
Jordache
2.1K posts

Jordache
@JordacheDotAI
AI Adoption Strategist & International Keynote Speaker. Founder: Never Tech Behind & The Human Variable. Solving the 70% of AI barriers that are people problems
Texas Katılım Mart 2009
2.3K Takip Edilen2.6K Takipçiler

Hermes HUD just went web.
Same soul. Same dashboard that made the TUI version popular, now on the web.
**New feature the TUI doesn't have: per model token cost tracking.
Works on macOS, Linux, Windows (WSL).
@NousResearch @teknium
github.com/joeynyc/hermes…


English

Hermes will soon be a serious creative tool. More on this soon!
MACBETH@macbethAI
Glitch_lissajous -Made with Hermes Now to figure out coded sound and make this audio reactive. Stay tuned.
English
Jordache retweetledi
Hermes Agent v0.8.0 is here.
Full changelog below ↓
English
@outsource_ @NousResearch Will give kudos where kudos are deserved then...
English

HERMES-AGENT WORKS WITH CLAUDE OAUTH 🔥
While everyone else is hacking together proxies and workarounds to get Claude working locally...
@NousResearch quietly built it right into Hermes.
No proxy needed. No patches. No hacks.
You just:
→ Run claude auth login
→ Point Hermes at your Claude subscription
→ Done. It just works.
Their adapter handles everything behind the scenes auth, token refresh, model routing. All seamless.
Setup HermesAgent NOW 👇🏻
github.com/NousResearch/h…

English
@outsource_ @NousResearch LOL, yes it's OAuth but it's using Extra Usage which is basically discounted API usage (if you buy the bundle)...
English
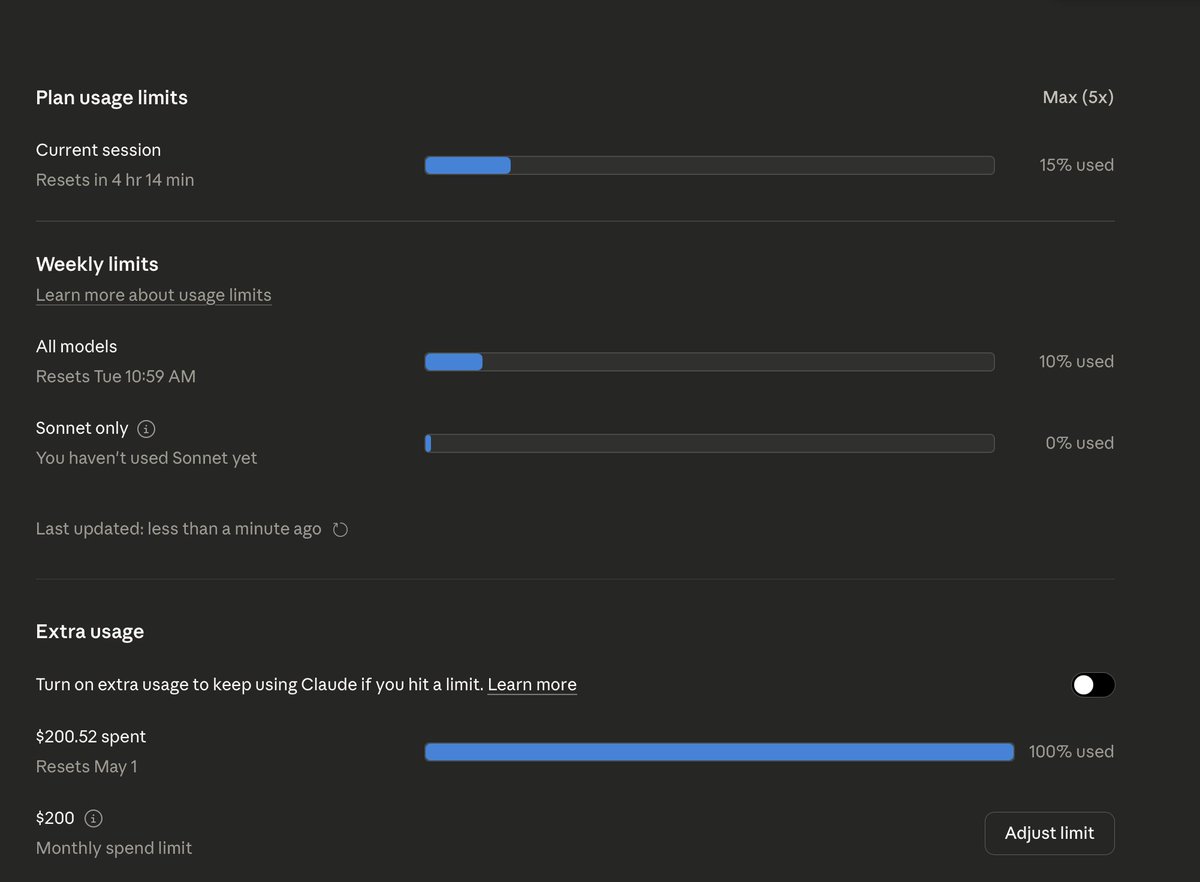
@outsource_ @NousResearch Never said you can't use Claude Opus...but nothing here shows it using OAuth vs using the API or Extra Usage
ggs
English


