
Eli Kravitz
409 posts
Eli Kravitz
@KravitzEl
Medical statistician and obsessive dog owner. I use twitter to follow specific trustworthy news sources and scientific research. I'm boring, but well informed.
Katılım Mayıs 2013
354 Takip Edilen31 Takipçiler


@rmkubinec It looks like the meta analysis was done on the log-odds scale then exponentiated. That’s why the regression line is curved.
English

Hmmm, what do you all think of that plot? It's showing the "average odds ratio" which means averaging logs... which is a linear operation on a nonlinear function...
Steve Stewart-Williams@SteveStuWill
Meta-analysis of field studies on gender bias in hiring: Three key findings 1. In male-dominated/gender-balanced fields, male applicants were favoured before 2009, but since then, there’s been no consistent bias or even a weak pro-female bias.
English
@RitchieVink Pandas is so bad that people paid $4M to make something new.
English

I am very excited to announce that Polars raised a $4M seed round!
Chiel Peters and I co-founded Polars the company. Read more on what we will build!
pola.rs/posts/company-…
English

@Lach_cribb It’s not strictly necessary. Each model term does something different. Intercept is average at t=0. Time is the overall trend. Everyone starts in a different place (random slope) and deviates slightly from the trend over time (random intercept), The remaining difference is error.
English
@Lach_cribb @matloff The idea of “de-correlating errors” might come from different, simpler models where you can’t include time as a covariate. In an analysis with two time points, random effects are the only way to induce correlation (that I’m aware of at least).
English
@sharoz @Lach_cribb This is a really nice illustration. Thanks for sharing.
English

@Lach_cribb This may help give a visual explanation of why conditioning on the subject is what you want
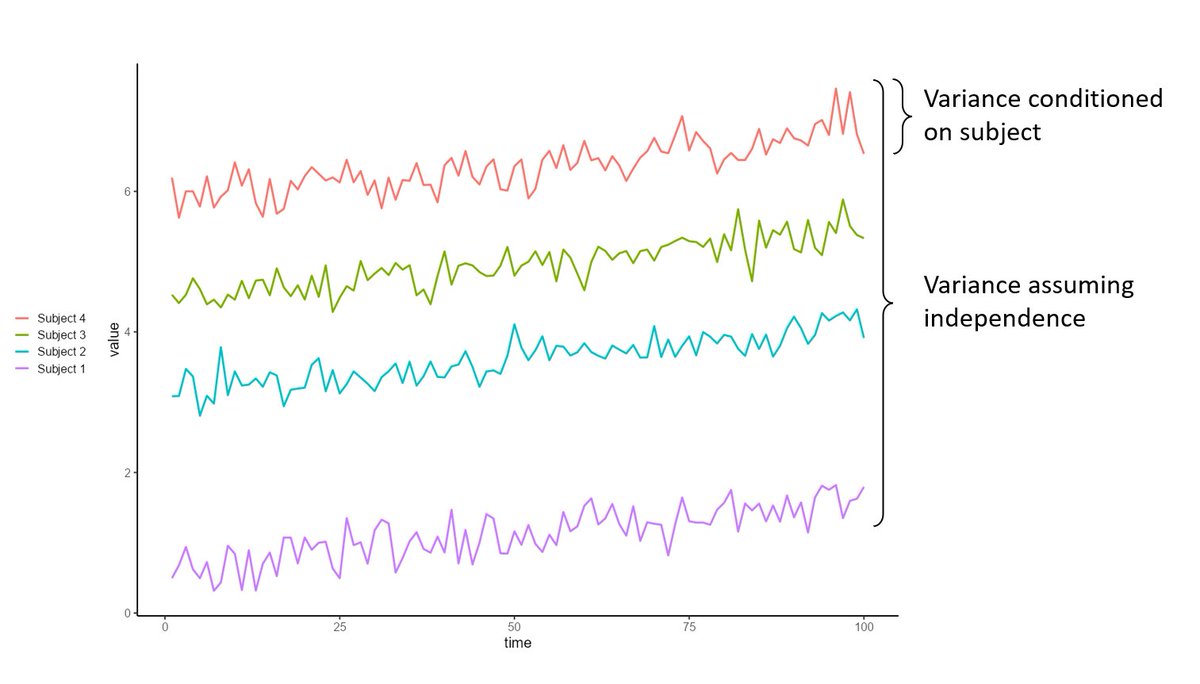
English
@JamieLarsH @jimthommo Normal priors with large variances are standard for regression coefficients. The unknown precision parameters (inverse variance) for the random effects can be modeled with gamma distribution or uniform distribution.
English

