
Leonidas Pitsoulis
84 posts

Leonidas Pitsoulis
@LPitsoulis
Professor @ Electrical Engineering and Computer Science, University of Thessaloniki
Thessaloniki, Greece Katılım Ekim 2011
200 Takip Edilen48 Takipçiler

Andrej Karpathy just put out this tool that looks at AI's impact on job.
He also deleted the original Github repo very quickly.
Basically, he pulled 342 job types from the Bureau of Labor Statistics and had an LLM score each one from 0 to 10 based on AI exposure.
The average exposure score is 5.3. Move the score, move the probability it will get wiped out by AI.
- Software developers 9/10,
- medical transcriptionists are a 10/10.
- Lawyers 8/10
- General Office clerks 9/10
Basically any screen-based jobs are in trouble.
$3.7T annual wages in high-exposure jobs (7+)
pre-computed as ∑(BLS employment count × BLS median annual wage) over exactly those occupations whose Gemini Flash score is ≥7.
English
@Old_Samster All of these methods find local solutions at best, which can, and mostly are, very far from the true global solution. But its true that most problems are at their core optimization problems, equilibria in game theory, deep learning, minimum entropy problems etc
English

@chatgpt21 all the knowledge of building a C compiler is given, it was build in those 37 years, thats the actual work not the coding
English

Anthropic had 16 AI agents build a C compiler from scratch. 100k lines, compiles the Linux kernel, $20k, 2 weeks.
To put that in perspective GCC took thousands of engineers over 37 years to build. (Granted from 1987 - however) One researcher and 16 AI agents just built a compiler that passes 99% of GCC's own torture test suite, compiles FFmpeg, Redis, PostgreSQL, QEMU and runs Doom.
They say they "(mostly) walked away." But that "mostly" is doing heavy lifting.
No human wrote code but the researcher constantly redesigned tests, built CI pipelines when agents broke each other's work, and created workarounds when all 16 agents got stuck on the same bug.
The human role didn't disappear. It shifted from writing code to engineering the environment that lets AI write code.
I don’t know how you could make the point AI is hitting a wall.
English
@helloiamleonie @vintrotweets @plasticlabs well vector store retrieval with semantic similarity is prediction
English

i'm clearly biased but this is the most interesting take on agent memory i've seen so far.
(yes, forget the "filesystem vs database" discussion)
a few weeks back i had a nice chat with @vintrotweets from @plasticlabs and their approach is:
memory is not a retrieval problem.
memory is a prediction problem.
i'm slowly catching up on my reading list. but this one is definitely worth a read: blog.plasticlabs.ai/blog/Memory-as…

