career update:
i have joined @smallest_AI as a researcher engineer to work on improving small models and scale them.
hoping to contribute a lot to the team and product!
Career update:
Excited to share that I have joined the incredible team at @smallest_AI to work on Research x Devrel!
The team is cooking incredible small + efficient multi-modal models and it feels like an exciting time to push the frontier on scale!
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Att…
Out of context reasoning is one of the most fascinating developments in the science of how LLMs work. This primer by @OwainEvans_UK, one of the main discoverers of the phenomena, is a great introduction
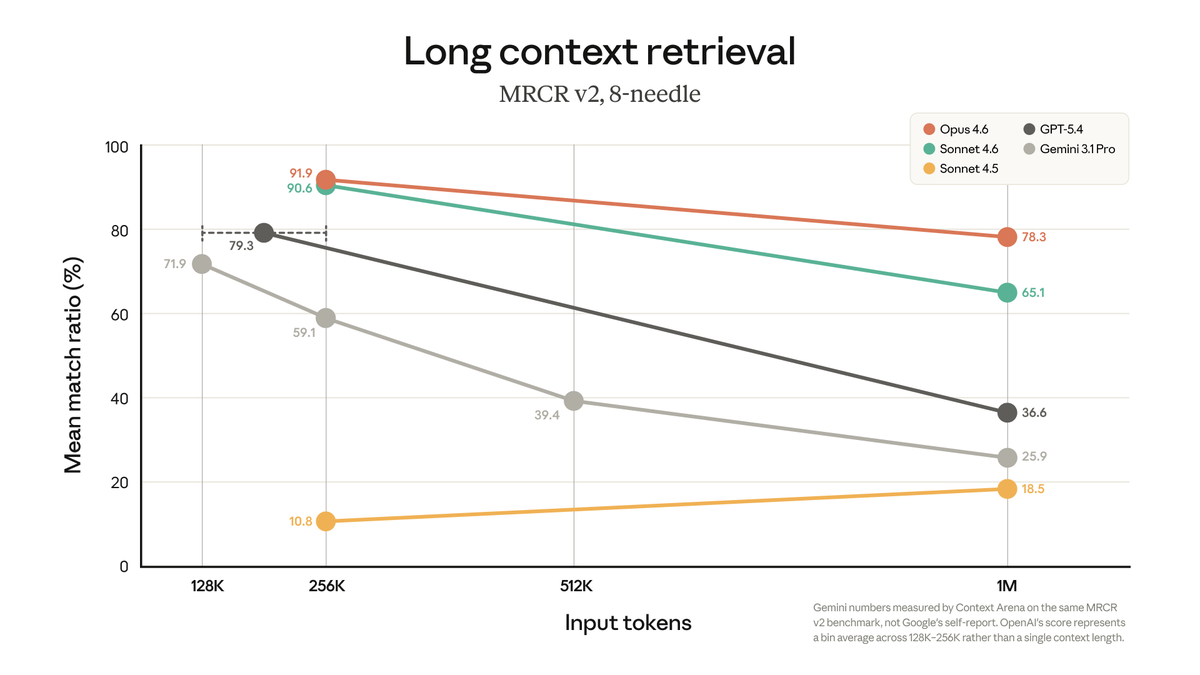
Another week, another noteworthy open-weight LLM release. Nvidia’s Nemotron 3 Super 120B-A12B looks pretty good.
Benchmarks are on par with Qwen3.5 122B and GPT-OSS 120B, but the throughput is great!
Below is a short, visual architecture rundown.
🎉 CUDA 13.2 just dropped, and GPU programming just got simpler.
This release expands CUDA Tile support to Ampere and Ada GPUs while delivering a stronger CUDA Python stack for cluster-scale workloads.
What's new:
✅ Install cuTile Python directly from PyPI: pip install cuda-tile
✅ Enhanced CUDA Python profiling and debugging across Numba-CUDA flows and Nsight tools
✅ Modern CUDA C++ and refreshed math libraries optimized for AI and HPC kernels
Ready to accelerate your workflows?
