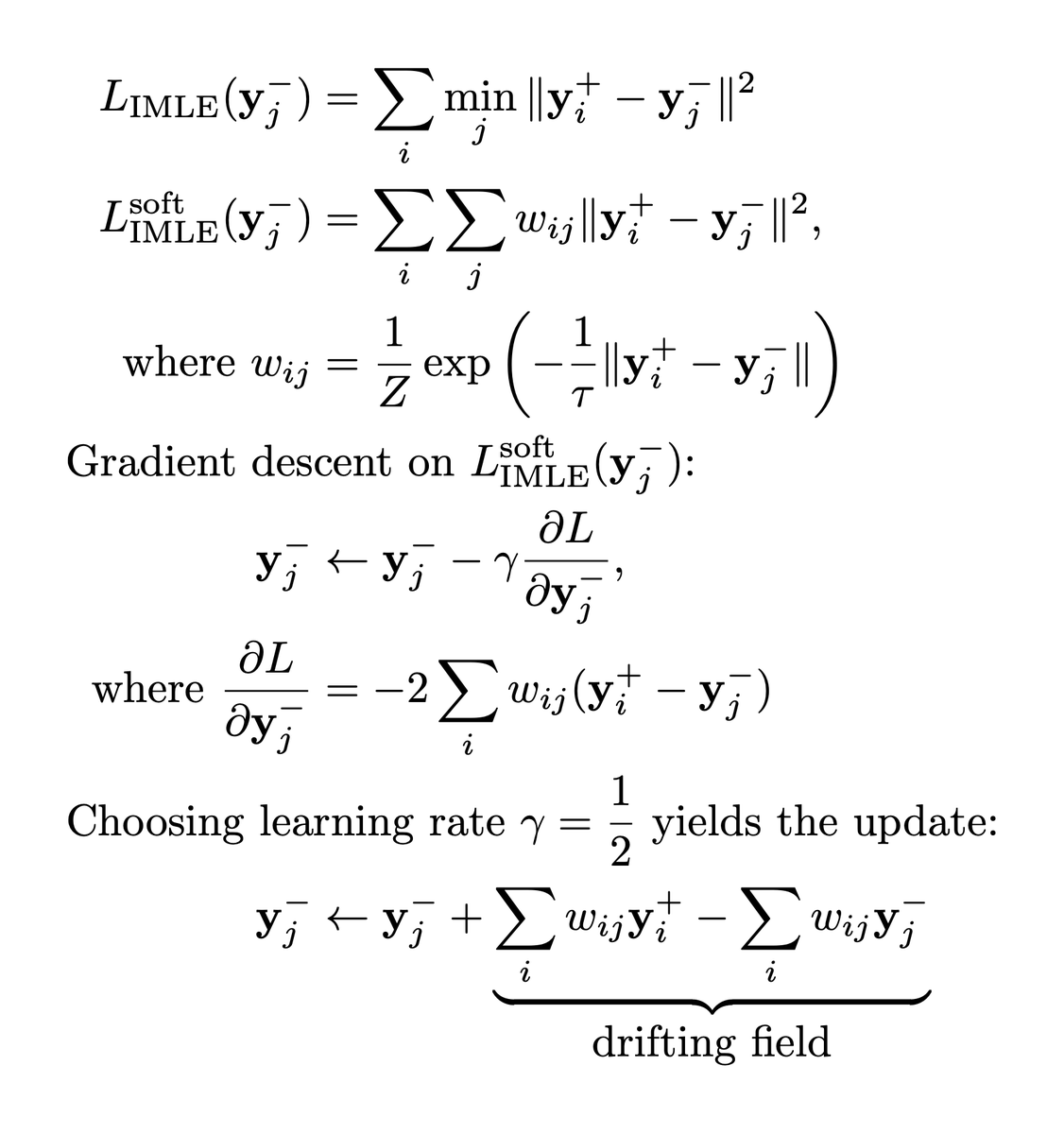Ivan Skorokhodov@isskoro
The recent Drifting Models paper from Kaiming's group got very hyped over the past few days as a new generative modeling paradigm, but in fact, it can actually be seen as a scaled-up/generalized version of the good old GMMN from 2015 (and the authors themselves acknowledge this in the paper in Appendix C.2, noting that GMMN can be seen as Drifting Models for a particular choice of the kernel). Also, I am very skeptical about its scalability (for higher diversity / higher resolution datasets, larger models, and videos).
The way Drifting Models work is actually very simple:
- 1. Sample random noise z ~ N(0, I)
- 2. Feed it to the generator and get a fake sample x' = G(z)
- 3. For each fake sample x', compute its similarity (in the feature space of some encoder) to each of the real samples x_i from the current batch.
- 4. Push it closer toward these real samples using the similarities as weights (i.e. so that we push to the nearest ones the most).
- 5. To make sure that we don't have any sort of mode collapse, repel each fake sample from other fake samples via the same scheme.
- 6. Profit
Now, GMMN follows exactly the same scheme, with the only difference being that it uses a different (unnormalized) function in the "distance computation" and doesn't allow for cleanly plugging in normalization/scaling in the similarity scores or CFG.
Why didn't GMMN take off and why am I skeptical about Drifting Models? The issue is that it makes it much harder to compute any meaningful similarity when your dataset gets more diverse (happens when you switch to foundational T2I/T2V model training), or the batch size gets smaller (happens when your model size or training resolution increases), or your feature encoder produces less comparable representations (happens for videos or more diverse datasets). You can sure get informative similarities for 4096 batch size on the object-centric, limited diversity ImageNet with ResNet-50 feature encoder, but for smth like video generation, we train on hundreds of millions of videos or, at high resolutions + larger model sizes, with a batch size of 1 per GPU (not sure if will be fast to do inter-GPU distance computations).
From the theoretical perspective, even though the final objective and the practical training scheme are the same, the mathematical machinery to formulate the framework is very different and enables direct access to the drifting field (e.g., to easily enable CFG which the authors already did). But I guess what I like the most about this paper is that Kaiming's group is boldly pushing against the mainstream ideas of the community, and hopefully it will inspire others to also take a look at the fundamentals and stop cargo-culting diffusion models.