
Deeju
907 posts

Deeju retweetledi


@iamsupersocks Ça me fait marrer la meta de communication de ces gars, ils foutent volontairement un extrait hors sujet d'un JV pour ragebait et ça contribue fortement à augmenter leur reach. C'est maîtrisé
Français
Je vis pour ça. Pas besoin de grand-chose, juste me balader sur Google Earth avec ce bijou.
Nona@Nona_xai
🚨 ULTIMA HORA : Google acaba de convertir Street View en un simulador del mundo real. Genie 3 ahora puede recrear cualquier entorno físico a partir de las imágenes de Street View. Google lleva filmando el planeta desde 2007. Miles de millones de calles, edificios y barrios enteros almacenados en sus servidores. Durante años, todo el mundo pensó que era solo para orientarse. Era en realidad la mayor recopilación de datos del mundo real de la historia. Y acaban de decidir hacer algo con ello.
Français
Deeju retweetledi

I built "zero2claude", a free course that takes people from zero terminal experience to shipping with Claude Code.
The curriculum goes from absolute zero → software basics → Claude Code fundamentals → advanced usage. No shortcuts, no assumptions.
17,000+ students. 7 languages. ~500 active hourly.
No marketing. No ads. Pure word of mouth.
The entire platform? Built and operated by one person
with Claude Code.
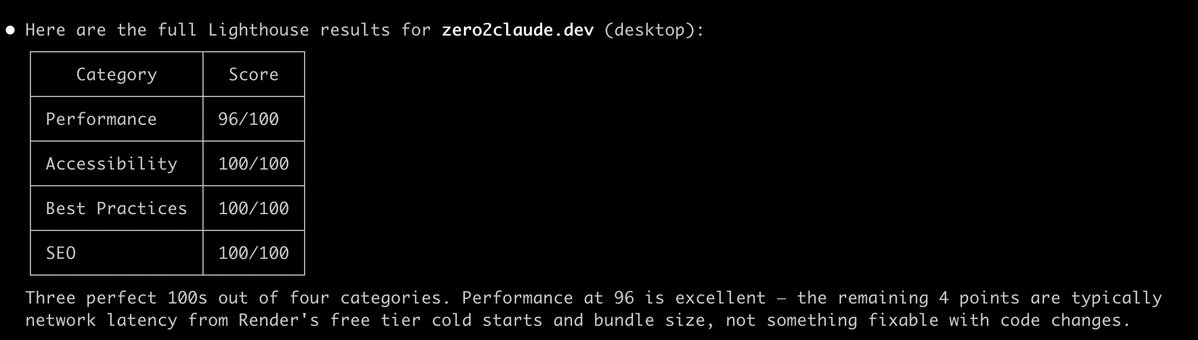
Lighthouse audit:
✅ Performance : 96
✅ Accessibility : 100
✅ Best Practices : 100
✅ SEO : 100
Production stats:
~6.4M requests/day. 74 req/sec sustained. <0.003% error rate.
Claude Code doesn't just write code. It builds production-grade, scalable products.
The best way to grow Claude Code adoption isn't to simplify the tool. It's to level up the people. Give fishing rods, not fish.
Free. No paywall. My contribution to the community.
Link in the comments 👇


English

L'IA c'est la version tech du pire de la tendance body positive, faire croire que les mauvaises habitudes et/ou le manque d'intelligences ne sont qu'une question de perspective.
Avec un branding hérité de la crypto et du business facile type dropshipping.
Tout ne serait qu'une question d'une ou plusieurs actions à mener et hop, amour gloire et beauté.
Ça ne pas rend les cons moins cons qu'avant.
Français
Hmmmmm ça va être tout noir
Het Mehta@hetmehtaa
Every 3rd website you visit runs Nginx. 18,959,833 of them can be hijacked right now. A bug from 2008 just got a working exploit. CVE-2026-42945 (CVSS 9.2) No login. No access. Just one HTTP request. → Heap overflow → Worker process → RCE Patch ASAP to Nginx 1.31.0 or 1.30.1 PoC is already out: github.com/DepthFirstDisc…
Français
Deeju retweetledi

@ALeaument Camarade, juste t'évite de causer du libre, en plus d'être ridicule tu es une insulte aux dev du logiciel libre. </ THANK YOU FOR YOUR ATTENTION TO THIS MATTER>
Bluetouff.
Français
Deeju retweetledi

