Sabitlenmiş Tweet
Joseph
3.2K posts


Joseph
@JosephD
ADHD Software Architect. Built the Evōk Engine. Perpetual digital twins for codebases. Provably safe AI coding that ends tech debt forever. Seeking its home ↘
Palm Springs ♻ Miami Katılım Temmuz 2009
2.9K Takip Edilen1.1K Takipçiler

@jparkjmc @hillclimbai This company seems fun. The right kind of brain tickle.
English

we're hiring a distributed systems / ml engineer, starting @ $250k + 2% equity
hillclimb's mission is to train AI to self-improve (see more below)
if you're interested and think you're a fit
send something about yourself + resume to talent@hillclimb[dot]com

jpark@jparkjmc
we're hiring a founding engineer @hillclimbai our goal is to teach models research taste (see more below) if you're good at - RL - training infra - data engineering you'll be employee #5 @ 200k + 1% equity send something about yourself + resume to talent@hillclimb[dot]com
English

I believe Anthropic will beat OpenAI in the long run.
Infrastructure battles are the bigger battles.
OpenAI is betting on Python and Anthropic on Typescript.
Maybe OpenAI chose Python because they believe the web will go away.
Either way, both of them are purchasing companies in these ecosystems completely unrelated to AI.
English

Now give it a scene.
"I tried so hard..." turns soft, sad, breaking.
"Hurry, hurry!" comes out faster, more urgent.
One voice, reading a story, becoming every character. 🎧
4/n
Xiaomi MiMo@XiaomiMiMo
MiMo TTS actually reads the text — not just the words. CAPITALIZED? It shouts. A dash — natural pause. Ellipsis... it lingers. No special tags. The model reads formatting the way you do. 🎧 3/n
English
The people talking about "Mixture of Agents" as some genius thing, I don't get it. I was genuinely hoping this was some change to underlying architecture, but nope...
So far everyone explains it more or less the same:
"Your query goes to 3+ agents at once. They all reply. Then a synthesizer agent decides the best answer."
This is GPT 3 level stuff. How on earth has this been branded into some 'next gen models' marketing.
This is fundamentally what any good system has been doing to leverage less expensive models for premium output.
They all run left to right, the same model can't review its work objectively in any sense. Everyone knows that, right?
You must put the least amount of singular cognitive load on any given agent to get the best response, and STILL expect any single response is going to be thin trash.
The fact that "Mixture of Agents" has turned into some breakthrough understanding of models seems absurd. It's just doin what it SHOULD do to maximize capability, leveraging existing knowns we've already established.
Nothing new here at all, or am I missing something deeper?
English
How is the person at evals not deeply aware of this already? I mean it must be twitter bait right, like nobody really is shocked by this stuff right?
Regression to the mean, the need to find 'something', patching symptoms not causes. These are like the fundamental building blocks since GPT 3.
If you want AI to tell you your codebase is perfect, it will. If you want AI to tell you you are a genius, it will.
The expectation that this can "review" in an absolute way despite being a left-to-right running machine is peak hysteria. Everyone trying to solve it with the same after-the-fact "evals" as a replacement for these gaps.
Make the scenarios impossible for evals to be needed, instead. That immediately eliminates even the option of using a probabilistic brain as the final source of truth in software dev.
Math is the only truth. Use math. That eliminates every possible error outside of 'business outcomes' which are orthogonal concerns to begin with.
English

One thing that makes me feel that code factory has not arrived yet is the following experiment:
1.Ask a LLM to do an in-depth rigorous review of your code
2. In a new thread, as same/different LLM to consider those review comments independently and address issues it agrees with
3. Keep repeating until no new concerns
I find that this loop always goes on for a ridiculously long time, which means that there is a problem with the notion of claude-take-the-wheel. This seems to happen no matter the harness or the specificity of the specs.
It works fine for simple applications, but in the limit if the LLMs have this much cognitive dissonance you cannot trust it.
Either this, or LLM are RLHFd to always find some kind of issue.
English

If you could only raise one round of funding, then could never raise again, what is the minimum you would raise?
English

