
GlitchNarwal
941 posts
GlitchNarwal
@JamKo_Ams
Dull boy, work all day
Amsterdam Katılım Şubat 2010
292 Takip Edilen101 Takipçiler


@JeroenBreevoort @cursor_ai Need to RL composer to effectively use it I guess?
English

@cursor_ai Cursor is not doing this, It's the Figma MCP that is doing this right?
English
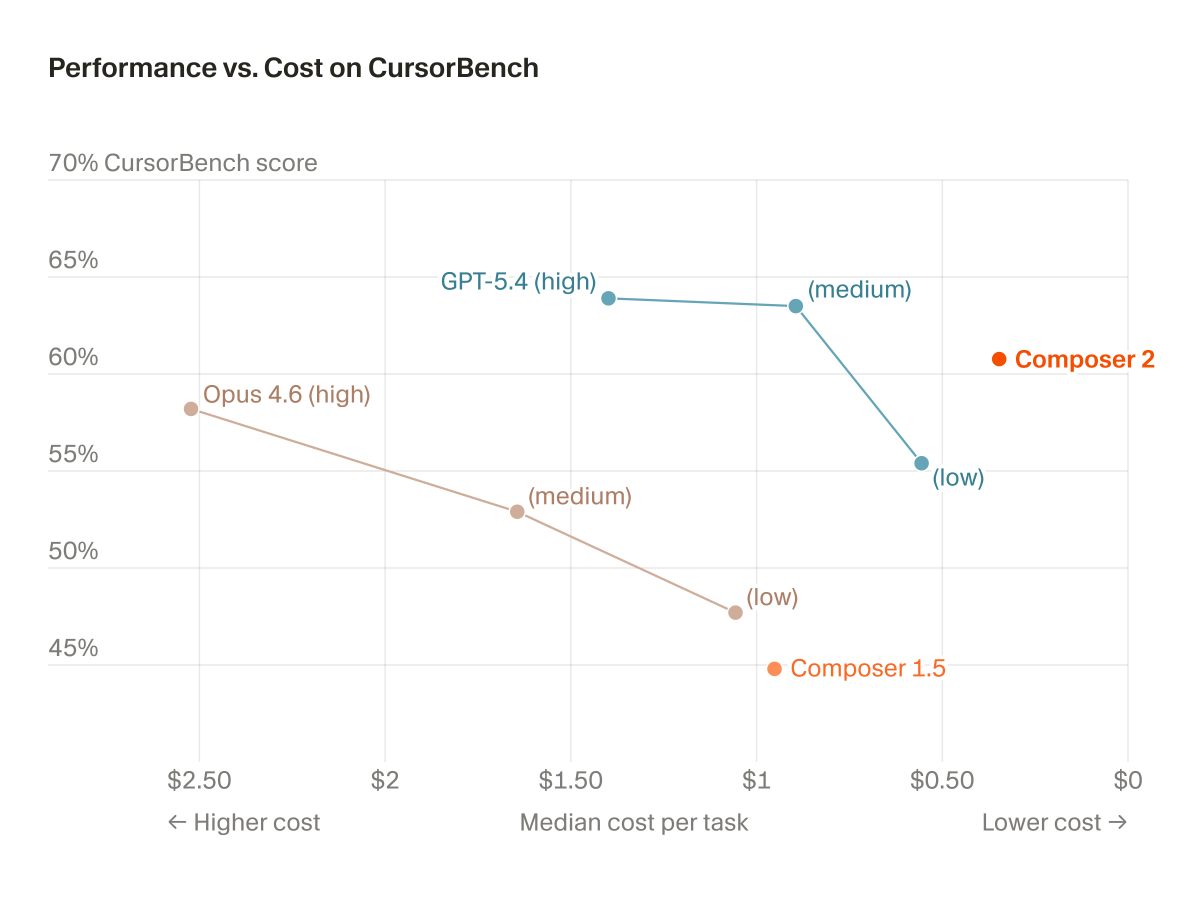
@slow_developer GPT 5.4 is behind 5.3 Codex for 99% of coding tasks
English

anthropic keeps doing this thing where its models are brilliant at launch, then much worse a month later
opus 4.6 now is far behind gpt-5.3 codex, and even more behind gpt-5.4 high when working on large codebases
not surprised though
this has been happening since sonnet 4
English
English

since no one else will say it: i'm on my way to spending $15-25k this year on my @openclaw agents
English

If you buy what Centcom is selling, this is the most accident-prone the US military has been in its entire history. The F-15 entered service 60 years ago and its never been downed during a war. Now 5 of them have been downed by "malfunction" and "friendly fire" in 2 weeks.
China Global@ChinaGlobl
🚨 Breaking | U.S. Central Command: “Iran’s claim that it shot down an F-15 aircraft is a ‘rumor.’ It was a technical malfunction.”
English
@TheDefiantGhost How am I seeing Tucker Carlson doing good shit everywhere while in my mind he was a right wing extremist?
English

Remember when Tucker Carlson straight-up silenced Mark Cuban?
Mark: "Half my family is Ukrainian. I think we should help."
Tucker: "How much money have you sent to Ukraine?"
Mark: "None."
Tucker: "So what do you mean by we? If you think we need to help, why don't you start? How about you first?"
This never gets old.
English
@archiexzzz @karpathy This kind of thing + automated scripted voice models + scammers are going to be a pain in the but in the comming years
English