@jimthommo @KravitzEl "Quick" follow-up question: How to deal with and think about setting priors?
This is always my Bayesian's achilles heel. Any one have thoughts/suggestions about dealing with that with bayes-hms? /2
GIF
English
R/stats Q-- How/are a *bayesian* hierarchical models different than linear mixed models?
I was doing some alternative models to COMBAT (harmonization), broadly inspired by Bayer et al.'s NeuroImage work & wanted to make sure I wasn't missing something?
sciencedirect.com/science/articl…
English
@JamieLarsH Hierarchical models are the Bayesian analogue of Frequentist mixed models.
English

Just saw Across the Spiderverse and damn, I’d that isn’t the kind of movie that reminds you how great movies can be. Visually stunning, great characters, good messages.
Makes me wish there were more films worth going to theaters for. It’s so nice.
English
@DeandaSharone @BariAWilliams @RobWPowell @theziturs @ProfMMurray That’s the Supreme Court’s interpretation. Bari’s suggestion would use the same logic the Supreme Court just rejected. If Biden did that, it would be rejected by the court for the same reason. They probably wouldn’t even take the case.
English

@KravitzEl @BariAWilliams @RobWPowell @theziturs @ProfMMurray I think that’s one interpretation but it does not negate Bari’s comment
English

I hope folks know where to place the blame for the failure of student loan forgiveness. Say what you will about Joe Biden, but he did what he promised. And it was absolutely undone by the Court that his predecessor built.
English
@Hornofplenty05 @PFF_College He’s focused. He’s having fun. I wouldn’t be surprised if he’s a dark horse for the Heisman.
English


Who’s a player who felt like they played College Football forever?

English
@ShoarinejadA That’s not really a fair question. Those programming languages exist to do the MCMC sampling for you. There’s no Frequentist equivalent because you don’t need to draw samples when you fit Frequentist models.
English

Probabilistic programming languages like Stan, PyMC, etc., provide the flexibility to model various data generating processes (DGPs). Are there any Frequentist equivalents for modeling DGPs, or are frequentists usually limited to predefined models? #stats
English
@noah_greifer Germán Rodríguez has very detailed course notes that are easy to follow. I really recommend his notes over a specific textbook. grodri.github.io/survival/
English

I'm really trying to figure out survival analysis and am seeking recommendations for learning materials, which can be of any form, ideally oriented towards junior biostats PhD students, i.e., getting into the weeds of estimation and inference for basic methods. Thanks!
English
@super_jrub There might be some theory from functional data analysis. The abstract of this paper looks promising. If nothing else, it might have some good references. jstor.org/stable/20441490
English

Statistics and statistics-adjacent friends!
Is there a hypothesis test to determine whether there is a significant difference between two curves at a given time point?
English
@jcomndz @super_jrub @ShenRaphael How would you bootstrap thag? Under the null, only two points (the value on each curve at the time point time point) are exchangeable.
English

@super_jrub @ShenRaphael You can do a bootstrap. See Tibshirani, R.J. and Efron, B., 1993. An introduction to the bootstrap. Monographs on statistics and applied probability, 57(1).
English
@ChelseaParlett I’ve seen people check if their experimental data varies with time with this method. You would plot the principle components against the time axis to see if they’re correlated. You could do the same thing to see if the PCs vary by batch? stats.stackexchange.com/a/267831
English

Have you all heard of this before??
I’m not quite following.

English

If you were to revise John Kruschke’s textbook, "Doing Bayesian data analysis" (sites.google.com/site/doingbaye……), what cuts, additions, and other changes would you make?
#Rstats #rjags #mcmcstan
English