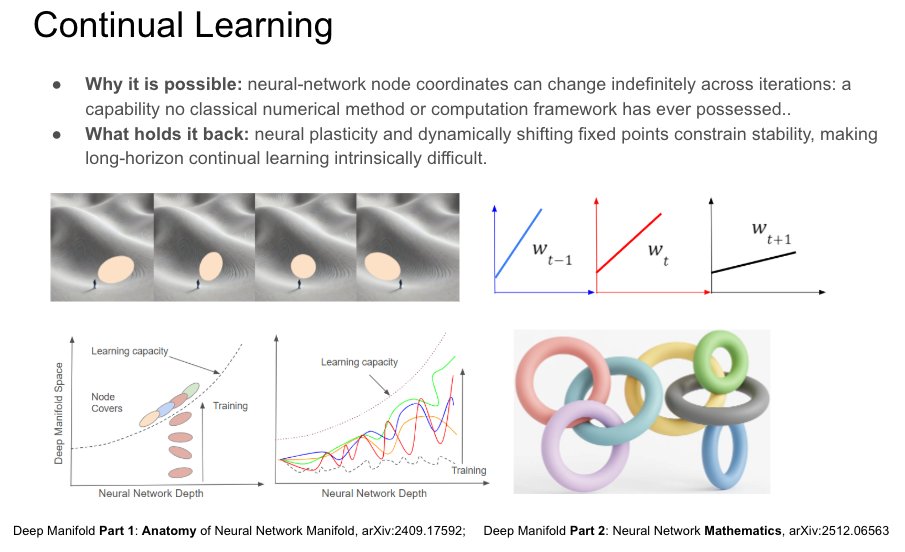
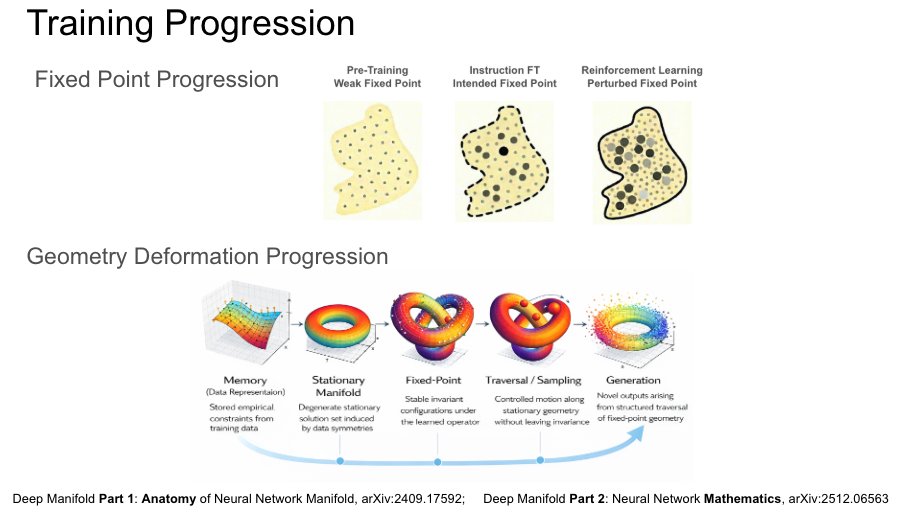
Sabitlenmiş Tweet

Job opportunity: the Open-Endedness Team at @LilaSciences is seeking a talented research engineer who would enjoy applying your wizard-like technical skills to genuinely deep and fundamental AI research into the algorithmic basis of creativity and innovation.
This role is about radical innovation at the research frontier and 10xing the capabilities of research scientists running world-changing experiments (we're not talking about “business solutions”): data pipelines, large models, distributed training, optimizing not just for current algorithms, but for exotic new approaches as well. We want our algorithms operating as efficiently as possible and scaling as seamlessly as possible as hardware resources expand. If that sounds exciting, apply below👇
English