Deeju retweetledi

Quelques statistiques intéressantes sur le bilan environnemental de l'IA trouvées sur le blog du chercheur Andy Masley :
Bilan carbone de l’entraînement de Chat GPT 4 :
Entraîner GPT-4 a consommé l’énergie nécessaire à alimenter la ville de San Francisco pendant trois jours. Mais Chat GPT-4 est un produit qui a été utilisé par des centaines de millions de personnes pendant deux ans. À titre de comparaison, la fabrication des Iphones 16 a consommé l’énergie nécessaire à alimenter la ville de San Francisco pendant treize ans.
Bilan carbone de l’entraînement de Chat GPT 4 : 15 000 tonnes de CO2, soit les émissions annuelles de 1 550 citoyens américains.
C’est inférieur au bilan carbone de la fabrication des chaussures Nike vendues sur une seule journée ou à celui de la fabrication des Légos vendus sur un mois. Si l'on pense qu'il aurait été bénéfique pour la planète d'empêcher l'entraînement de GPT-4, il faudrait aussi envisager d'arrêter la production de Lego pendant un mois.
Bilan carbone de l’inférence :
Une requête ChatGPT moyenne consomme autant d'énergie qu'une recherche Google en 2008 (la dernière fois où Google a indiqué la consommation d'une recherche).
Même en incluant les « coûts cachés » comme l'entraînement, les émissions liées à la fabrication du matériel, l'énergie utilisée pour le refroidissement et les puces d'IA en veille entre les prompts, le coût carbone d'un prompt moyen représente moins de 1/150 000ᵉ des émissions quotidiennes d'un Américain moyen (0,00067 %).
La consommation d’eau :
Les data centers aux États-Unis ont consommé 0,2% de l’eau douce du pays en 2023.
L’IA ne représente que 20% de la consommation des data centers. Elle consomme donc 0,04% de l’eau douce américaine (ceci inclut la consommation d'eau pour produire l'électricité alimentant les data centers).
Il est prévu que ce chiffre triple d’ici 2030, atteignant 0,12% de la consommation américaine d’eau douce. Cela équivaudra à 8% de la consommation d’eau par l’industrie du golf aux États-Unis.
En 2030, les data centers d'IA consommeront annuellement autant d'eau que 0,07 % de la population américaine.
À l’échelle individuelle, un prompt consomme 0,2 ml d’eau (à nouveau, en incluant l’eau utilisée pour produire l’électricité utilisée par le datacenter). Quotidiennement, avant l'arrivée de l'IA, l'Américain moyen utilisait l'eau équivalente à 800 000 prompts.
Quelques équivalences consommation d’eau/prompts:
Chaussures en cuir : 4 000 000 prompts
Smartphone : 6 400 000 prompts
Jean : 5 400 000 prompts
T-shirt : 1 300 000 prompts
Une feuille de papier : 2 550 prompts
Un livre de 400 pages : 1 000 000 prompts
Chaque seconde passée à marcher dans la rue use un peu vos chaussures, qui finiront par devoir être remplacées. Or, leur fabrication nécessite de l'eau. Andy Masley calcule que chaque seconde de marche consomme en moyenne autant d'eau que 7 prompts. Rester assis devant son ordinateur permet donc d'économiser de l’eau.
Tout cela sans évoquer tous les bienfaits environnementaux qui seront apportés par l’IA (efficacité des chaînes d’approvisionnement, découvertes scientifiques, libération de ressources à investir dans le renouvelable, etc.)
Andy Masley@AndyMasley
There are so many insane wildly misleading stories coming out about data centers almost every day now that I'm mostly having to give up on commenting on them to focus on actually getting blog posts out, but it feels like a tsunami. I'll share one from just today as an example.
Français
@JuWeb1 Pas le budget surtout mais content que tu aies la vision.
Français
2.5x the speed at 6x the cost. Y a un problème dans l’équation, non ?
Cursor@cursor_ai
Fast mode for Claude Opus 4.7 is now available in Cursor! It's 2.5x the speed at 6x the cost. For most tasks, we recommend using the standard speed.
Français
Deeju retweetledi

Deux voies : vendre de la data/expertise propriétaire ou du compute/infra. En gros, un stage de pilotage au Nürburgring vs du SP98.
Paul Lê@paulichon
Les entreprises techs ont toujours été les plus friandes à prendre des solutions SaaS pour optimiser leurs opérations et se focus sur le core de leur produit. C'étaient les early adopters des SaaS, la première marche de clients de beaucoup de startups. Le cycle était simple : on prend plein d'abo SaaS, on se focus sur notre produit, et quand la boite scale, on garde ou on arrête les solutions. On optimise nos dépenses. Desormais, cette première marche n'existe plus. On vibe code notre besoin principal, et on se focus à shipper notre produit core. On ne se force même plus à regarder les solutions de marché, comparer les produits etc. Les saas sont entrain de perdre la premiere marche de leur GTM pour se concentrer vers des TPE, des ventes plus longues etc. Google, Anthropic, xAI, OpenAI ne sont peut-être pas en train d'éteindre le SaaS, mais ils réalignent clairement leur GTM. La compétition c'est code maison vs SaaS.
Français
Deeju retweetledi
D'accord avec Ethan.
Beaucoup imaginent encore que l’IA dans des utilisations avancées reste un truc de lab à San Francisco.
En réalité les modèles sont globaux et les workflows sont locaux.
Tout le monde les a déjà.
Le moat devient :
→ la data métier
→ les agents branchés aux outils internes
→ les gens assez curieux pour expérimenter des workflows avant les process officiels.
Les use cases les plus violents ne sont probablement même pas sur Twitter. Les meilleurs viennent souvent de personnes qui connaissent un métier par cœur et qui commencent à brancher agents, automatisations et outils internes dans leur quotidien.
Ethan Mollick@emollick
I think we are past the point where “only people in San Francisco get AI” is true. AI users are in every industry & they have access to the same models. SF is far from the epicenter of many of the craziest use cases I have seen in science, law, finance, marketing, education…
Français
Deeju retweetledi

@chrisramsay52 What you see is not the shape of the object itself but a known flare that happens when a bright object is directly in frame of a FLIR camera, the video feed is inverted so it appears black

English

Real-time World Models are the next AI frontier.
Today, we @reactorworld are taking the first step towards this reality: our early preview lets you experience worlds generated in real-time, running on our global low-latency infrastructure.
Try it now: reactor.inc
English

Deeju retweetledi

Le nouveau pas de tir du Starship est un monstre.
Il a encaissé sans broncher un tir statique de 14s avec 33 moteurs Raptors qui lui crachent à bout portant quelques milliers de tonnes de poussée.
Tout est démesuré dans ce projet.
Français