📝 Read the technical deep dive: nvda.ws/4rZtAq1
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages.
Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…
We're publishing a new evaluation suite and research paper on Chain-of-Thought (CoT) Controllability.
We find that GPT-5.4 Thinking shows low ability to obscure its reasoning—suggesting CoT monitoring remains a useful safety tool. openai.com/index/reasonin…
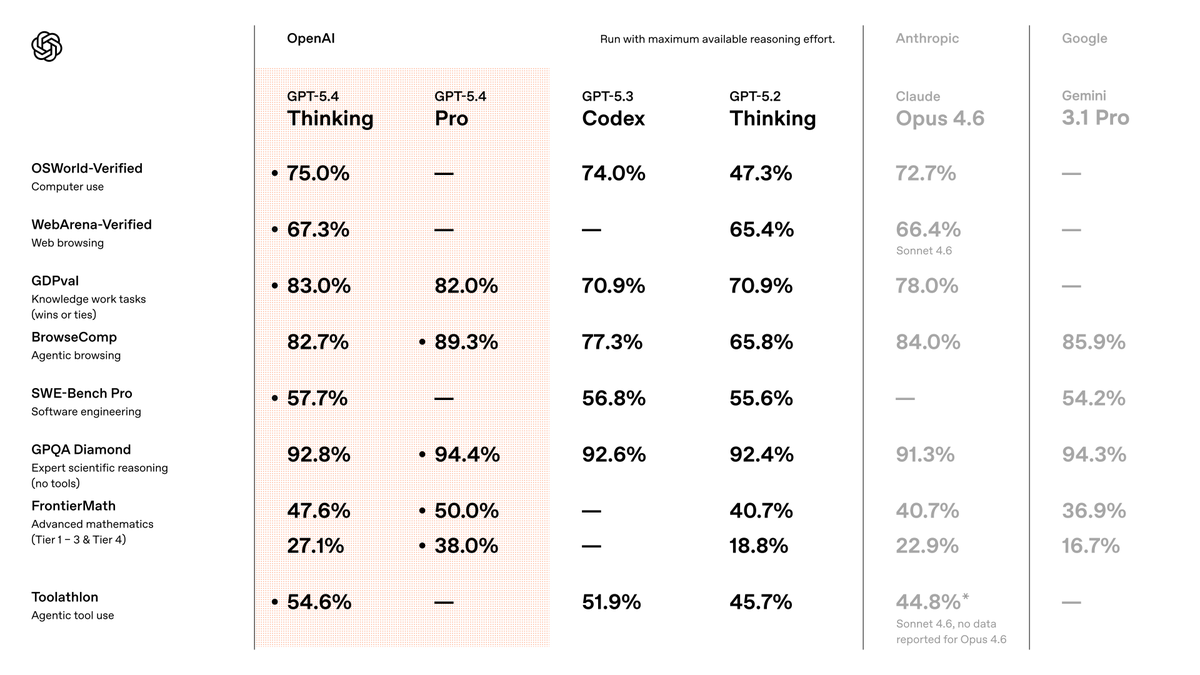
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model.
We’re launching Nano Banana 2, built on the latest Gemini Flash model. 🍌
It’s state-of-the-art for creating and editing images, combining Pro-level capabilities with lightning-fast speed. 🧵
Drop 3/4:
NanoTok
The fastest BPE tokenizer in written in C++ and wrapped in Python for api reference. Upto 32x faster encode, 24x faster decode vs tiktoken & HF Tokenizers (varies for different model configs). Peaks at 33M tokens/sec encode, 69M tokens/sec decode. Benchmarked across GPT-2, CL100K, O200K, Qwen 2.5, Mistral & Gemma 2 on Wikipedia, Code, News, Math datasets.
github.com/0xD4rky/nanotok