Kenneth Wolters retweetledi

Knowing what to build, for who, and how to get them to use it is actually harder
mert@mert
the funny thing about ai is the people who think writing software was the hard part of building a company
English
Kenneth Wolters
426 posts

@KenWltrs
Marching the realms of bits and atoms (especially cells). Obsessed about neural nets and embeddings.
the funny thing about ai is the people who think writing software was the hard part of building a company








LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below


🚀MIT Flow Matching and Diffusion Lecture 2026 Released (diffusion.csail.mit.edu)! We just released our new MIT 2026 course on flow matching and diffusion models! We teach the full stack of modern AI image, video, protein generators - theory and practice. We include: 📺 Videos: Step-by-step derivations. 📝 Notes: Mathematically self-contained lecture notes 💻 Coding: Hands-on exercises for every component We fully improved last years’ iteration and added new topics: latent spaces, diffusion transformers, building language models with discrete diffusion models. Everything is available here: diffusion.csail.mit.edu A huge thanks to Tommi Jaakkola for his support in making this class possible and Ashay Athalye (MIT SOUL) for the incredible production! Was fun to do this with @RShprints! #MachineLearning #GenerativeAI #MIT #DiffusionModels #AI

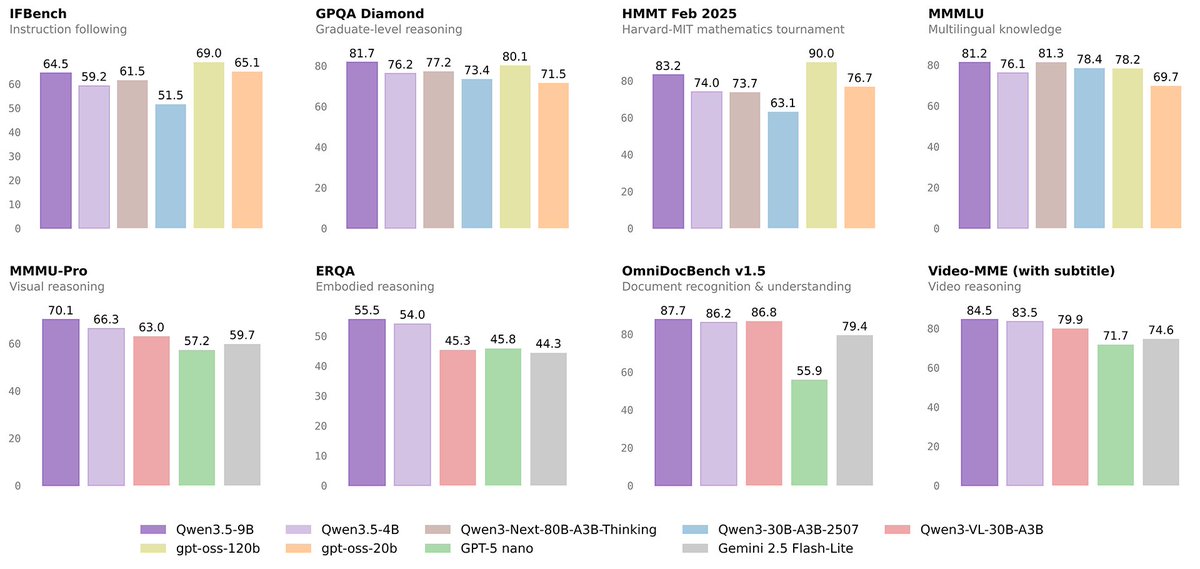
Software development jobs grew 10% over the last year while the overall market declined 5.8%. Quite the narrative violation.




