Sabitlenmiş Tweet

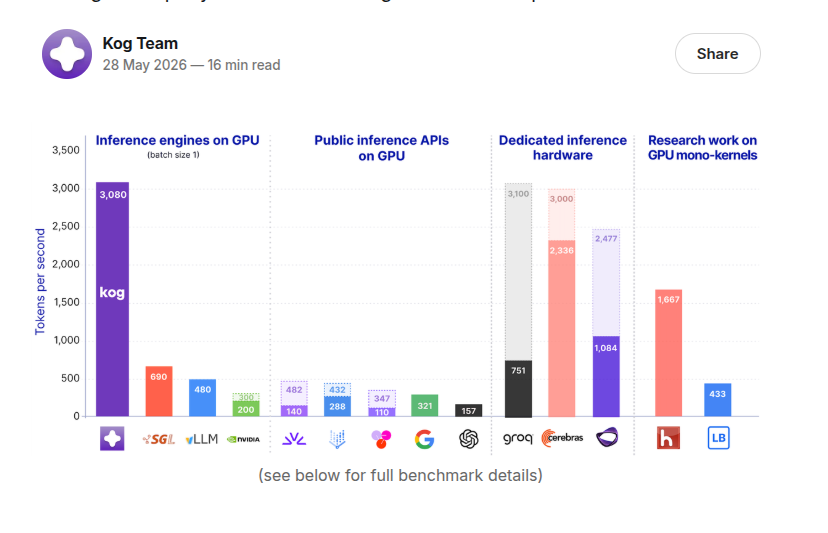
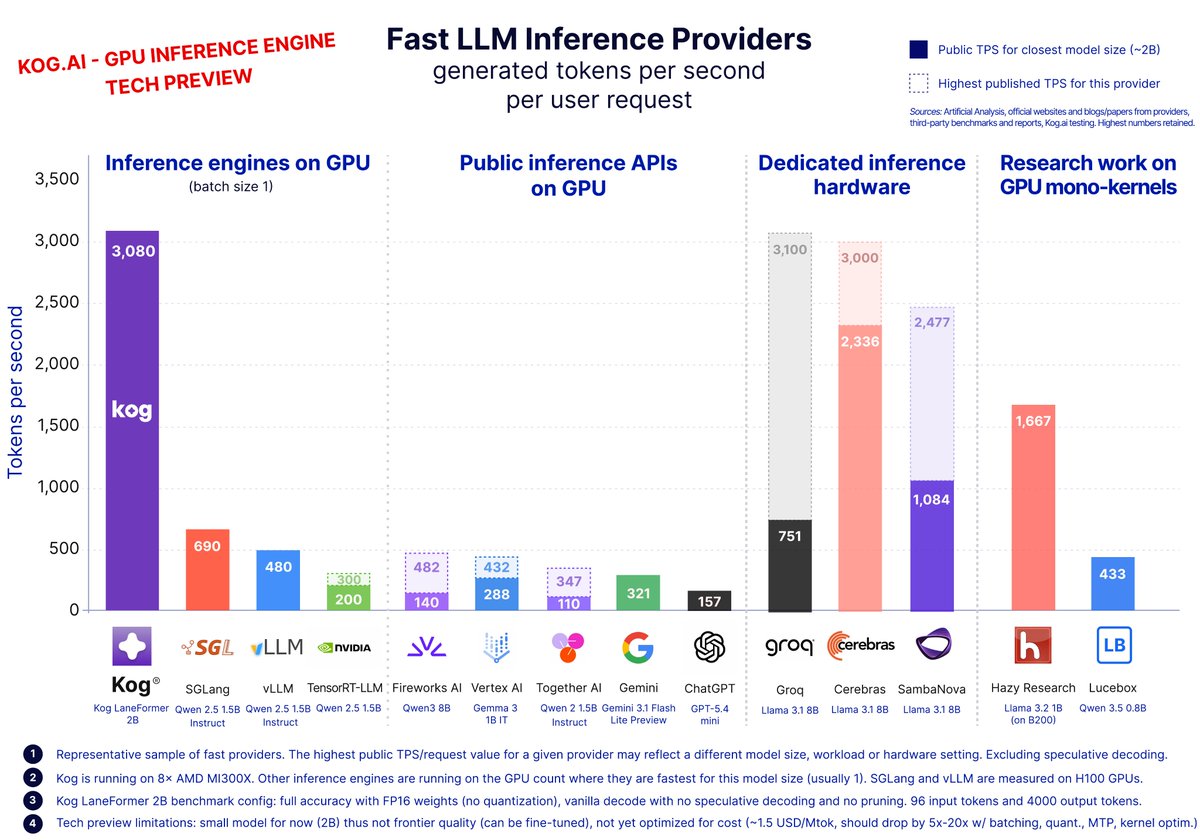
🚀 Launch today: Kog generates 3,000+ output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-…
📖 Monokernel deep dive → blog.kog.ai/building-a-sin…
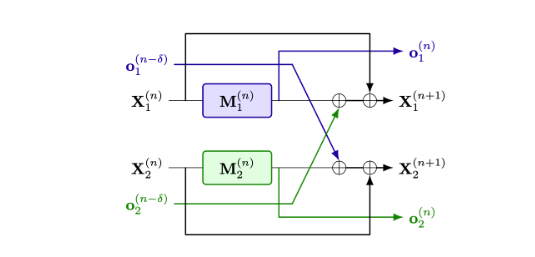
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor…
read the thread 👇
English