Jamie Milne retweetledi

wow google might've popped the ai bubble, memory stocks down massively today:
their new algorithm shrinks an AI model's memory by 6X WITHOUT reducing it's intelligence making it 8x faster with the SAME # of GPUs:
if this works - we don't need as many GPUs to train AI
- kv-cache is basically a model's short term memory. it gets massive pretty quickly = larger, slower, expensive ai
- google's algo compresses it to just 3-bits with ZERO loss in accuracy (usually models are like 32-bit)
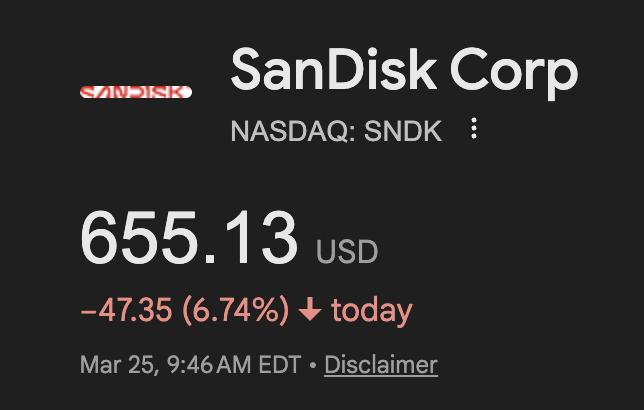
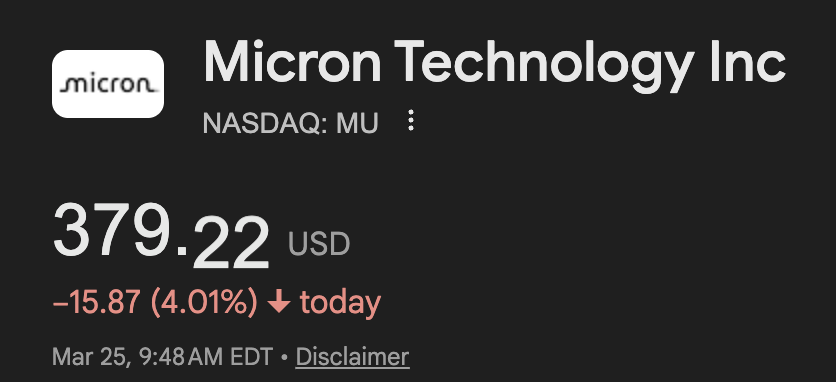
the combined market cap of micron and sandisk is $527 billion and im not even factoring in SK hynix and samsung
ai has driven up memory prices by 500%+ over the last few months - if google's algo scales then this might crash.
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English