Sabitlenmiş Tweet

A LinkedIn scroll led to an uncomfortable question: how good is my RAG system, really?
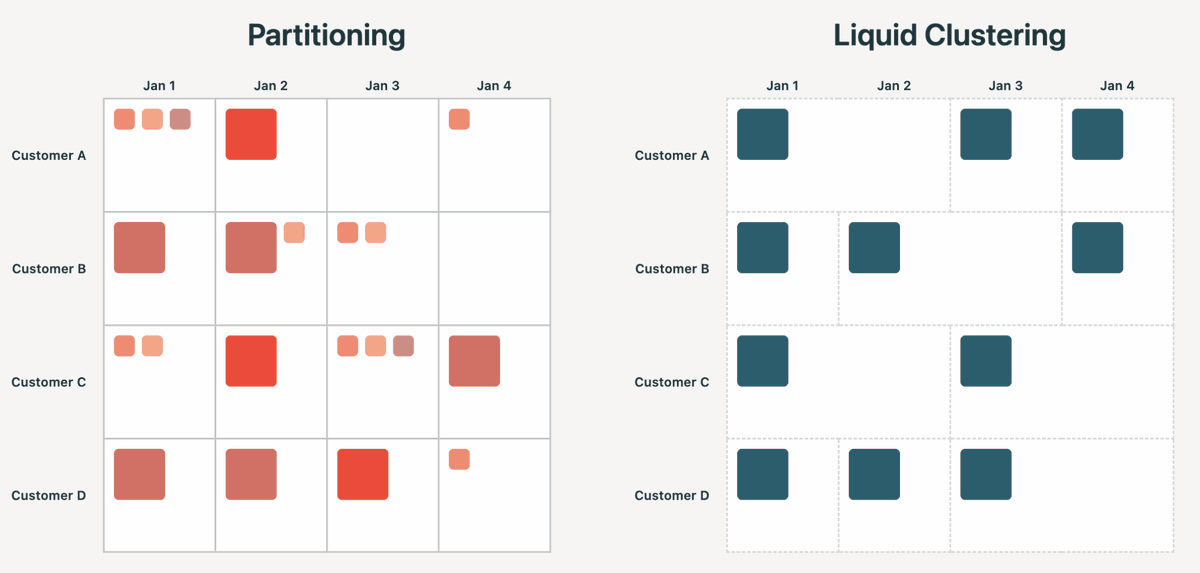
@Databricks' Compact Guide to RAG gave me a way to find out — 42 implementation points, 8 categories, no ambiguity.
I benchmarked vikaa.ai, my personal AI learning lab, against every point. The answer was humbling. 6.0 / 10.
Not because of missing features — because of invisible ones. Built but not wired. Measured but not enforced. Sophisticated on the surface, leaking quality underneath.
I fixed it. Three sessions. 9.0 / 10.
This series is that journey — 8 parts, one component each, every gap named and every fix documented.
Personal prototype. Framework credit: @Databricks
#RAG #Databricks #BuildInPublic

English