English


Jordache retweetledi
Introducing ⭐Carnice-27b!⭐ an open-source model designed for Hermes-Agent that can run on a single 3090.
Carnic-27b is a fine-tuned model of Qwen3.5-27b to perform well in the hermes-agent harness
Download it here! huggingface.co/kai-os/Carnice…
Huge thanks to @Teknium, @NousResearch, @TheZachMueller, @LambdaAPI

kaios@kaiostephens
Welcome ⭐Carnice-9b!⭐ - a model for Hermes-Agent Carnice-9b is a fine-tuned version of Qwen3.5-9b to preform exceptionally well in the hermes-agent harness. This model is meant to fit onto consumer GPU's all the way down to 6gb (Q4_K_M), but recommended to run in ~12-16gb cards. Try it out. Any feedback is appreciated, feel free to DM me! huggingface.co/kai-os/Carnice… This would not have been possible without the help from @LambdaAPI, @NousResearch ,@TheZachMueller, @Teknium Look out for Carnice-27b soon! 👀
English
Team Hermes isn't messing around...
Teknium 🪽@Teknium
Hermes Agent now comes packaged with Karpathy's LLM-Wiki for creating knowledgebases and research vaults with Obsidian!
In just a short bit of time Hermes created a large body of research work from studying the web, code, and our papers to create this knowledge base around all of Nous' projects.
Just `hermes update` and type
/llm-wiki
English
The LLM Wiki by @karpathy is now a built-in skill in Hermes-Agent, give it a try
Teknium 🪽@Teknium
Hermes Agent now comes packaged with Karpathy's LLM-Wiki for creating knowledgebases and research vaults with Obsidian!
In just a short bit of time Hermes created a large body of research work from studying the web, code, and our papers to create this knowledge base around all of Nous' projects.
Just `hermes update` and type
/llm-wiki
English
@dillonrolnick Well ain't that some ish...
...you sure you didn't miss a call from @sama, maybe your phone was in Do Not Disturb mode?
English


@karpathy My hobby: scraping entire podcasts into open source wikis.
Then decomposing them into skill.md files, articles, and short books for my personal consumption only.
github.com/cdeistopened/c…
Then rebundling the skills into topic-specific plugins
So much gold to mine.


English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Some may see this as "worthless, junk that no one asked for" per the comments...
...I encourage those folks to "ZOOM OUT" and see the trajectory AI Video models have been on the last 12 months.
Kudos to the team @OpenAI and @sama for continuing to push the boundaries.
OpenAI@OpenAI
Sora 2 is here.
English

We just dropped V1 of our AI Crypto Analyst Agent built with @n8n_io
@kirha_crypto is a copilot that saves you hours of research and manual analysis. It's designed as a demonstrator of @kirha_ai capabilities for investors and traders who need to cross-check live data from 10+ gated sources every day.
If you’re building AI crypto agents, you’ve seen it break for two reasons:
- No access to real live data points because the best insights are provided by private providers and gated so ChatGPT can’t reach them
- No data means hallucinations. Garbage in = garbage out
We fixed both.
By connecting to Kirha endpoint, your agent instantly taps multiple trusted data providers like @zerion, @coingecko, @Dune, @xverse and more.
No more stitching them one by one or paying separate subscriptions for each.
When your agent runs, it queries multiple sources at once, merges the results and returns a unique augmented answer in real time.
It saves you hours of work because you skip:
1/ Building and maintaining your own MCP server
2/ Creating accounts and managing API keys for each source
3/ Manually routing every query to the right provider
4/ Cross-checking answers by hand to build your final insight
And here’s what you get from Kirha node:
1/ Pull wallet balances, DEX activity and on-chain metrics in real time
2/ One auth to rule them all: connect to Kirha to be connected to all it's providers
3/ Fully automated, no stale plugins, no code needed
4/ Always up to date, you benefit from all new data providers we integrate
The best part? It’s FREE for now and takes just minutes to deploy.
See our Crypto Copilot in action → @kirha_crypto
Want access to Kirha endpoint for your project ?
💬 Comment “INVITE CODE”
❤️ Like & RT so others can clone too
📩 Follow us & DM if you want help building your custom crypto bot
English

There's months of content that has proven to go viral sitting in your X timeline...
Why start from scratch on Instagram when you can just repurpose what already worked?
This app turns your top tweets into scroll-stopping IG slides automatically:
- Drop in your X post
- Get Instagram-ready slides in seconds
- No design skills required
Follow and comment "IG" and I'll DM you the early access list.
English
English

Transparency is never a bad thing.
In fact, we need more - glad to see @sama and @OpenAI starting to swing the pendulum back in that direction.
Seems like we're getting closer to having some OA open source models...
OpenAI@OpenAI
Today we're sharing a major update to the Model Spec—a document which defines how we want our models to behave. The update reinforces our commitments to customizability, transparency, and intellectual freedom to explore, debate, and create with AI. openai.com/index/sharing-…
English