English

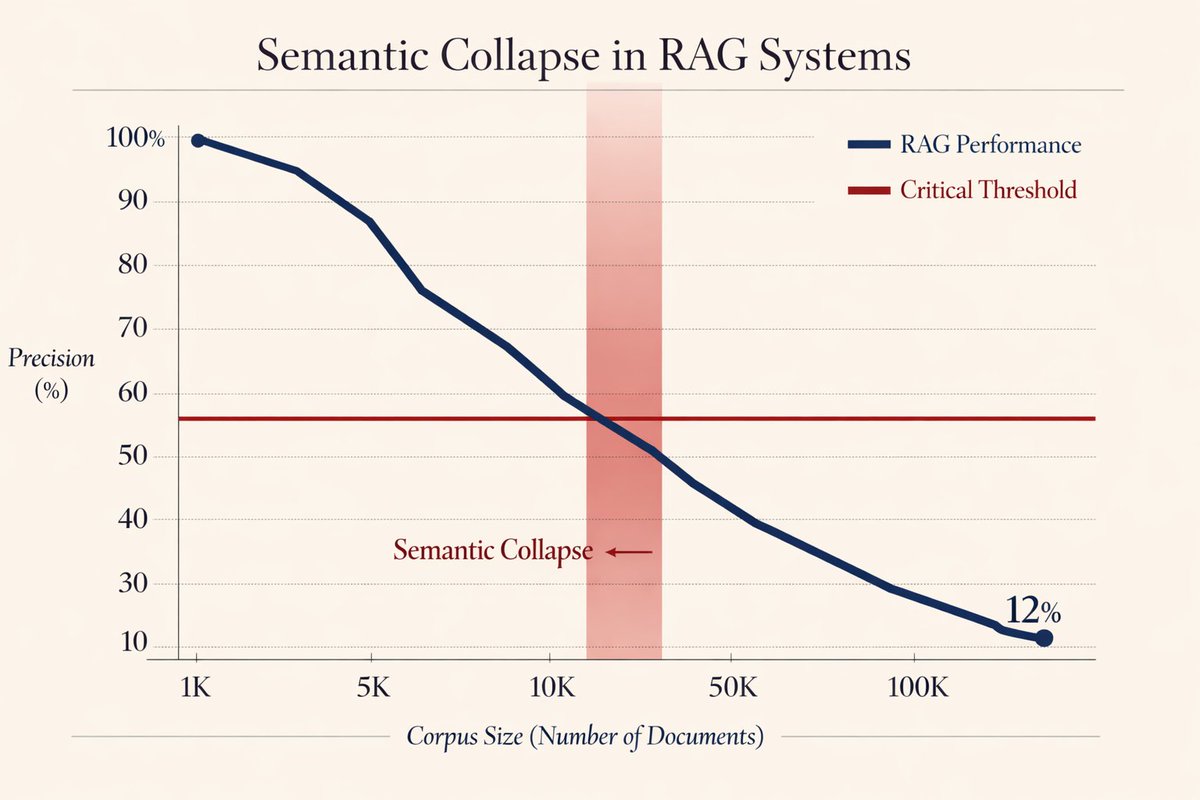
Holy shit... Stanford just killed the entire RAG industry.
They just exposed the fatal flaw killing every "AI that reads your docs" product.
It's called "Semantic Collapse", and it happens the moment your knowledge base hits critical mass.
Here's the brutal math (and why your RAG system is already dying):
English
@hasantoxr Fail to see the connection between the curse of dimensionality and semantic retrieval; the embedding dimension is fixed, it does not increase with the number of documents.
Can see a case for overlapping clusters of vectors as the number of documents increase asymptotically
English
@NathanJRobinson AI like any other tool such as books and the internet will be adopted to the maximum by the academia and be employed for the pursuit of of knowledge and free rhinking, which AI cannot do
English

Today in Current Affairs, professor Ron Purser exposes how AI's destruction of the university is even worse than you think, and goes well beyond students cheating with ChatGPT: currentaffairs.org/news/ai-is-des…

English
@rohanpaul_ai finally a proper paper which is not just an announcement
English
The paper presents GigaEvo, an open toolkit where language models and evolutionary search work together to solve hard optimization puzzles.
It reimplements the AlphaEvolve idea in open source so other groups can reproduce results and easily change the setup.
GigaEvo treats each Python program as a candidate, runs it on a task, scores quality, and stores code, metrics, and ancestry in a shared database.
An evolutionary loop keeps better programs, discards invalid or weak ones, and uses a quality diversity method that preserves many strong but different solutions.
A configurable pipeline runs stages that execute code, check constraints, measure complexity, and ask models to produce feedback and lineage summaries explaining changes.
The mutation component builds prompts from the task description, parent code, metrics, and insights, then asks a model to rewrite the program.
Using this system, GigaEvo closely matches or slightly improves AlphaEvolve on Heilbronn triangle placement and circle packing and reaches strong kissing number configurations.
It discovers competitive bin packing heuristics and strong prompts and agents for Reddit rule classification, showing this recipe works across different problems.
----
Paper – arxiv. org/abs/2511.17592
Paper Title: "GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms"

