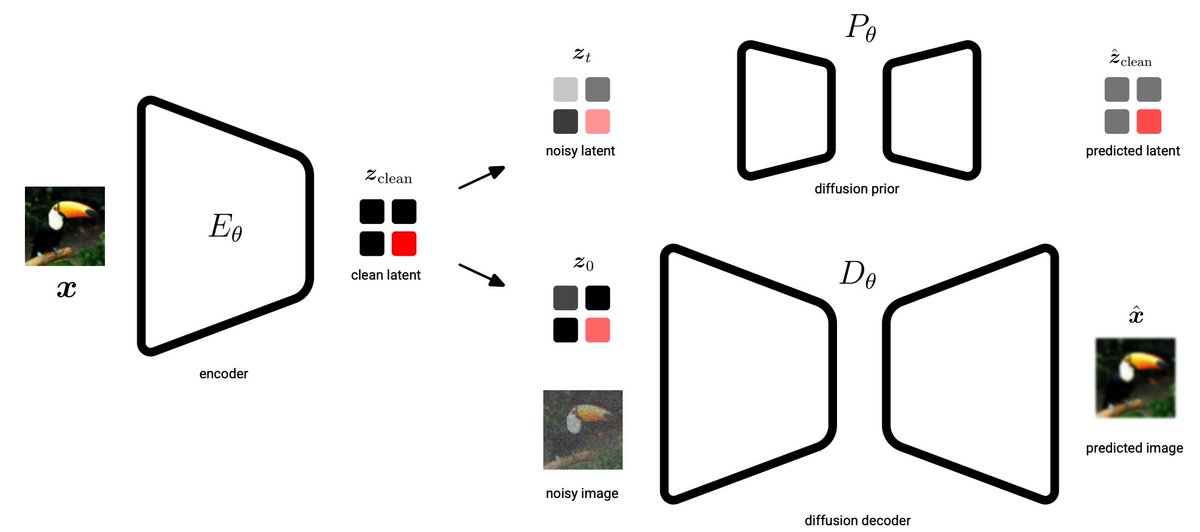
5/5 Results on ImageNet-512: competitive FID of 1.4 with high reconstruction quality (PSNR: 25.7). On Kinetics-600 video generation: we set a new state-of-the-art FVD of 1.3. Even our small model hits 1.7 FVD. Finally, we scale to text-to-image with strong perceptual quality.
English