Sabitlenmiş Tweet

ARC Prize 2025 is over, an amazing contest, with amazing people competing.
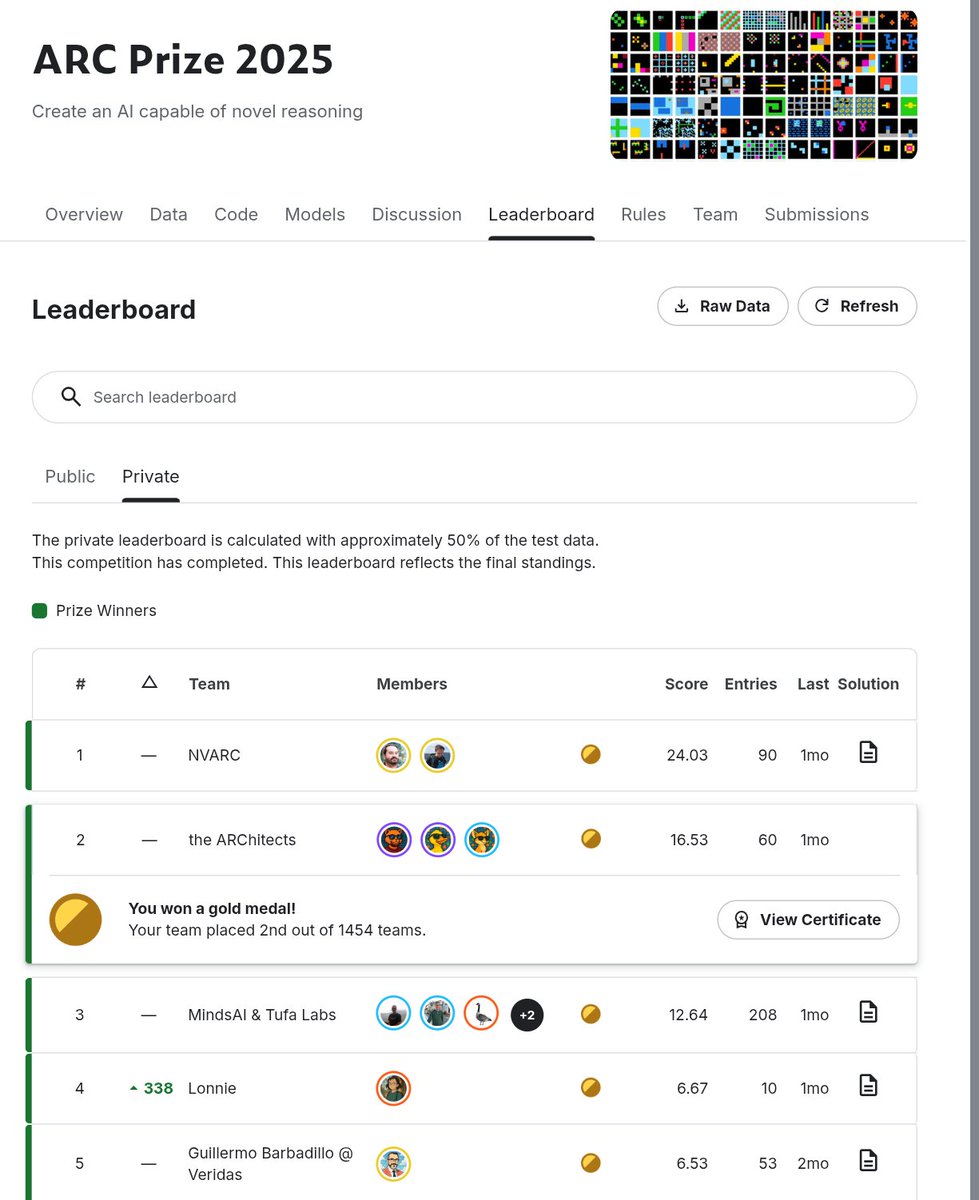
This year our team "the ARChitects" managed to reach second place. We tried a lot of things, some thoughts and explanation of our approach below!
English
Jan Disselhoff
77 posts

@JDisselh
Deep Learning Scientist | The ARChitects Kaggle Team | ARC-AGI 2024 Winner







@JPobserver Sure, but it’s really just relativity + Shannon information. I guess I should have information theory in the list but I ran out of room.