English

Sharing an interesting recent conversation on AI's impact on the economy.
AI has been compared to various historical precedents: electricity, industrial revolution, etc., I think the strongest analogy is that of AI as a new computing paradigm (Software 2.0) because both are fundamentally about the automation of digital information processing.
If you were to forecast the impact of computing on the job market in ~1980s, the most predictive feature of a task/job you'd look at is to what extent the algorithm of it is fixed, i.e. are you just mechanically transforming information according to rote, easy to specify rules (e.g. typing, bookkeeping, human calculators, etc.)? Back then, this was the class of programs that the computing capability of that era allowed us to write (by hand, manually).
With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective. This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something. The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made).
The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm. If it is not verifiable, it has to fall out from neural net magic of generalization fingers crossed, or via weaker means like imitation. This is what's driving the "jagged" frontier of progress in LLMs. Tasks that are verifiable progress rapidly, including possibly beyond the ability of top experts (e.g. math, code, amount of time spent watching videos, anything that looks like puzzles with correct answers), while many others lag by comparison (creative, strategic, tasks that combine real-world knowledge, state, context and common sense).
Software 1.0 easily automates what you can specify.
Software 2.0 easily automates what you can verify.
English
@justalexoki speculation is the driving force for crypto
English


@ylecun @RnaudBertrand its called the “if its not local its better” complex, very common in the Europa old countries
English

Europe has original ideas and the technical talents to implement them.
The main reason why the European tech industry is small is a mistaken assumption of technological inferiority on the part of the European media. Perhaps more importantly, there was a similar inferiority complex on the part of investors, which made them less willing to take risks when the mere possibility of an American competitor would rear its head. That has been changing over the last few years.
Not sure I would call this a lack of patriotism. More like a lack of self-confidence.
English

