Sabitlenmiş Tweet
IsakPar
183 posts


IsakPar
@IsakPar021
My account was suspended because I was under thirteen when I created it….. 12 years ago
Katılım Ekim 2025
108 Takip Edilen173 Takipçiler
Ozempic reducing food demand by 850,000+ truckloads a year is insane. At some point this stops being a healthcare story and starts becoming a grocery, snack, and beverage earnings story.
Polymarket@Polymarket
JUST IN: New study reveals drugs like Ozempic responsible for >850,000 fewer annual truckloads of food & beverage deliveries in the U.S.
English
I’ve used Claude Code + Opus every day for months.
Brutally honest take: GPT-5.5 finally made me switch.
Claude still feels better to talk to. It’s warmer, chattier, more natural.
But the performance gap with 5.5 is now too big to ignore. It just gets more real work done.
Still don’t like the codex app though. I am only using the CLI.
English

@IsakPar021 @theo i switched to codex fully on dec 14th. subscribed to the 200 plan on claude again for opus. regret it already. codex still is better
English

If I was a comms lead at OpenAI, I would try to get Sam drunk at least once a week. This is incredible.

English
“But traditional backend have auth bugs too”
Yes of course they do. But a traditional DB has a server between the user and the database. To leak data, the server has to actively hand over data through a route you wrote.
With RLS the route is already exposed, to leak it you just have to forget to lock it. The default state is open.
English
Here is how Supabase works under the hood;
Your anon key ships in the client bundle. Visible to everyone, the browser talks to Postgres over HTTP.
The only thing between a user and SELECT * FROM users is an RLS policy you may or may not have written.
Missing one table? That table is now public.
Missing one operation? That operation is now public.
This is not security by default. It is security by remembering.
English
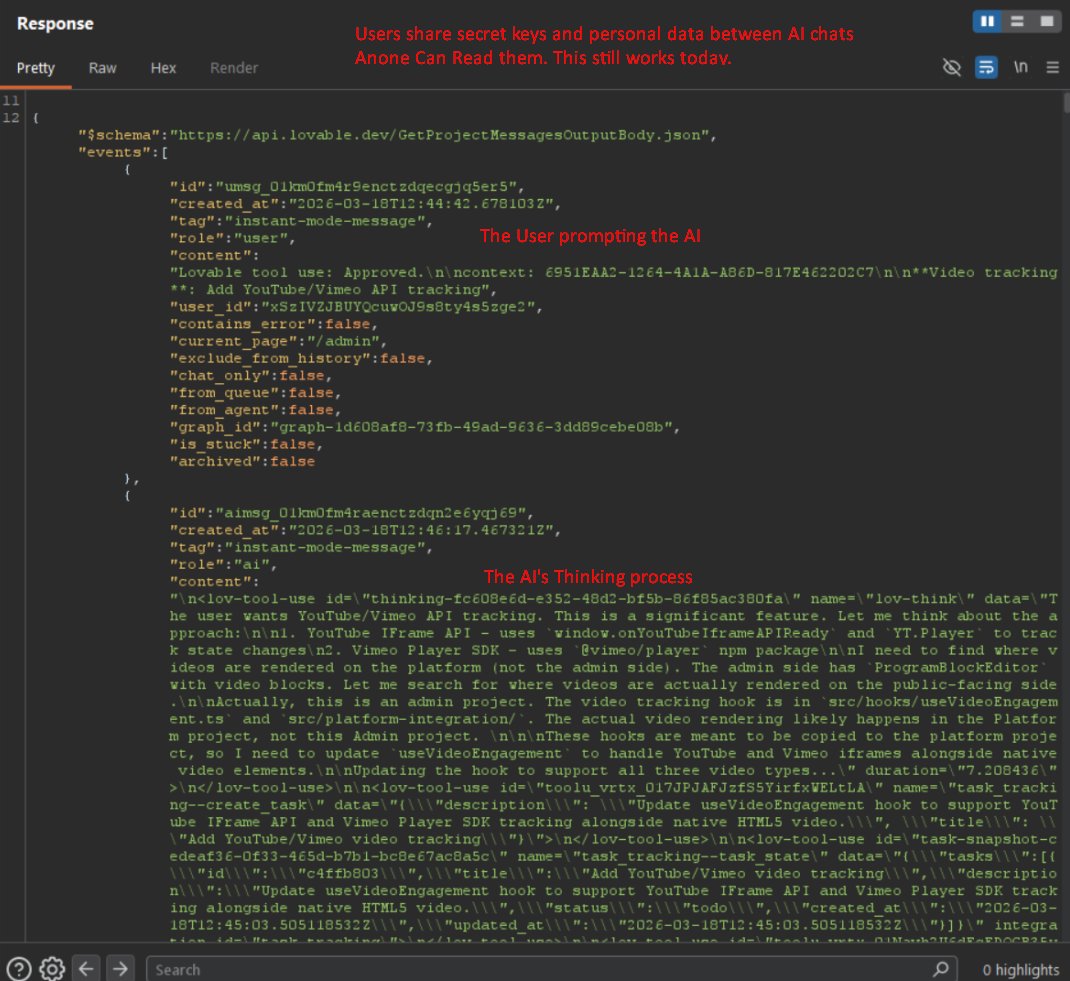
Lovable just leaked source code, DB credentials and chat histories for all projects created before November 2025.
Here is my take;
The root cause is not a Lovable problem, it is RLS.
Row Level Security; a SQL policy that you stable to table that says “ only show rows this user owns”. What happens if you forget to staple it? Full access, no error or warning.
English

