J Feldman retweetledi

Today we're thrilled to announce the first end-to-end platform for Reinforcement Fine-Tuning.
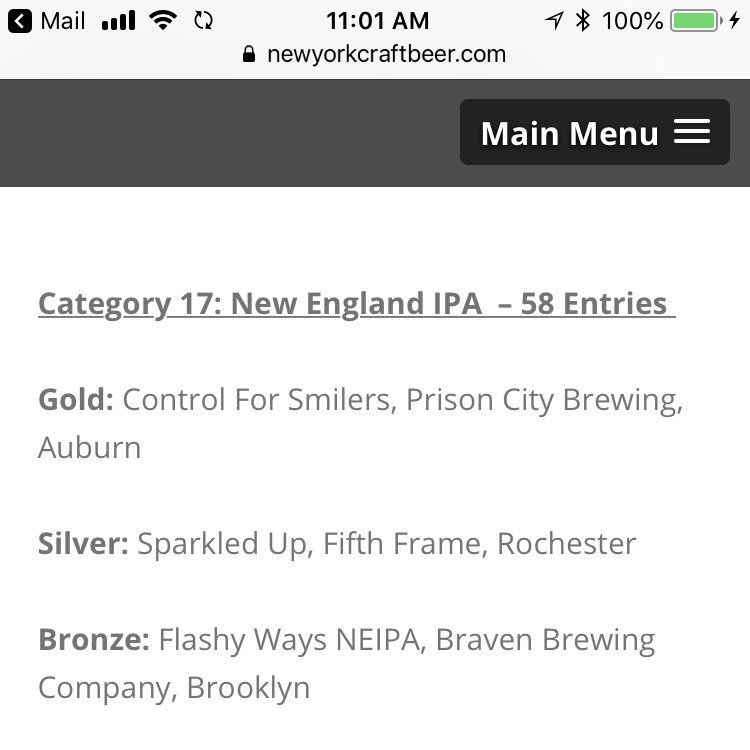
With just a dozen labeled data points, you can outperform #OpenAI o1 and #DeepSeekR1 on complex tasks. Built on the #GRPO methodology that DeepSeek-R1 popularized, our platform delivers exceptional results.
In our real-world PyTorch to Triton transpilation case study, we achieved 3x higher accuracy than OpenAI o1 and DeepSeek-R1 when writing GPU code.
Check out the thread below to learn how you can adapt an #opensource #LLM to your use cases with unmatched efficiency. #rft
English