I don't know. Hard for me to agree with the spec-is-code argument.
Specs are low fidelity. They aren't a common shared DSL. Have very low signal to noise. Not verifiable or deterministic. They don't encourage iterative work. Almost always written by an agent, thus prone to more slop. Lose their inherent value as soon as they are converted to code.
Specs are throwaway. They are a way to temporarily express behavior intent - an agent translates that to a version of code. That's the thing that lives forever.
If you are convinced that spec is code then you should be able to confidently delete all code and regenerate from specs.
English

This is what codebase documentation should be like.
Zero heuristics. All math. Why? Because this is the same data that can allow AI to KNOW your codebase. The only source of truth becomes the repo.
Stop dancing for the wild boar.
#coding #engineering #ai
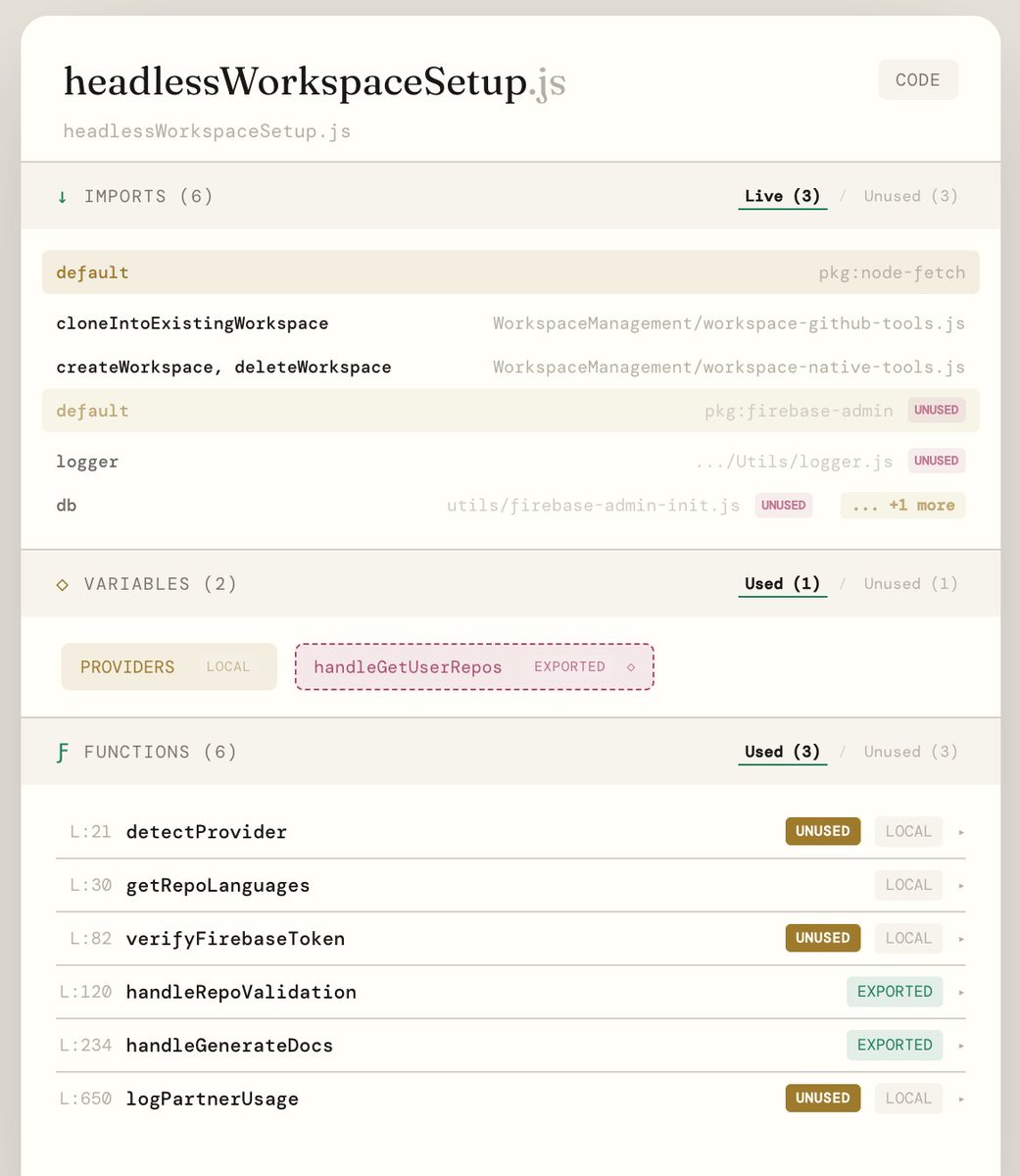
English
@agenticist Dead code, broken function contracts, unused variables, paths that can't execute from a code structural issue, case mismatches for Linux based systems, async mismatches, temporal ordering violations, etc.
English

