NVIDIA just dropped PersonaPlex-7B 🤯
A full-duplex voice model that listens and talks at the same time.
No pauses. No turn-taking. Real conversation.
100% open source. Free.
Voice AI just leveled up.
huggingface.co/nvidia/persona…
holy sh*t. this is hands down the coolest website i have ever found in my life. it's a live feed of the freaking Hubble Telescope AND James Webb Space Telescope. and the resolution is honestly so incredible i didn't think it was real.
unbelievable.
spacetelescopelive.org
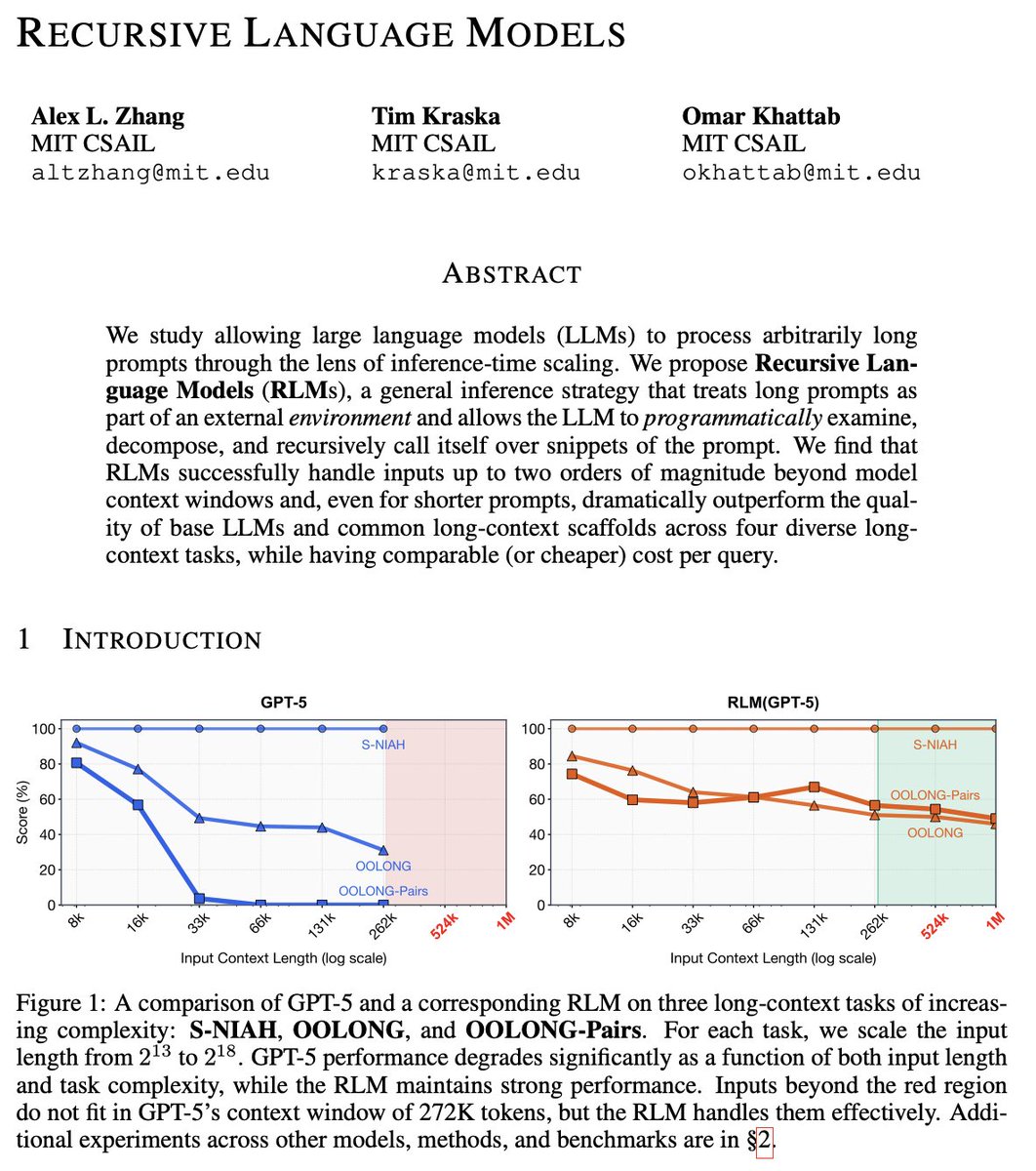
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
arxiv.org/pdf/2512.24601
New work: Do transformers actually do Bayesian inference?
We built “Bayesian wind tunnels” where the true posterior is known exactly.
Result: transformers track Bayes with 10⁻³-bit precision. And we now know why.
I: arxiv.org/abs/2512.22471
II: arxiv.org/abs/2512.22473 🧵
My brain broke when I read this paper.
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2.
It's called Tiny Recursive Model (TRM) from Samsung.
How can a model 10,000x smaller be smarter?
Here's how it works:
1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess.
2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens.
3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?"
4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer.
5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution.
Why this matters:
Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost.
Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability.
Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere.
This isn't just scaling down; it's a completely different, more deliberate way of solving problems.
Good post on evolving stablecoin market structure. I would extend it further: yes, I think that stablecoin issuers are going to have to share yield with others, but this is just one instance. Everyone is going to have to share yield. Today, the average interest on US savings deposits is 0.40% (FDIC data), and $4T of US bank deposits earn 0% interest.* Things aren't better in the EU: 0.25% average interest on non-corporate deposits; corporate deposits just 0.51%.** In my view, this is going to change: depositors are going to (and should!) earn something closer to a market return on their capital.
(Some lobbies are currently pushing, post-GENIUS, to further restrict any kinds of rewards associated with stablecoin deposits. The business imperative here is clear -- cheap deposits are great -- but being so consumer hostile feels to me like a losing position.)
* See FRED's memorably-titled QBPBSTLKDPDOFFDPNIDP time series.
** MIR.M.U2.B.L21.A.R.A.2250.EUR.N and MIR.M.U2.B.L21.A.R.A.2240.EUR.N from the ECB.
Vibe coding is broken.
You get pretty designs for quick dopamine hits. But nothing that’s actually useful – until now.
Introducing Endeva Apps, the most powerful idea to app platform – now in early preview.
Comment below and I will send you an invite code!
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention.
20+ labs just worked together to open source Genesis - a physics engine with a VLM agent that turns text prompts into interactive 4D worlds
Think instant physics-accurate environments, camera paths, and character animations - all from natural language 🤯
People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of "asking an AI", think of it more as "asking the average data labeler" on the internet.
Few caveats apply because e.g. in many domains (e.g. code, math, creative writing) the companies hire skilled data labelers (so think of it as asking them instead), and this is not 100% true when reinforcement learning is involved, though I have an earlier rant on how RLHF is just barely RL, and "actual RL" is still too early and/or constrained to domains that offer easy reward functions (math etc.).
But roughly speaking (and today), you're not asking some magical AI. You're asking a human data labeler. Whose average essence was lossily distilled into statistical token tumblers that are LLMs. This can still be super useful ofc ourse. Post triggered by someone suggesting we ask an AI how to run the government etc. TLDR you're not asking an AI, you're asking some mashup spirit of its average data labeler.