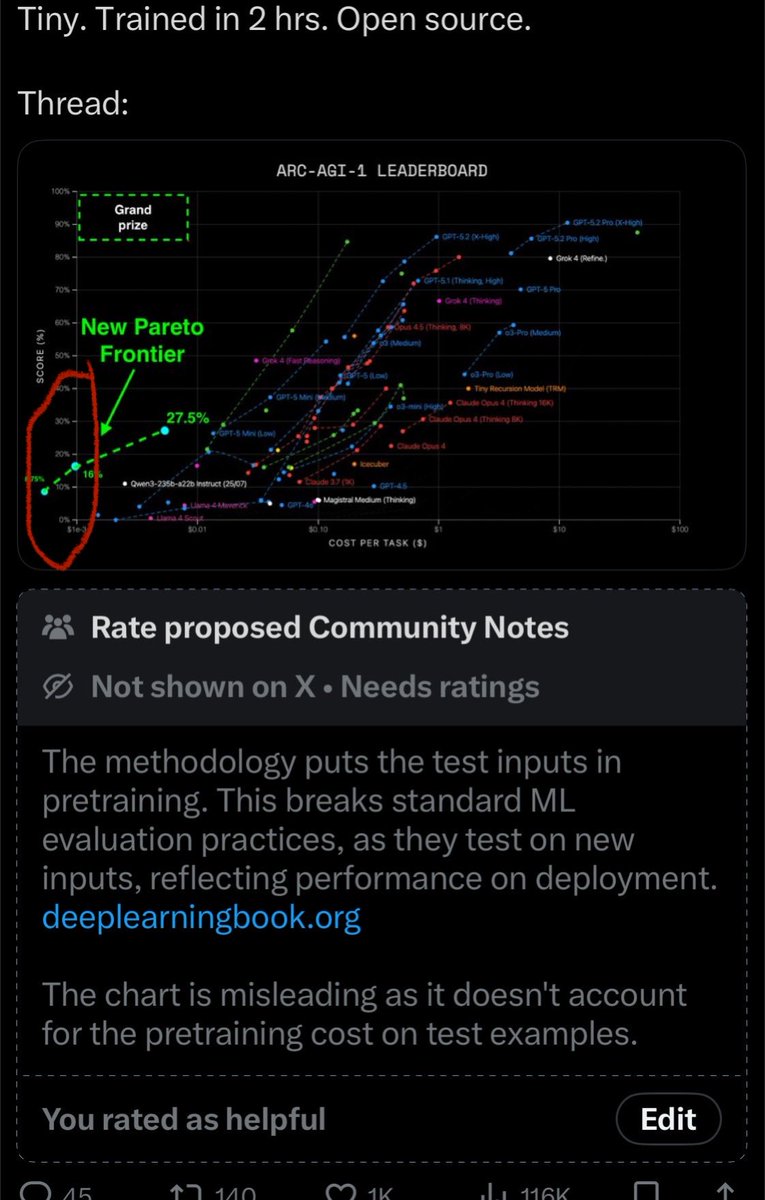
Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread:
yes, that makes sense and is much more aligned with what i understood as acceptable for TTT methods so what's happening in the OG work (aka mdlARC) is twofold: 1) design a method that intentionally trains "from scratch" each time but then amortizing that cost across all tasks (breaking from-scratch-training design) 2) proceeding to also train on _all eval set inputs_, not just a single one at test time 2) was the bigger red flag for me, since it implies a model weight update using _all test inputs together_, which seems like it would also violate the arc submission process as well
Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread:

Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread:



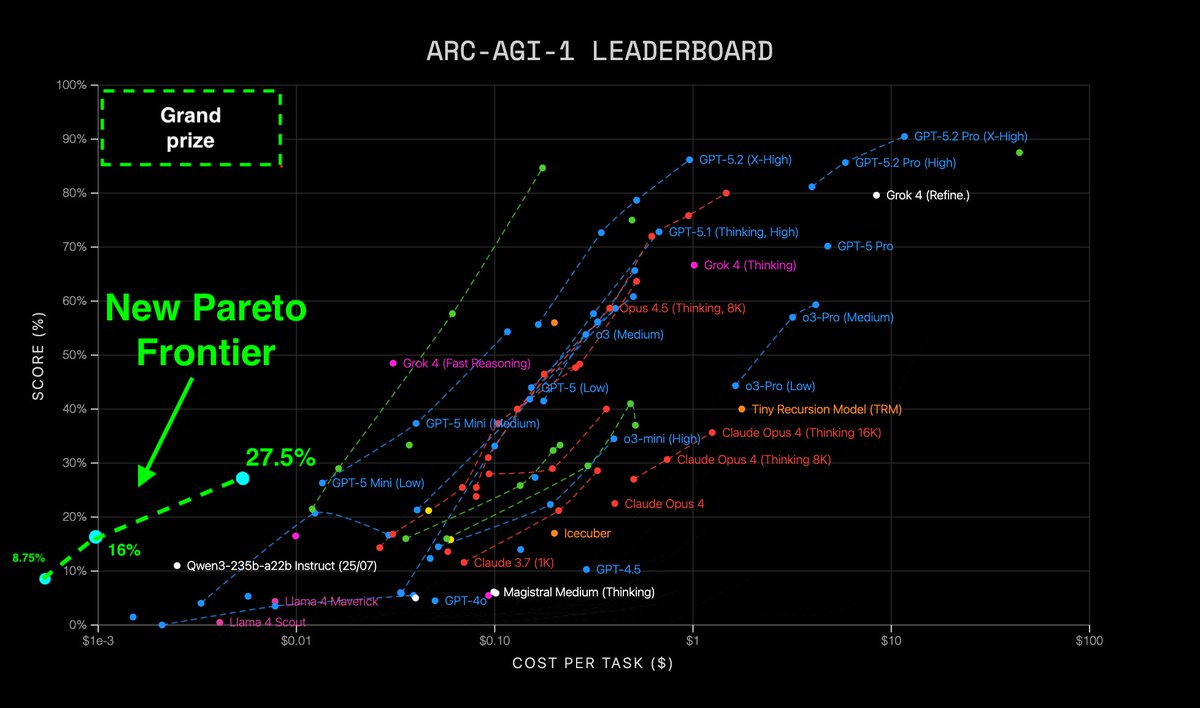

Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread: