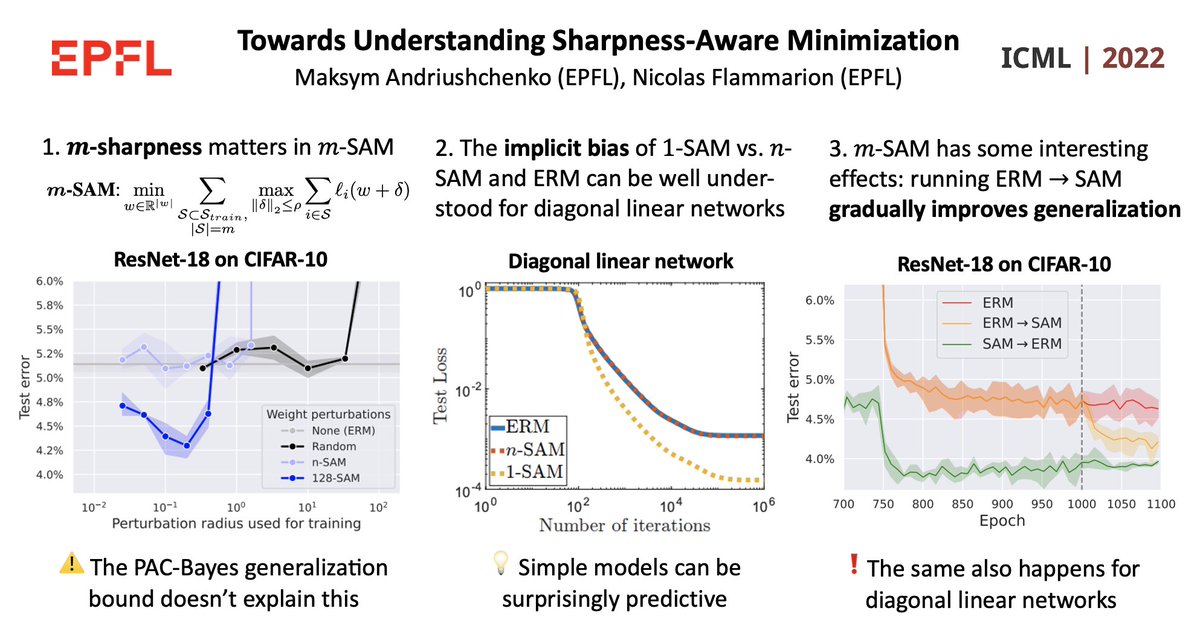
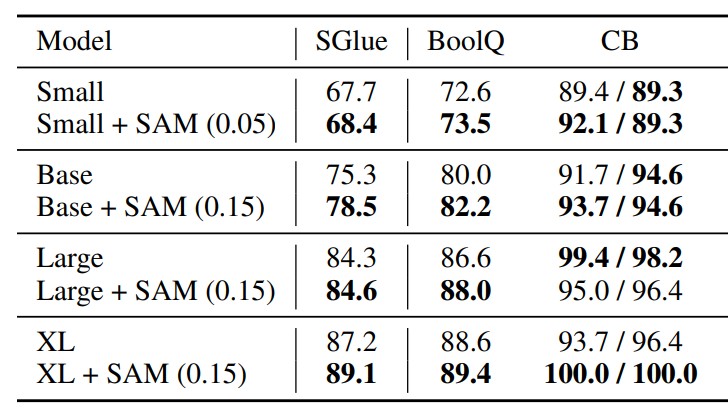
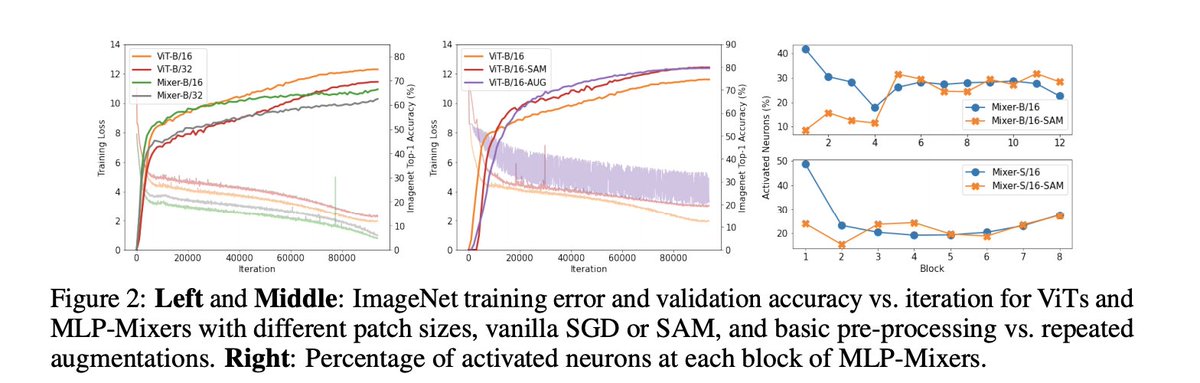
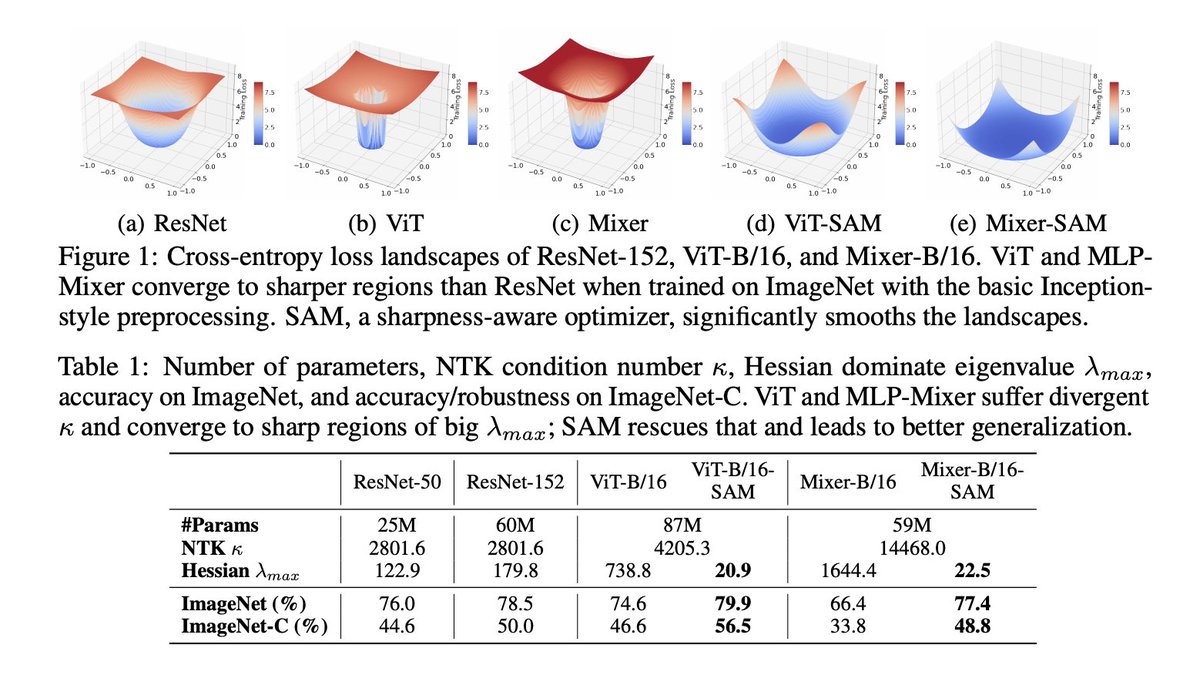
Sabitlenmiş Tweet

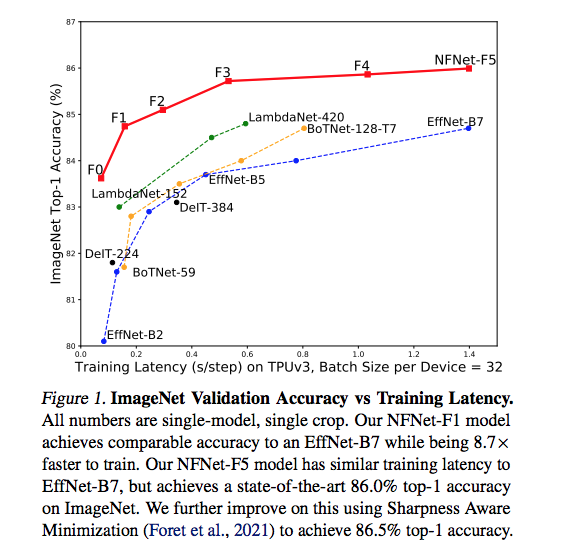
Introducing SAM: An easy-to-use algorithm derived by connecting PAC Bayesian bounds and geometry of the loss landscape. Achieves SOTA on benchmark image tasks (0.3% error on CIFAR10, 3.9% on CIFAR100) and drastically improves label noise robustness.
arxiv.org/abs/2010.01412
English