I just read this WSJ article on why Europe's tech scene is so much smaller than the US's and China's.
I'm afraid that, like most articles on this topic, it largely misses the mark.
Which in itself illustrates a key reason why Europe is lagging behind: when you fail to understand the root causes of an issue, you have zero chance to solve it.
What makes me competent to speak on this topic?
Back in the late 2000s and early 2010s, I founded and led HouseTrip which at the time was one of Europe's top startups. We were the first historical startup in which all top 3 VC investors in Europe invested.
So I have a pretty intimate knowledge of the European entrepreneurship ecosystem and what it takes to create and grow a tech company in Europe.
We were pretty promising as a startup. In fact as promising as it can possibly get.
We had a similar concept to Airbnb (with some notable differences I won't bore you with), except we created the company 1 year before they did. Which means we were the first-mover - globally - with a multi-billion-euro concept, strong financial backing by the 3 top investors in Europe and, at some point, a team of 250 people with some of the brightest minds in tech in Europe. Everything we needed to succeed.
And yet we didn't succeed: ultimately we were essentially crushed by our American competitor Airbnb in our home turf - Europe - and we had no choice but to sell ourselves to another American company, Tripadvisor.
Believe me, I've reflected long and hard on how that could have happened. In fact after I left the company in 2015 I even spent 3 months in isolation in the Annapurna mountains in Nepal to reflect full time on exactly that 😅
And I then moved to China, where I spent the next 8 years and where I had the chance to study their ecosystem to understand why they're successful and Europe isn't.
So all in all, I think I have some degree of legitimacy to comment on this topic.
The WSJ article says that Europe lags behind due to the usual suspects, the reasons you constantly hear about: too much regulation, fragmented European markets, limited access to financing, a culture that isn't conducive to the startup grind, etc.
Some of those are true, but imho all are secondary.
Take excessive regulations for instance, which gets mentioned all the time. If they were such a hindrance to startups, why would American startups succeed in Europe - like Airbnb in our case - and European startups not? We all face the same regulations 🤷
Or take fragmented markets. Same question: how could US startups successfully conquer these fragmented EU markets when European startups can't?
Because that's the real elephant in the room, and really the story of the European tech scene since the advent of the internet: US startups have shown a remarkable ability to capture European markets despite the supposed barriers, making many of the "usual suspects" explanations for Europe's tech struggles very unconvincing.
In other words, logically, any explanation where both US and European startups face identical barriers fails to address the fundamental difference in outcomes we consistently observe.
Based on my experience, the key problem faced by European startups can be summarized in one word: patriotism.
There is virtually none in Europe, and more than anything that's what's killing EU startups, or preventing them from developing.
It used to drive me absolutely nuts at HouseTrip. What a startup needs first and foremost, especially a consumer-facing startup like we were, is marketing, to become famous.
At first, when I created the company and before Airbnb was even a thing, I used to pitch the company to the media and the general response I would get was almost one of contempt, as in "why would I belittle myself to write about your startup? And furthermore, who would be stupid enough to stay in an apartment when there are hotels? You guys have no future..."
And then Airbnb got launched and the American media started their thing, hyping the company like it was the greatest innovation since sliced bread, like they were national heroes, giving them hundreds of millions in free publicity.
That's when European media started to take notice. Not of us, god forbid, but of Airbnb. The concept was promoted by Silicon Valley, see... so now it was valid.
So I went back to pitch HouseTrip to European media. This time around I was met with a different kind of contempt: "So you guys are like Airbnb? Why would we cover a European copycat when we can just write about the real American original?" Luckily I'm not violent but lets say those moments really tested my civility 😅
All in all, we arrived in the absolutely grotesque situation where, despite Airbnb not having yet set foot in Europe, they were already a cultural phenomenon there, promoted by European media, for free, when the European original - yours truly - had to spend millions on paid marketing (mostly to Google and Facebook, American companies) to achieve a small fraction of the brand recognition.
Which means that, insanely, Airbnb was probably doing more business in Europe than we did before even opening an office there, simply on the back of the free publicity they were getting. How on earth can you even compete with that?
This dynamic was at play with general European elites too. I remember very clearly having dinner next to a legendary European entrepreneur and investor - who I won't name, a man who supposedly, on paper, is dedicating his life to furthering the European tech ecosystem. We naturally got to talk about HouseTrip and he literally told me, and this is an exact quote: "you know I don't really like copycats, they really hurt the European ecosystem." Another big test for my civility that night...
And even if we had been a copycat, so what? That's how China got started, there's nothing to be ashamed of. You need to learn to walk before you can run.
In fact if you study the history of innovation you'll find that every major tech power, including the US, started by imitating and adapting others' innovations before developing their own.
Speaking of China, again a country that I know in depth for having lived there for 8 years after HouseTrip, I've come to the conclusion that patriotism, a deeply rooted mindset of sovereignty, is truly the magic ingredient behind their success.
Contrary to popular belief, they don't do it in a stupid way by just banning competition. Those cases are actually very rare and only occur if the companies in question violate Chinese law in pretty egregious ways.
Most of the time it's the exact contrary: they welcome foreign companies and competition, but create conditions where local alternatives can thrive alongside them, giving Chinese users and businesses legitimate options to choose domestic champions.
Which means you end up with, for instance, Apple doing well in China but simultaneously allowing the rise of Huawei or Xiaomi. Or Tesla doing well in China but simultaneously allowing the rise of BYD or Nio. Etc.
And China is, interestingly, more comparable to the EU than most people realize. It is, again contrary to popular belief, extremely decentralized when it comes to doing business, with various provinces competing against each other much the same way EU countries compete against each other.
But they do it in such a way where, again, the overarching sense of Chinese sovereignty never gets sacrificed at the altar of provincial competition. And where the ultimate goal is to develop Chinese champions which can successfully compete on the global stage.
So there you have it, the dirty little secret behind Europe's lag. We're essentially witnessing a "colonization of the minds" whereby Europe has structurally internalized its technological inferiority, celebrating American startups while dismissing its own homegrown companies.
Why does this barely ever get talked about? Think about it: do you seriously think that the Wall Street Journal would start advocating for, essentially, policies hostile to American tech dominance?
Much better to focus on the usual red herrings like too much regulation or fragmentation which, conveniently, would primarily result in clearing obstacles for American tech giants to dominate European markets even further, rather than nurturing homegrown competitors. This article is, in itself, an illustration of the "colonization of the minds".

