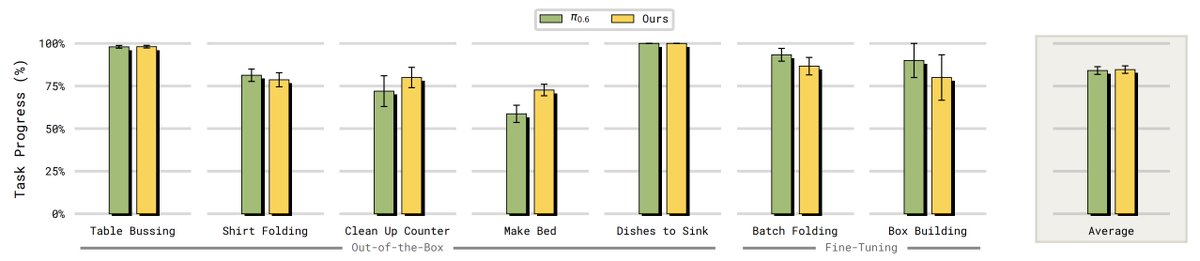
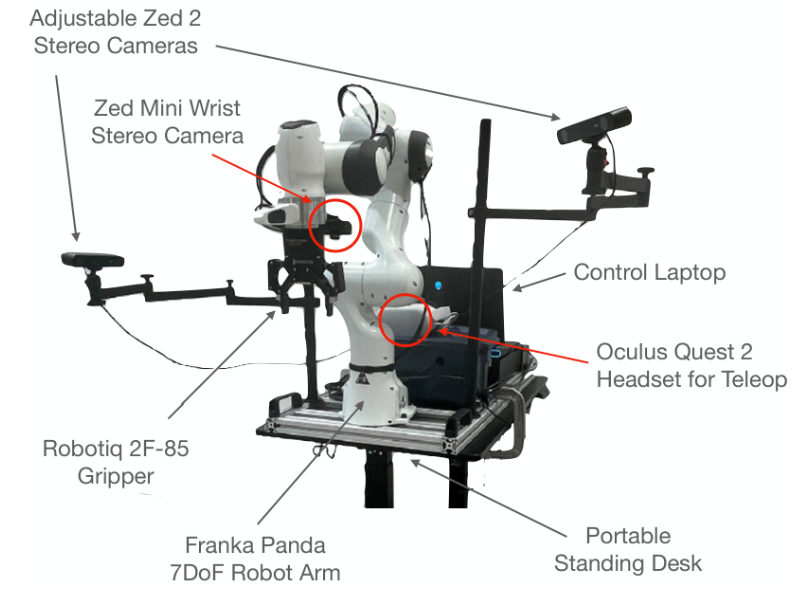
Sabitlenmiş Tweet

This one has been a long time coming: today we’re introducing MEM, an approach for giving VLAs short-term and long-term memory.
Memory is such an obvious capability, but adding it isn’t easy (most VLAs today are memory-less). A short thread on challenges, solutions, and the new capabilities MEM unlocks for us.
English