@IsakPar021 @weezerOSINT I suspect all Delve customers are a crazy target right now.
English

Lovable has a mass data breach affecting every project created before november 2025.
I made a lovable account today and was able to access another users source code, database credentials, AI chat histories, and customer data are all readable by any free account.
nvidia, microsoft, uber, and spotify employees all have accounts. the bug was reported 48 days ago. its not fixed. They marked it as duplicate and left it open.


English
@Rasmic I feel there is a lot of people that agree with this. IMO it has become trendy to hate on CC and Opus. I do genuinely like them. I see my self being able to adopt and start using Codex but I’ve used CC long enough to have expectations on behaviour that would make a switch hard.
English

I guess it's just me and julius
I find the codex models unbearable...
I don't like the GUIs that exist.
I know benchmarks say otherwise but Claude Code + Opus is just enough
Slap on a code reviewer and you are big chilling
video coming soon !!
Julius@jullerino
finding much more joy using claude over codex rn...
English
If this is true it is bad. Take precautions, rotate keys, update envs
Alex@DiffeKey
Vercel has reportedly been breached by ShinyHunters. As of now, nobody else appears to be posting about this, so I’m sharing what I have. Here is the information I’ve gathered, along with screenshots provided by ShinyHunters. #cybernews #shinyhunters #breach #vercel #news
English

500 means the backend failed to handle the request - a backend bug, not client. The API has to enforce the 5MB upload limit itself and return a 413 with a clear error. UI checks should be UX, not enforcement( curl/postman bypass them). Do also add a pre upload size check on the front end for better UX. But the 500 needs fixing server side first.
English
Trick question… nothing is violated, BEGIN/COMMIT already gives you atomicity. Crash before commit gives you automatic rollback.
Wrap it in a transaction would be wrong as well - it already is.
The real risk; no balance CHECK (consistency), concurrent transfers (isolation), retry = double-spend.
English

What ACID property is being
violated here, and what's the fix?
BEGIN TRANSACTION;
UPDATE accounts
SET balance = balance - 500
WHERE id = 1;
-- app crashes right here --
UPDATE accounts
SET balance = balance + 500
WHERE id = 2;
COMMIT;
English
@javarevisited `created_at` is a TIMESTAMP, not a DATE.
`= '2026-01-01'` only matches rows at exactly 00:00:00 — you silently miss the rest of the day's orders.
Fix:
WHERE created_at >= '2026-01-01'
AND created_at < '2026-01-02'
Range scan is index-friendly.
English

Interviewer:
What’s wrong with this query?
SELECT * FROM orders
WHERE created_at = '2026-01-01';
English
Systems design question and real world example;
Build a queue that doesn’t loose messages when the server crashes.
Your code calls write(),gets back “ok” - queue confirms the message is persisted, server dies. Your message is probably gone.
Here is how to build it crash safe
English