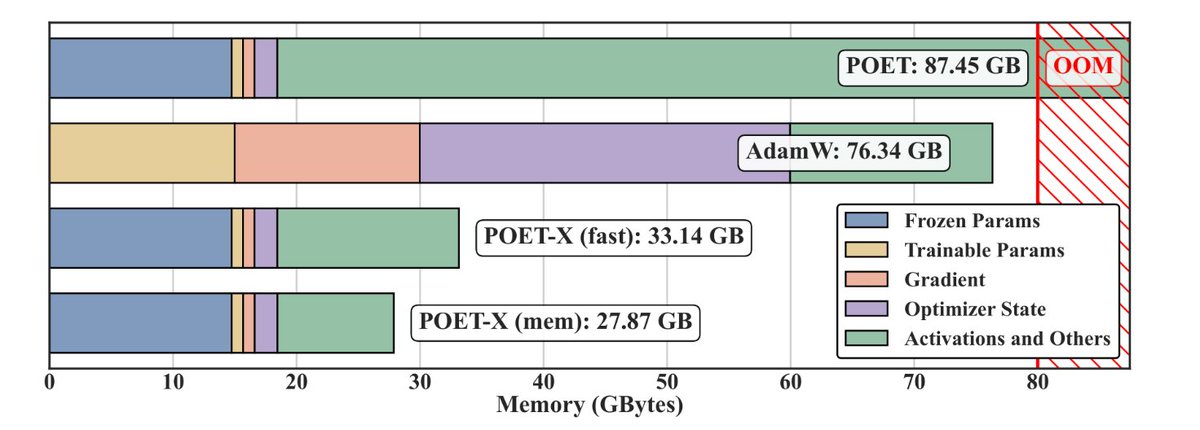
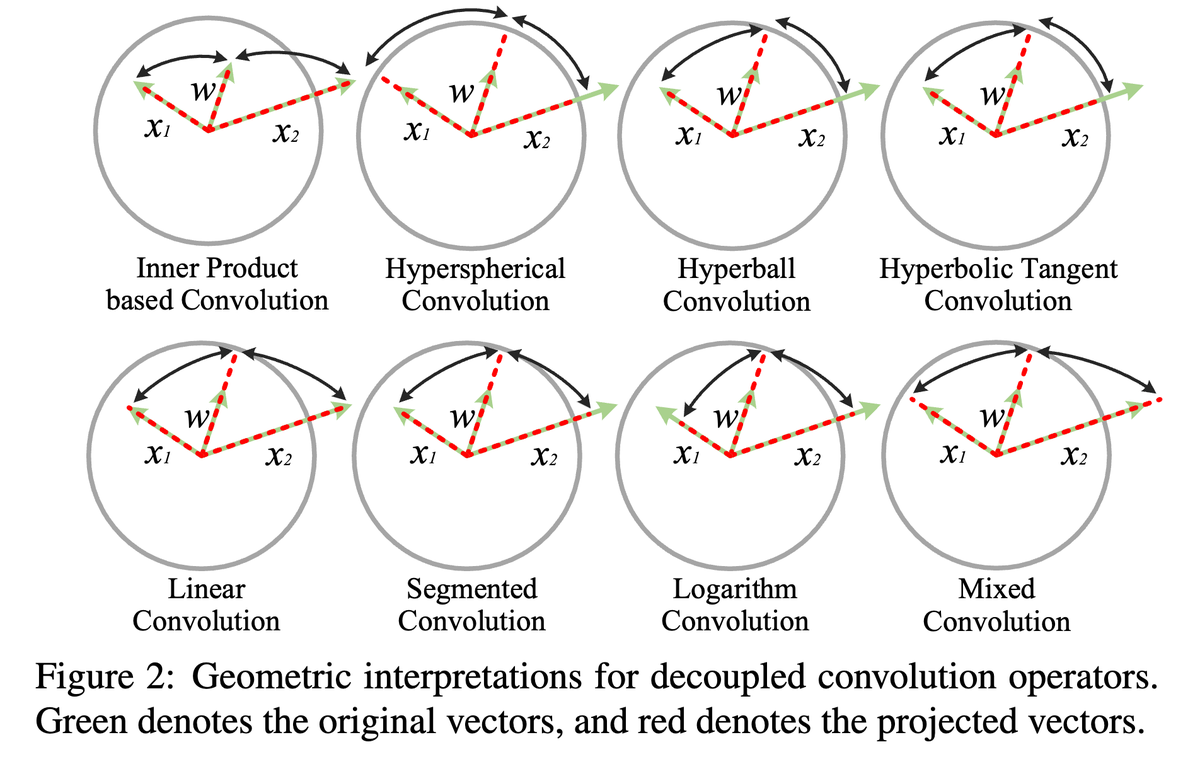
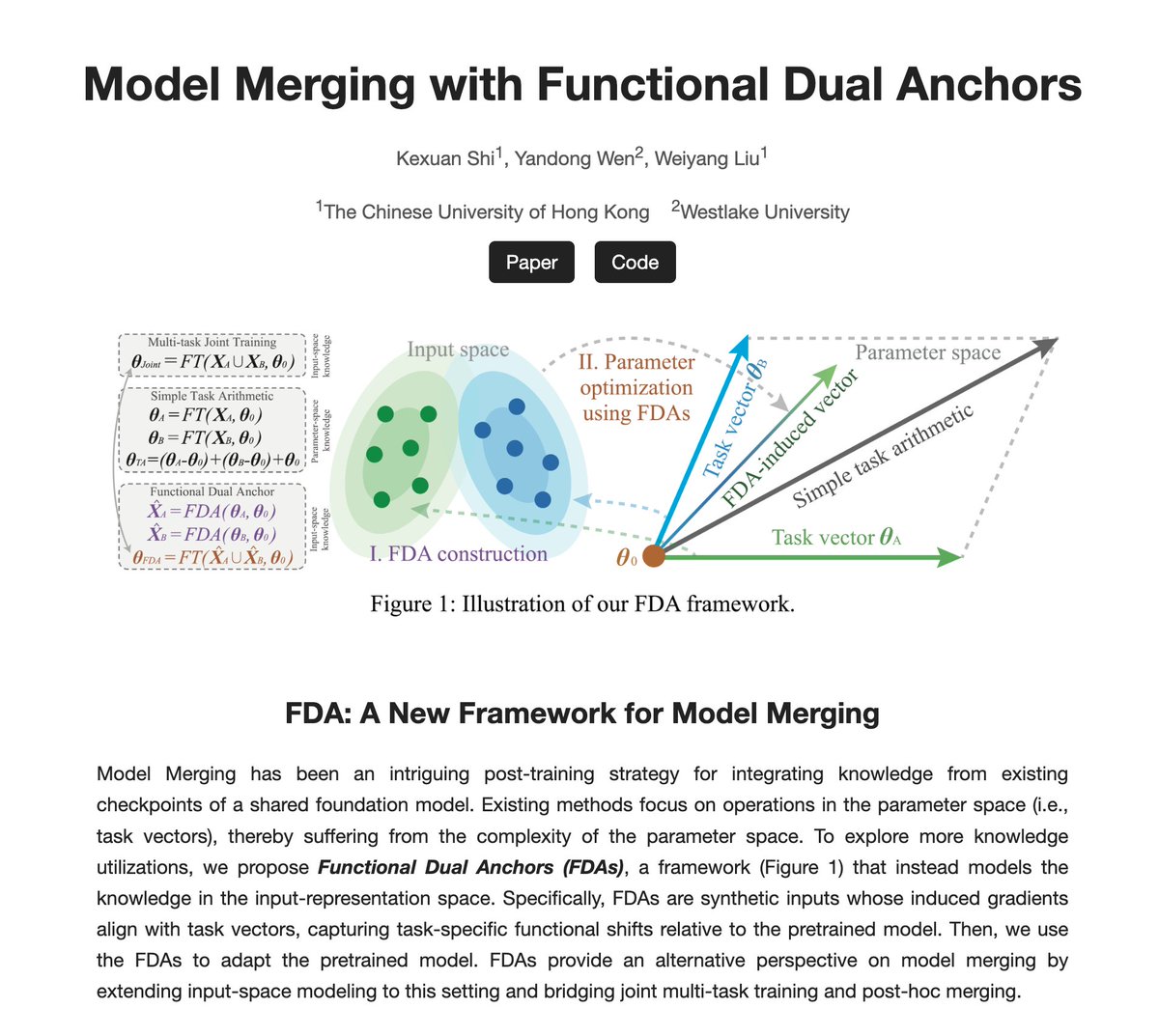
Sabitlenmiş Tweet

Can LLMs design real machines — from 🚗 cars to 🏹 catapults?
Can they engineer through both 🧠 agentic workflows and 🌀 reinforcement learning (RL) — learning from physical simulation instead of text alone?
We treat machine design as “machine code writing”, where LLMs assemble mechanisms from standard parts.
To explore this, we built 🧩 BesiegeField — a real-time, physics-based sandbox where LLMs can build, test, and evolve machines through agentic planning or RL-based self-improvement.
Our findings:
1️⃣ Even top LLMs fail to build working catapults — easy for humans but highly dynamic ⚙️ and nonlinear.
2️⃣ RL helps — working designs emerge through interaction.
3️⃣ Aligning reasoning 🧩 with construction 🔩 remains a key challenge.
This marks the first step toward LLMs that learn to design through action — bridging reasoning, physics, and embodiment. 🛠️🤖
🌐 Project Website: besiegefield.github.io
💻 GitHub (RL & Agentic Workflow): github.com/Godheritage/Be…
👥 Joint work w/ @Besteuler & Wenqian Zhang

English