@nicolekcha @ryancarson @linear One where your code lives as data and relationships between that data.
It looks like 6000 painful hours of R&D, that's what it really looks like. But, it works.
At the end of the day, all code is math one way or another. You just have to find the universal primitives.
English

English

The company that actually builds the agent-first code factory is going to be worth hundreds of billions of dollars.
No one has cracked it yet.
It can't be the model labs because then you're tied to one model.
I'm hoping a company like @linear will do this.
I'd happily pay thousands of dollars a month for that (+ the token cost).
Basically, we need SDLC 2.0 for the agent age.
(Also, the right solution can't rely on gh - we need whoever does this to completely replace it as well.)
English
@nicolekcha @ryancarson @linear and thank you by the way for comments on Evōk. It's been mind blowing after hacking away at code for 20+ years manually what I'm doing now.
English
Agree with the technicals. Your project looks really cool.
As an aside (unrelated to GitHub) I could also argue the reverse; Code is a lossy medium for human intent.
We all know this is how bugs happen; we didn't think of all the edge cases, so the code "perfectly" executes exactly what it was programmed to do.
LLMs are great at dealing with curveballs, though. Semantic instructions might not have planned for an edge case, but when encountered, still accomplishes what was intended.
By the way, while I agree with your premise, can you explain why specifically that incriminates Github?
English
Lossy as in text is a lossy medium. All errors in coding (related to the codebase proper) happen in the space between the compiler accepting the code and the human writing it.
The compiler doesn't get it wrong. Humans do because we're translating text as code into a machine-friendly language, that's teh whole promise of a programming language.
Code as text is a 'good enough' paradigm. If you want to move to provably safe/provably correct you change the medium to intent, and you store it with math.
English
English
@nicolekcha @ryancarson @linear It's a lossy medium at the end of the day. Not right for agentic coding in the long run.
English
@ryancarson @linear Agreed. But why replace Github? It seems like a solved primitive at this point.
English
@ryancarson @linear Doing it. Have full semantic understanding of even JS codebases. Can manipulate deterministically. No LLMs actually touch the codebase, and the codebase is stored as a model of its semantic intent (optionally, for now, we'll still let you store as boring old human written text)
English
@pzakin Provably safe AI engineering baked into the architecture that slashes token costs by 80% while performing purely deterministic manipulations of the actual codebase... made for the day 2 problem of AI coding, operating safely and inexpensively on legacy codebases.
English

The main themes I'm interested in right now:
- Sensors that agents need to make decisions. Their value increases as the cost of intelligence decreases.
- "Agent Society". Web 2.0 brought infra (identity) and apps that made it possible for individuals to safely and productively collaborate with people--even strangers--(share resources, pool resources, transact). The latest gen of the web--Agent Society--will do something similar for agents.
- New design patterns for agent work anticipate new agent-native infrastructure.
- I'm a big believer that markets seek radical choice. Accordingly, I think there will be a "Wario" stack of independent companies that work together to provide an alternative to the OpenAI regime that tends to embrace open standards, open source models.
- Coding agents are reliable enough that we should see increased demand from customers to customize their tools. Interested in companies that are complementary to this trend. I find the customizability of software to be underpriced by the market.
English