Sabitlenmiş Tweet

Prompt engineering tells AI what to do.
Caging Engineering designs what AI is allowed to do.
Bounded. Testable. Auditable. Recoverable.
github.com/LibertychaserU…
English
j sokan s
461 posts





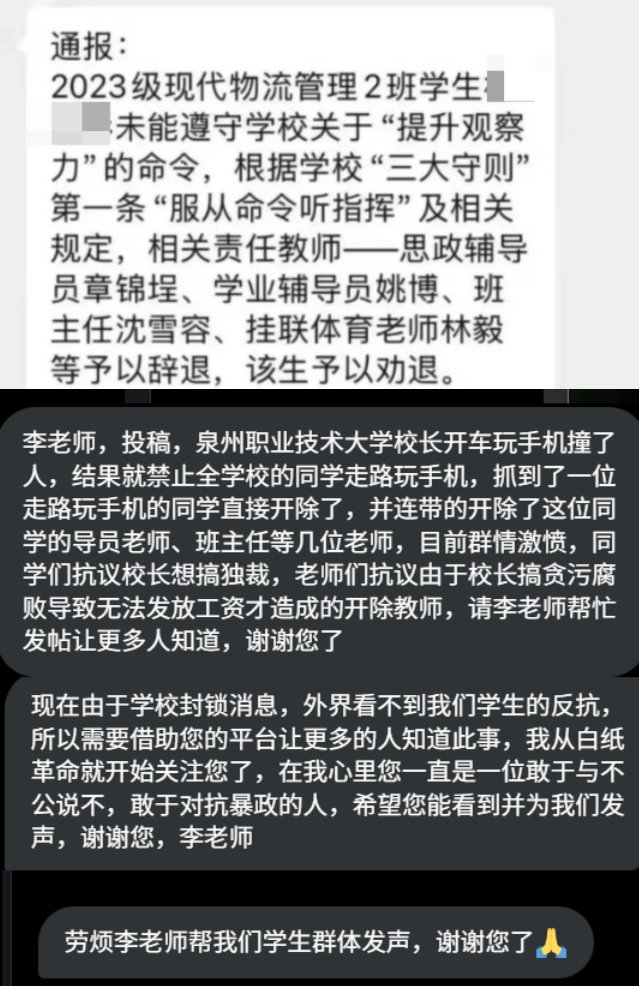
这两年 CS 天坑化的趋势,在国内可能还没有那么明显,在北美和其他发达国家基本已经是定局了。 未来大概率是 0.1% 的人薪资翻几倍,99.9% 的人注定失业。失去的岗位将会被 AI 永久性替代,不再恢复。

We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues. After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library. 🧵👇

17岁的Kai Trump(特朗普孙女),一句话戳破了整个美国教育系统最虚伪的谎言。 她在播客里说,现在高中所有人都在用ChatGPT写论文,老师都气炸了。 但她问,为什么不呢?学生就该用世界给你的资源。 学校不该禁止它,该教大家怎么把它变成自己的优势。 最讽刺的是,她自己GPA4.0,是实打实的优等生。 所以这根本不是什么作弊的问题,纯粹是代际认知的鸿沟。 老一辈把手写论文、死记硬背当成“真学习”。 但对凯这一代AI原住民来说,ChatGPT就像他们小时候的计算器、图书馆、Google一样,是默认的基础设施。 当年禁止学生用计算器学乘法的老师,现在看来可笑至极。 今天禁止学生用ChatGPT写论文的老师,十年后也会是同一个笑话。 其实真正危险的从来都不是AI, 是教育系统一边假装AI不存在, 一边逼着学生偷偷摸摸用它。 结果就是,会用的学生偷偷把效率拉满,不会用的还在熬夜抄书。 没有人教他们怎么提出高质量的问题,怎么验证AI的幻觉,怎么把AI的输出变成自己的深度洞见。 而这些,才是未来10年最值钱的能力。 我相信AI不会让学生变笨, 它只会放大差距。 会用AI的人,一个人能顶以前一个团队。 不会用AI的人,会被时代甩得连尾灯都看不见。 我们的教育还在教学生怎么在没有AI的世界里生存, 但他们未来要面对的,是一个AI无处不在的世界。 所以这种拒绝变革的教育,最终只会培养出一批“在AI时代不会用AI”的人。 这才是对下一代未来最大的作弊。