
@0xSero how does one get an api which doesn't use the data for training?
English
Divyansh Singh
89 posts
@L2_cache_miss
L2 cache in gpus | prev research @adobe | cs grad @IITKanpur

@nrehiew_ thank you
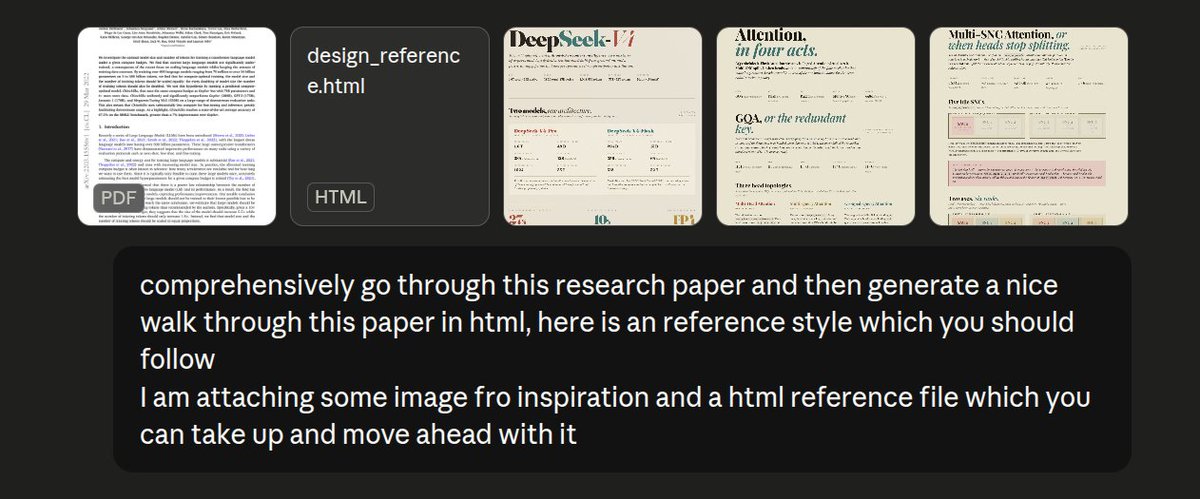
@nrehiew_ this is very addictive btw... my weekly limit was resetting tonight so I generated html walkthroughs of multiple papers from my reading list... it is so much fun to read this way first and then trace back in the paper... thanks a lot @nrehiew_



Now reading:


🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n


the new anthropic scam is to publicly reset usage limits every 6 days and 23 hours
we're rolling codex out to whole companies/enterprises. ping me gdb@openai.com if of interest!