English

When we Chinese were building the Great wall, we were firm believers in the "scaling law": If we were to build a wall just long enough, it would be sufficient to defend the enemy from the north. However magnificent an engineering marvel that was, it is just a wall after all, not a full defense system. So it did not work. We see this as common sense by now. But we do not seem to recognize the same goes for today's large pre-train models... However large amount of knowledge it stores, it is merely a fragment of an intelligent system. Strictly speaking, knowledge does not generalize, only the ability to improve knowledge does, which we call Intelligence.
English
@DeryaTR_ AI is still nowhere near having the agency of a domestic cat, and it will replace doctors.
English

Gates is correct: within a decade, up to 80-90% of doctors, teachers, professors, engineers or lawyers will be replaced by AI. The remaining professionals will focus on aiding AI to make discoveries, create new knowledge & to keep it aligned to benefit humans in these fields.
unusual_whales@unusual_whales
Bill Gates says AI will replace doctors and teachers in 10 years
English

NEW 🧵: Is human intelligence starting to decline?
Recent results from major international tests show that the average person’s capacity to process information, use reasoning and solve novel problems has been falling since around the mid 2010s.
What should we make of this?

English
@ProfBuehlerMIT very interesting work, exciting to see graph reasoning as a paradigm
English

We trained a graph-native AI, then let it reason for days, forming a dynamic relational world model on its own - no pre-programming. Emergent hubs, small-world properties, modularity, & scale-free structures arose naturally. The model then exploited compositional reasoning & uncovered uncoded properties from deep synthesis: Materials with memory, microbial repair, self-evolving systems. Video shows it unfolding, made with @grok @xai.
English
@karpathy It only works with discretized outputs (discrete symbols) and only makes sense with symbol sequences with a natural order (not images).
Text, DNA, proteins, musical scores, etc. are discrete or easily discretized.
English
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
Actually, as the LLM stack becomes more and more mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem is fixed at that of "next token prediction" with an LLM, it's just the usage/meaning of the tokens that changes per domain.
If that is the case, it's also possible that deep learning frameworks (e.g. PyTorch and friends) are way too general for what most problems want to look like over time. What's up with thousands of ops and layers that you can reconfigure arbitrarily if 80% of problems just want to use an LLM?
I don't think this is true but I think it's half true.
English

When every high-level military guy who worked for Trump publicly denounces him, it's a strong signal that you should not support Trump.
Republicans against Trump@RpsAgainstTrump
Mark Milley, James Mattis, and John Kelly should speak out publicly about the danger of a second Trump term Retweet if you agree!
English
@elonmusk nothing in economy works incredible well for all..
English

@LPitsoulis Um... I did say the Age of AI, not the Age of genAI ;)
Turns out there's a lot of useful knowledge just hidden behind "combinatorial problems".
AI has helped in chemistry, physics and biology already. You can find it all online ;)
English
We are entering the Age of AI.
History does not repeat itself but it rhymes and this era combines aspects of the renaissance, enlightenment and the industrial revolution.
We have collectively never had so much access to knowledge. AI is making it more digestible with amazing answers and summarization. Despite its many problems, academia has never had as many bright minds doing research. AI will supercharge science and most other knowledge and research endeavors. There have never been so many artists exploring the human condition from so many angles. AI will enable anybody with an idea to share that idea in an artistic form. The speed of art will accelerate. We are overall going to be A LOT more productive and efficient in our work.
What will maybe be most distinctly different is that we will have a lot more people in total and percentage-wise with lives where most any of the basic human needs are fulfilled almost all the time. There's a certain kind of simplicity in struggle but complexity in success. You have to figure out what comes after that success. What will be our new collectively structured pursuit of wisdom, togetherness, belonging, grounding, meaning, or purpose?
Of course, we're also sitting on top of the advances of recent eras of steam, electricity, computer and internet and if you want to be pessimistic... maybe add some sprinkles of the middle ages.
As is always the case, the future (and any era) might already be here but not equally distributed. We're also for the first time acutely aware of all the places on earth that are struggling with war, famine and other catastrophes made by humans or nature. It creates even more pressure on our moral frameworks and how we define our in-group vs out-group, how we merge empathy with utilitarian effective altruism.
One thing is clear, if you were born from a random sample of all humans on earth, now is likely the most interesting time and your best shot to live a long life.
#randomWednesdayNightMusings
English