

Kaveh Alim retweetledi

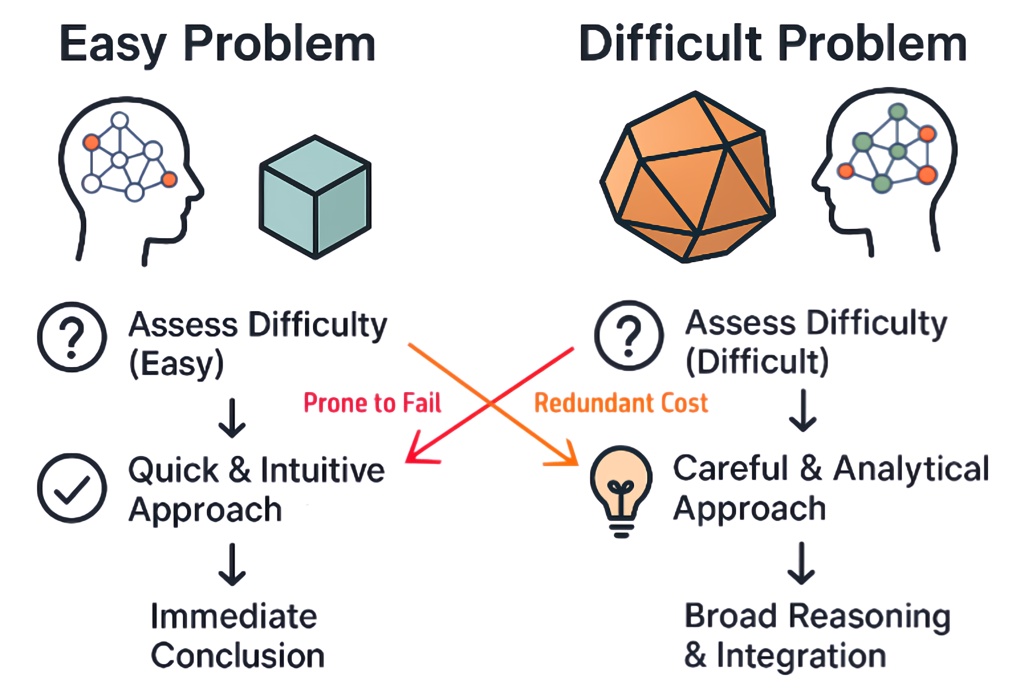
🧠 Inference-time scaling lets LLMs spend more compute to solve harder problems, but not every question needs that!
After all, we don’t use a whiteboard to solve 1 + 1. So why should an LLM?
Introducing Instance-Adaptive Inference-Time Scaling, a smarter way to allocate compute during inference.
💡 By calibrating PRMs, we can estimate how likely each reasoning step is to lead to a correct answer. This lets us:
- Use less compute on easy questions and on likely incorrect reasoning paths
- Spend more compute on harder questions and on promising reasoning steps
🎯 Same accuracy, up to 50% less compute.
Paper → arxiv.org/abs/2506.09338
Code → github.com/azizanlab/inst…
Calibration dataset → huggingface.co/datasets/young…
Calibrated PRMs → huggingface.co/collections/yo…
Joint work with @KGreenewald, @KavehAlim, @HW_HaoWang, and @NavidAzizan.
English