Navid Azizan retweetledi

LMI-Net: Linear Matrix Inequality–Constrained Neural Networks via Differentiable Projection Layers
Sunbochen Tang, Andrea Goertzen, Navid Azizan
arxiv.org/abs/2604.05374 [𝚌𝚜.𝙻𝙶]

English
Navid Azizan
105 posts


@NavidAzizan
MIT Prof | AI & machine learning, systems & control, optimization | Fmr postdoc @Stanford, PhD @Caltech






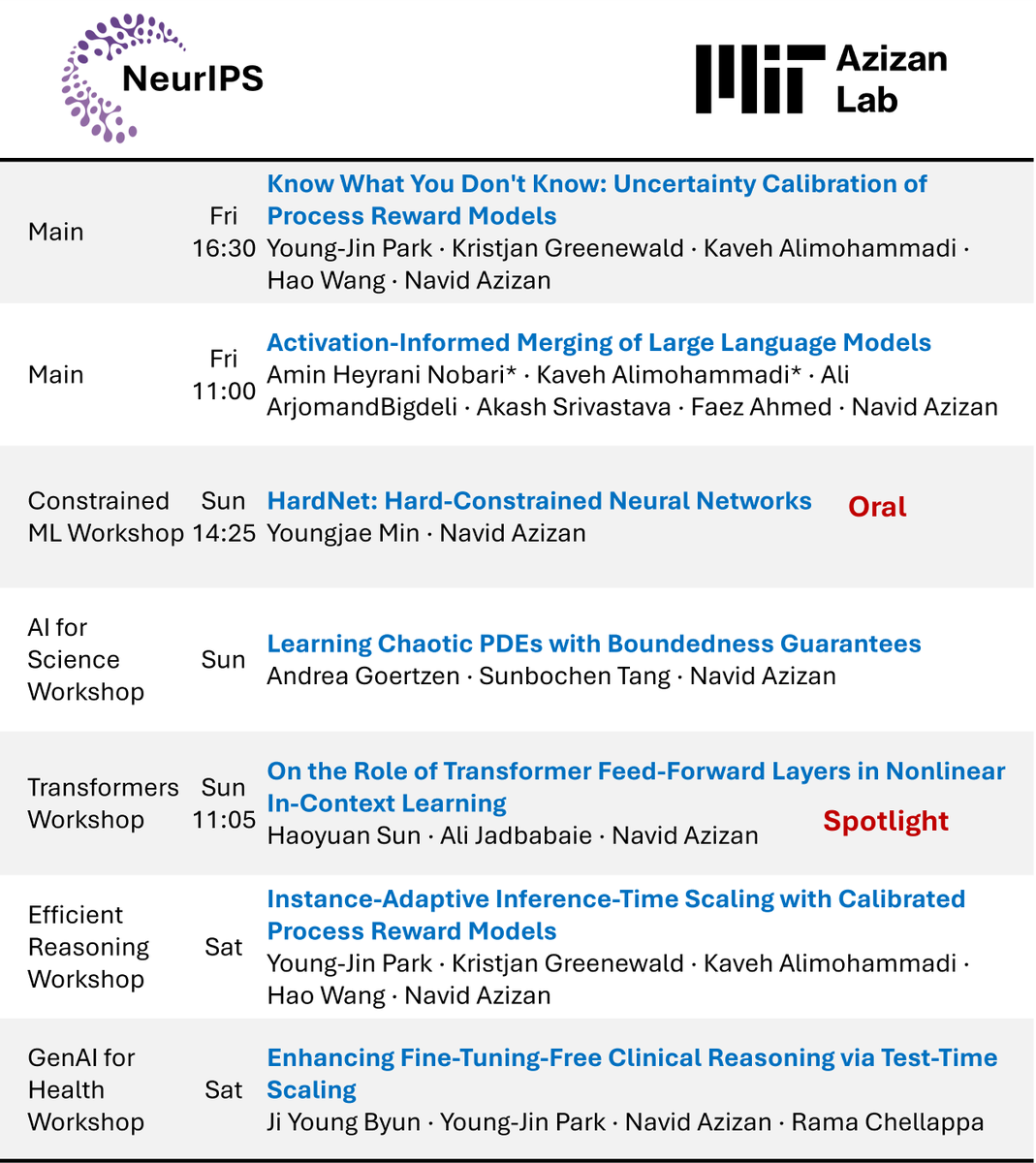

🧠 Inference-time scaling lets LLMs spend more compute to solve harder problems, but not every question needs that! After all, we don’t use a whiteboard to solve 1 + 1. So why should an LLM? Introducing Instance-Adaptive Inference-Time Scaling, a smarter way to allocate compute during inference. 💡 By calibrating PRMs, we can estimate how likely each reasoning step is to lead to a correct answer. This lets us: - Use less compute on easy questions and on likely incorrect reasoning paths - Spend more compute on harder questions and on promising reasoning steps 🎯 Same accuracy, up to 50% less compute. Paper → arxiv.org/abs/2506.09338 Code → github.com/azizanlab/inst… Calibration dataset → huggingface.co/datasets/young… Calibrated PRMs → huggingface.co/collections/yo… Joint work with @KGreenewald, @KavehAlim, @HW_HaoWang, and @NavidAzizan.







How to assess a general-purpose AI model’s reliability before it’s deployed. A new technique from MIT LIDS researchers @NavidAzizan and Young-Jin Park enables users to compare several large models and choose the one that works best for their task. bit.ly/3zNWiEf


The National Academy of Engineering is excited to welcome 114 new members and 21 new international members to the NAE Class of 2024! Congratulations to this incredible group of innovators. #NAE2024 Find the complete list of newly elected members here: ow.ly/V4Gj50Qyvjl