Introducing AutoVoiceEvals
I've applied the @karpathy autoresearch loop to voice AI agents. It's open source.
Your voice agent has a system prompt. That prompt determines how it handles every call - bookings, complaints, edge cases, background noises, long pauses, people trying to trick it. Most teams write it once, test manually, and hope for the best.
autovoiceevals makes it a loop. One artifact (system prompt), one metric (adversarial eval score), keep what improves it, revert what doesn't. Run it overnight. Wake up to a better agent.
> How it works:
You describe your agent in a config file - what it does, its services, policies, and what it should never do. You don't write test cases. You don't define attack vectors.
provider: vapi / smallest ai
assistant:
id: "your-agent-id"
description: |
Voice receptionist for a hair salon.
Maria does coloring only. Jessica does cuts only.
$25 cancellation fee under 24 hours notice.
Cannot advise on skin conditions. Closed Sundays.
From that description alone, Claude generates adversarial caller personas - each with an attack strategy, a voice profile (accents, background noise, mumblers, interrupters), a multi-turn caller script, and pass/fail evaluation criteria. The eval suite is generated once and held fixed for the entire run, like a validation set.
> The loop:
1. Read the agent's current prompt from the platform
2. Generate adversarial eval suite from your description
3. Run baseline
4. Claude proposes ONE surgical change to the prompt
5. Push the modified prompt to the agent via API
6. Run all scenarios against the updated agent
7. Score improved? Keep. Same score but shorter prompt? Keep. Otherwise revert.
8. Go to 4. Run until Ctrl+C.
The system sees its own experiment history. When a change fails, the next proposal knows what was tried and why it didn't work.
We ran 20 experiments on a live Vapi dental scheduling agent. 0 human intervention.
> Score: 0.728 → 0.969 (+33%)
> CSAT: 45 → 84
> Pass rate: 25% → 100%
> 9 kept, 10 discarded
> Prompt: 1191 → 1139 chars (better AND shorter)
You describe your agent. It figures out how to break it.

English
@VantagePoi64328 @tim_cook lol. Everybody in here got rage baited hardcore
English

@tim_cook Can you make a Mac that doesn’t become a potato after 4 years?
English

@cursor_ai @GeoffreyHuntley Everybody who criticises Cursor: “don’t get met wrong, I use Cursor and Love it, but:”
English


@GeospyAI crazy. How are you trying to make cash out of this slop app when literally every button on your site is broken.
English
@protosphinx They made us promise to undersell it so Nvidia can have 70% margins
English

ASML is alien tech. The aliens bequeathed it to the Dutch. Ain’t no way anyone else is getting that tech.
The AI Investor@The_AI_Investor
Rumor: Tesla is going to build its own EUV lithography machines because ASML is “too slow.” to supply to the new chip plant. ASML currently produces <100 EUV machines per year. Apparently that’s not fast enough for Elon Musk. The new plan: • 1,000 EUV machines per week starting 2027 • 10,000 per week by 2028 And since HBM memory is also a bottleneck, Tesla will casually build 10 new memory fabs in the next two years producing 5× the rest of the industry combined. Meanwhile, Micron Technology, SK Hynix, and Samsung Electronics are panicking.
English
@business Funny how there hasn’t been a fire on a carrier for almost 20 years but Iran doesn’t has anything to do with this one. Also what’s up with this new trend where everybody in Israel/UAE that shares rocket impacts is getting indicted?

English

The USS Gerald R. Ford aircraft carrier is leaving the fight with Iran and heading back to port, a source said, after a fire broke out in its laundry area and left at least two sailors with non-life-threatening injuries. bloomberg.com/news/articles/…
English
@MarioNawfal Funny how there hasn’t been a fire on a carrier for almost 20 years but Iran doesn’t has anything to do with this one. Also what’s up with this new trend where everybody in Israel/UAE that shares rocket impacts is getting indicted?

English

🚨 BREAKING: The USS Ford is now leaving combat after a a major fire broke out last week injuring ~200 sailors and knocking out about out ~100 bunsleeping quarters.
It took 30 hours to fully control the blaze
Iran claim they struck the aircraft carrier. The U.S. states damage is non-combat related
Not sure what to believe anymore
English
@ericzakariasson @branmcconnell @cursor_ai Correction… codex 5.3 is a better model, And cheaper 💸. 5.4 supposedly incorporated codex coding skills is bs.
English

@branmcconnell @cursor_ai tbh gpt 5.4 is a better model (except for ui)
English

@trq212 I do keep wondering how long these kinds of things will be necessary. They feel overly manual and prime targets to bake into models capabilities, and a lot of it will be obsolete once memory is - finally - evolving into a more robust system
English

@sarahwooders Same. Blew away tons of tokens on mid gpt performance. Why did they even claim to have integrated Codex performance into the model 🤷🏻♂️
English

To the people who had early access to GPT-5.4 and told us all it was amazing for coding - did you even use it??
I'm fully back to Codex 5.3
English

@maddenifico You guys got played so hard. It’s been crazy to see al this shit go down from outside the US
English


@leerob Couple more years and we don’t even have to let ‘em play, we’ll just have ASI simulate based on probabilities and do NIL payouts accordingly
English

I built an app to simulate the 2026 NCAA tournament!
It uses historical data, KenPom rankings, game locations, and more to determine the win probability.
...but then has an AI model review the results and prompt for the reality of March Madness, unpredictable!
English