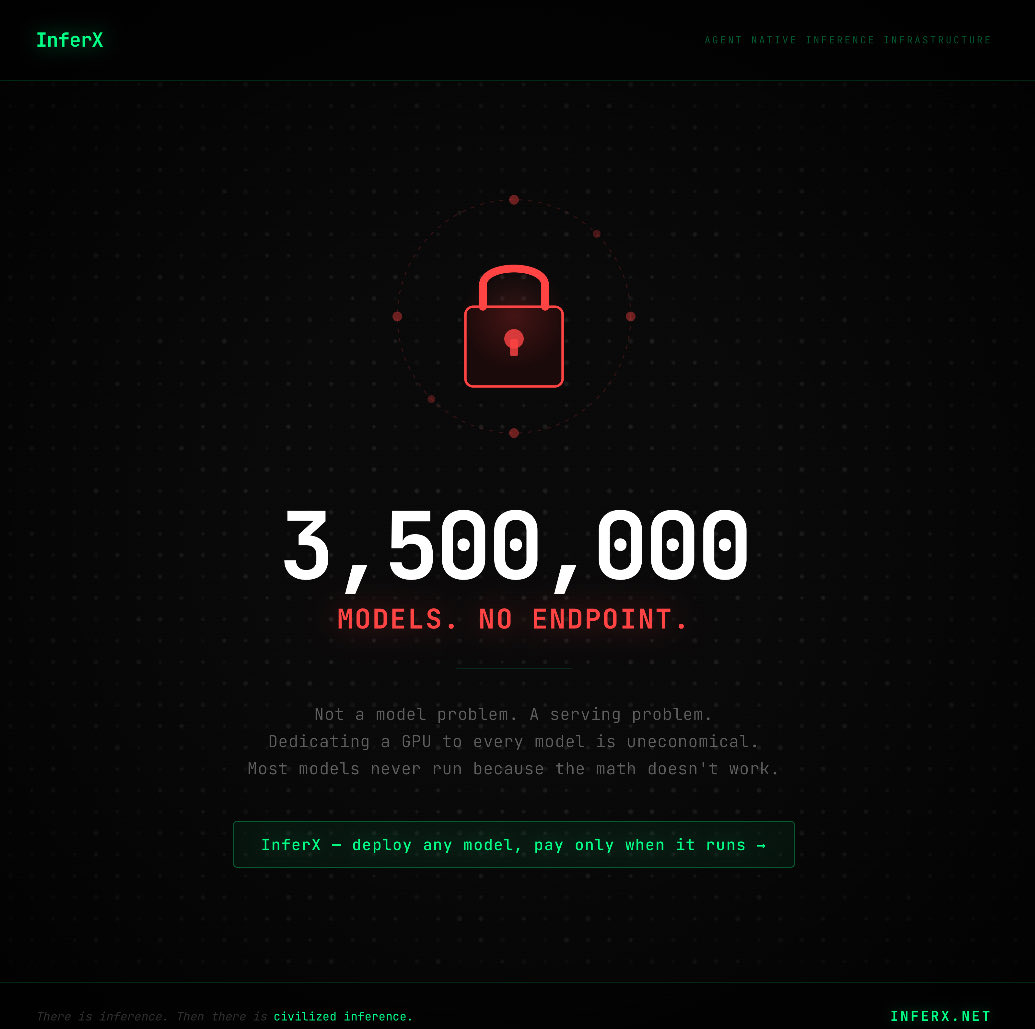
Most infrastructure normalizes waste.
Idle VRAM. Hidden billing. Manual warm pools.
‘Civilized inference’ refuses to.
@InferXai
inferx.net
English