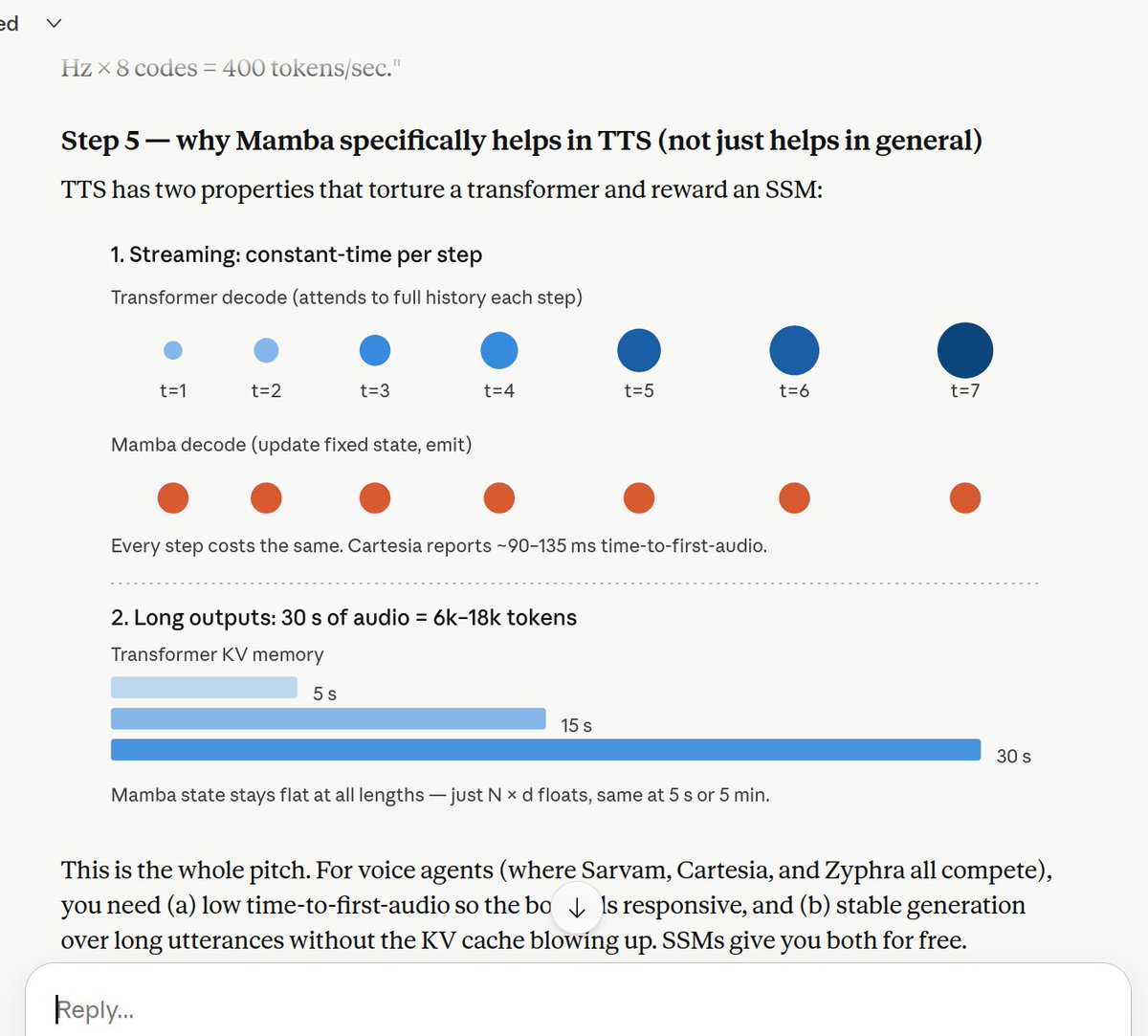

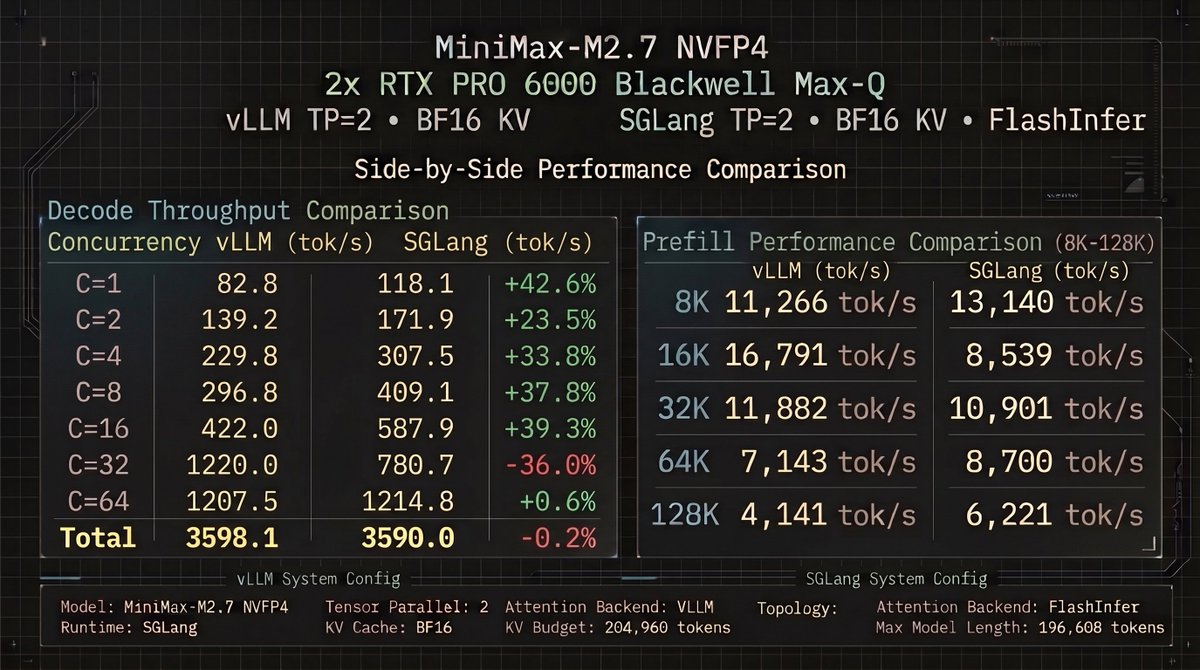
Finally putting these RTX 6000s to good use. Minimax M2.7 running locally. There have been learning curves indeed. Running NVFP4 with full 16-bit KVCache @ with a 140K context window. I can get a full 200K context window but only with vLLM, which is slower. I think I'll opt for the speed, I dont need 200K anyway. Dedicating my free time to leveling up my game. Thanks to everyone who's helping me. YKWYA 🫶

We've redesigned Claude Code on desktop. You can now run multiple Claude sessions side by side from one window, with a new sidebar to manage them all.







